

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll describe how we can calculate the output size of a convolutional layer. First, we’ll briefly introduce the convolution operator and the convolutional layer. Then, we’ll move on to the general formula for computing the output size and provide a detailed example.
Generally, convolution is a mathematical operation on two functions where two sources of information are combined to generate an output function. It is used in a wide range of applications, including signal processing, computer vision, physics, and differential equations. While there are many types of convolutions like continuous, circular, and discrete, we’ll focus on the latter since, in a convolutional layer, we deal with discrete data.
In computer vision, convolution is performed between an image  and a filter
and a filter  that is defined as a small matrix. First, the filter passes successively through every pixel of the 2D input image. In each step, we perform an elementwise multiplication between the pixels of the filter and the corresponding pixels of the image. Then, we sum up the results into a single output pixel. After repeating this procedure for every pixel, we end up with a 2D output matrix of features.
that is defined as a small matrix. First, the filter passes successively through every pixel of the 2D input image. In each step, we perform an elementwise multiplication between the pixels of the filter and the corresponding pixels of the image. Then, we sum up the results into a single output pixel. After repeating this procedure for every pixel, we end up with a 2D output matrix of features.
Now let’s describe the above procedure again using a simple example. We have a  image
image  and a
and a  filter
filter  that we want to convolve. Below, we can see in bold which pixels of the input image are used in each step of the convolution:
that we want to convolve. Below, we can see in bold which pixels of the input image are used in each step of the convolution:
As mentioned earlier, in each step, we multiply the values of the selected pixels (in bold) with the corresponding values of the filter, and we sum the results to a single output. In the example below, we compute the convolution in the central pixel (step=5):
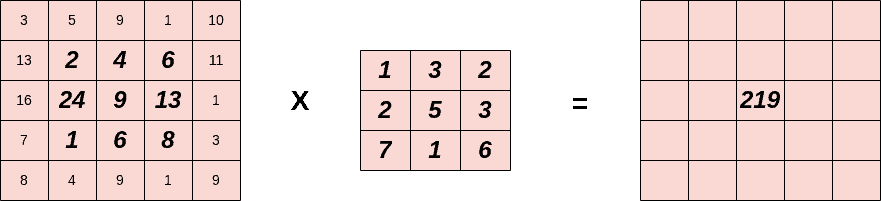
First, we compute the multiplications of each pixel of the filter with the corresponding pixel of the image. Then, we sum all the products:

