

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Horizontal and Vertical Partitioning in Databases
Last updated: June 29, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
Databases play a crucial role in modern applications, storing and managing vast amounts of data efficiently. In the same context, horizontal and vertical partitioning are two common techniques used for managing data in databases.
In this tutorial, we’ll delve into the differences between these two approaches.
2. The Role of Partitioning
Partitioning is indispensable for modern databases, particularly in the face of big data, cloud computing, and real-time applications. As data volumes burgeon exponentially, partitioning offers a crucial solution by distributing data across multiple servers or nodes, thereby facilitating horizontal scalability and alleviating performance bottlenecks.
Besides, this approach not only optimizes query performance by spreading the workload but also enhances resource utilization and cost-effectiveness in cloud environments. Partitioning also ensures high availability and responsiveness for real-time applications, mitigating the risk of single points of failure and enabling parallel data processing.
In essence, partitioning stands as a cornerstone strategy for modern database management, empowering organizations to effectively manage data growth, achieve scalability, and meet the demanding requirements of today’s data-driven landscape.
3. Horizontal Partitioning
Also referred to as sharding, this technique involves dividing a database table into multiple partitions based on rows, with each partition containing a subset of the rows from the original table.
Let’s suppose we have a bustling e-commerce platform that manages a vast array of products as follows:
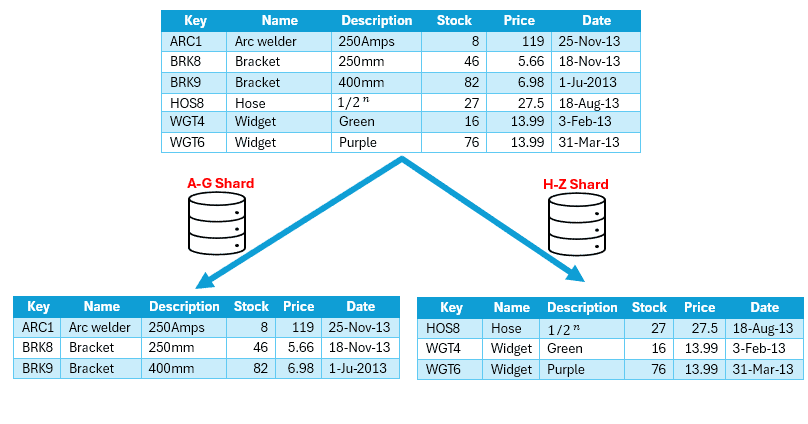
In this approach, the product inventory data is split into shards based on the product key. Imagine organizing the products into neat little groups alphabetically. Moreover, each shard takes care of a specific chunk of products, like those from A to G or H to Z.
This smart sharding technique spreads the workload across multiple computers, easing the strain and boosting performance exponentially.
4. Vertical Partitioning
Vertical partitioning involves splitting a database table into multiple partitions based on columns. Besides, each partition contains a subset of the columns from the original table.
Let’s switch gears and consider employing vertical partitioning for our product inventory scenario. This method entails dividing our database table into multiple partitions, not by rows this time but by columns, as follows:
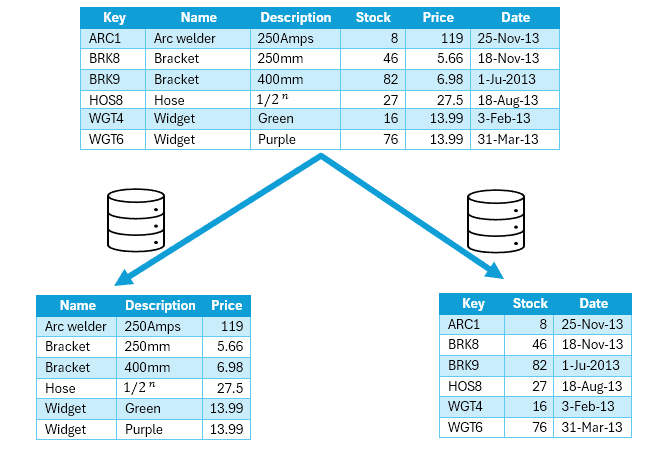
In this example, different properties of an item are stored in different partitions. One partition holds data that is accessed more frequently, including product name, description, and price. Another partition holds inventory data: the stock count and last-ordered date.
This technique is useful for optimizing query performance by reducing the amount of data retrieved for each query.
5. Key Differences
The following table provides a clear comparison between horizontal and vertical partitioning in terms of data distribution, scalability, query performance, and their respective use cases:
| Key Differences | Horizontal Partitioning | Vertical Partitioning |
|---|---|---|
| Data Distribution | Distributes data across multiple partitions based on rows | Divides data based on columns, grouping related columns together |
| Scalability | Facilitates scalability by distributing data across multiple servers or nodes | It can improve scalability by reducing the size of each partition, making queries more efficient |
| Query Performance | Can improve query performance by distributing the workload across multiple nodes | Improves query performance by reducing the amount of data retrieved for each query |
| Use Cases | Suitable for applications with large datasets that need to be distributed across multiple servers | It is beneficial for optimizing query performance by reducing the number of columns retrieved |
6. Tools and Frameworks
Various tools and frameworks support partitioning in database management systems (DBMS). Proprietary solutions like Oracle and SQL Server offer robust features for partitioning, allowing users to partition tables based on criteria such as range, list, or hash.
Moreover, open-source databases like MySQL and PostgreSQL provide partitioning capabilities through features like table inheritance and declarative partitioning. NoSQL databases, such as MongoDB, offer sharding mechanisms for horizontal partitioning across clusters. Additionally, cloud-based platforms like Amazon Aurora and Google Cloud Spanner integrate partitioning into their scalable architectures.
These options cater to diverse needs, enabling efficient management and scalability of databases.
7. Conclusion
In summary, horizontal partitioning distributes data by rows, while vertical partitioning divides it by columns. By employing the appropriate strategy, organizations can effectively manage and scale their databases for modern data-driven applications.