So, the central pixel of the output activation map is equal to 129. This procedure is followed for every pixel of the input image.
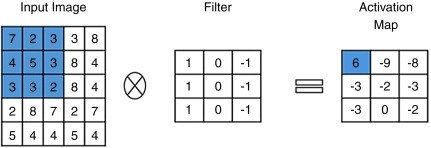
The convolutional layer is the core building block of every Convolutional Neural Network. In each layer, we have a set of learnable filters. We convolve the input with each filter during forward propagation, producing an output activation map of that filter. As a result, the network learns activated filters when specific features appear in the input image. Below, we can see an example with the Prewitt operator, a clear filter used for edge detection:
To formulate a way to compute the output size of a convolutional layer, we should first discuss two critical hyperparameters.
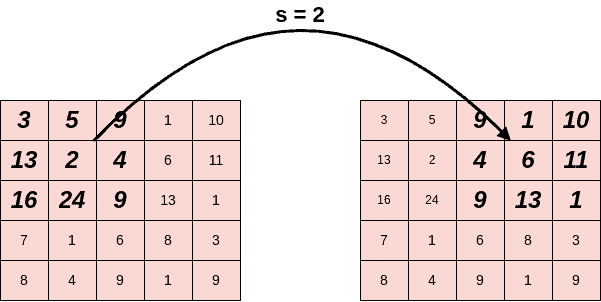
During convolution, the filter slides from left to right and from top to bottom until it passes through the entire input image. We define stride  as the step of the filter. So, when we want to downsample the input image and end up with a smaller output, we set
as the step of the filter. So, when we want to downsample the input image and end up with a smaller output, we set  .
.
Below, we can see our previous example when  :
:
In a convolutional layer, we observe that the pixels located on the corners and the edges are used much less than those in the middle. For example, in the below example, we have a input image and a filter:
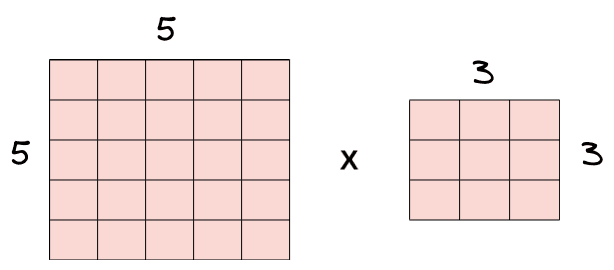
Below we can see the times that each pixel from the input image is used when applying convolution with  :
:
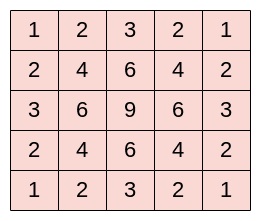
We can see that the pixel  is used only once while the central pixel
is used only once while the central pixel  is used nine times. In general, pixels located in the middle are used more often than pixels on edges and corners. Therefore, the information on the borders of images is not preserved as well as the information in the middle.
is used nine times. In general, pixels located in the middle are used more often than pixels on edges and corners. Therefore, the information on the borders of images is not preserved as well as the information in the middle.
A simple and powerful solution to this problem is padding, which adds rows and columns of zeros to the input image. If we apply padding  in an input image of size
in an input image of size  , the output image has dimensions
, the output image has dimensions  .
.
Below we can see an example image before and after padding with  . As we can see, the dimensions increased from to
. As we can see, the dimensions increased from to  :
:
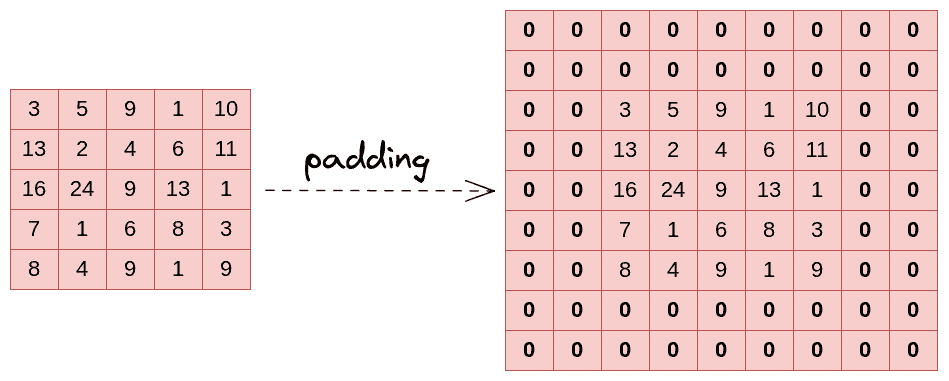
By using padding in a convolutional layer, we increase the contribution of pixels at the corners and the edges to the learning procedure.
Now let’s move on to the main goal of this tutorial which is to present the formula for computing the output size of a convolutional layer. We have the following input:
 .
. .
. and padding .
and padding .The output activation map will have the following dimensions:


If the output dimensions are not integers, it means that we haven’t set the stride correctly.
We have two exceptional cases:
 .
. and
and  . If s=1, we set
. If s=1, we set  .
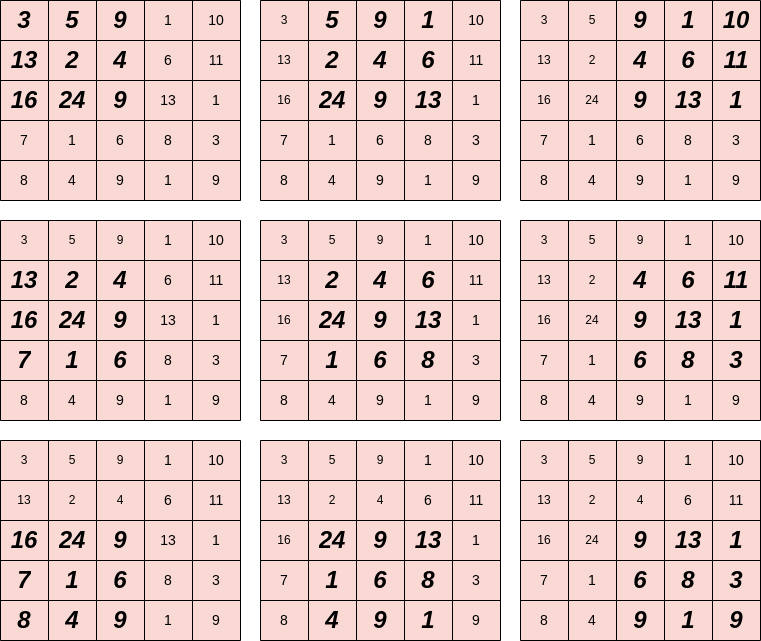
.Finally, we’ll present an example of computing the output size of a convolutional layer. Let’s suppose that we have an input image of size  , a filter of size , padding P=2 and stride S=2. Then the output dimensions are the following:
, a filter of size , padding P=2 and stride S=2. Then the output dimensions are the following:


So,the output activation map will have dimensions  .
.
In this tutorial, we talked about computing the outputs size of a convolutional layer.