

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Mathematics is everywhere in the Machine Learning field: input and output data are mathematical entities, as well as the algorithms to learn and predict.
But what happens when we need to deal with linguistic entities such as words? How can we model them as mathematical representations? The answer is we convert them to vectors!
In this tutorial, we’ll learn the main techniques to represent words as vectors and the pros and cons of each method, so we know when to apply them in real life.
This technique consists of having a vector where each column corresponds to a word in the vocabulary.
Let’s see an example with these sentences:
(1) John likes to watch movies. Mary likes movies too. (2) Mary also likes to watch football games.
This would be our vocabulary:
So we will have this vector, where each column corresponds to a word in the vocabulary:

Each word will have a value of 1 for its own column and a value of 0 for all the other columns.
The vector for the word “likes” would be:

Whereas the vector for “watch” would be:
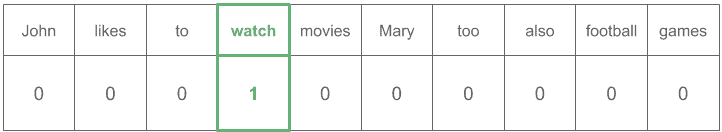
There are different ways to create vocabularies, depending on the nature of the problem. This is an important decision to make because it’ll affect the performance and speed of our system.
In the next sections, we’ll review different methods to create that vocabulary.
Stop words are those we ignore because they are not relevant to our problem. Typically we’ll remove the most common ones in the language: “the”, “in”, “a” and so on.
This helps to obtain a smaller vocabulary and represent words with fewer dimensions.
A popular and useful technique is reducing the explosion of inflectional forms (verbs in different tenses, gender inflections, etc.) to a common word preserving the essential meaning. The main benefits of using this technique are:
There are two main specific techniques to achieve this: Stemming and Lemmatization.
Stemming is the process of truncating words to a common root named “stem”.
Let’s see a stemming example in which the stem is still a real word in the language (“Connect”):

Now we’ll see a case with a stem out not being a word (“Amus”):

Lemmatization consists of reducing words to their canonical, dictionary, or citation form named “lemma”.
See next a case of lemmatization in which words with inflection share the root with the lemma (“Play”):

Finally, we’ll see an example of a lemma (“Go”) not sharing the root with the words with inflection:

Lowercasing the vocabulary is usually a good way to significantly reduce it without meaning loss.
However, if uppercased words are relevant to the problem, we shouldn’t use this optimization.
The most common strategies to deal with Out Of Vocabulary (OOV) words are:
The drawbacks are:
The advantages are:
Word embeddings are just vectors of real numbers representing words.
They usually capture word context, semantic similarity, and relationship with other words.
One of the coolest things about word embeddings is that we can apply semantic arithmetic to them.
Let’s have a look at the relationships between word embedding vectors:
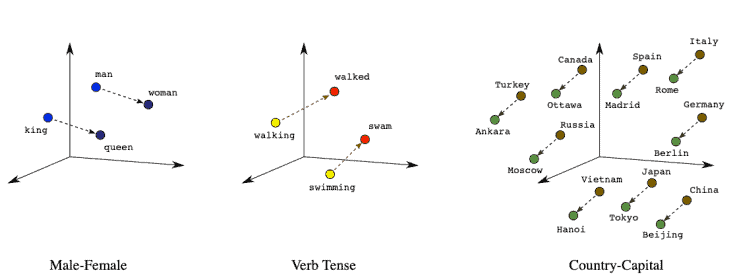
We can notice in the Male-Female graph, the distance between “king” and “man” is very similar to the distance between “queen” and “woman”. That difference would correspond to the concept of “royalty”:
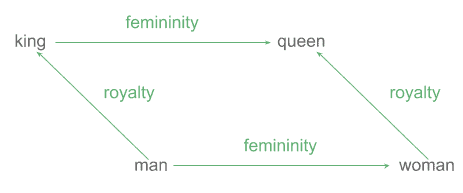
We could even approximate the vector for “king” applying these operations:


This ability to express arithmetically and geometrically semantic concepts is what makes word embeddings especially useful in Machine Learning.
Word embeddings drawbacks are:
Their advantages are:
Let’s now learn one of the most popular techniques to create word embeddings: Word2vec.
The key concept to understand how it works is the distributional hypothesis in linguistics: “words that are used and occur in the same contexts tend to purport similar meanings“.
There are two methods in Word2vec to find a vector representing a word:
The architecture is a very simple shallow neural network with three layers: input (one-hot vector), hidden (with N units of our choice), and output (one-hot vector).
The training will minimize the difference between the expected output vectors and the predicted ones, leaving as a side-product the embeddings in a weights matrix (in red):
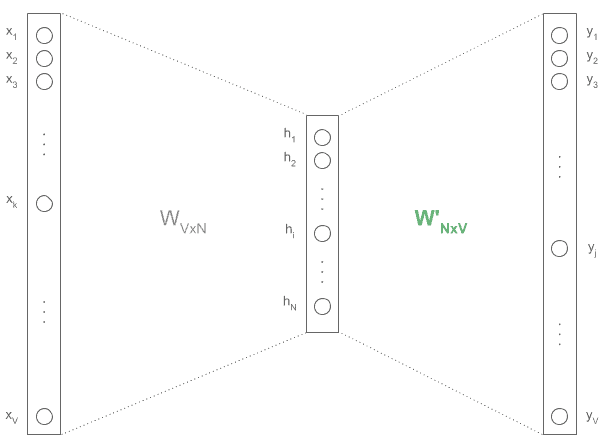
So we’ll have two weight matrices: Matrix  between the input and hidden layer, and Matrix
between the input and hidden layer, and Matrix  between the hidden and output layer.
between the hidden and output layer.
After training, the matrix with size  will have one column per word, which are the embeddings for each word.
will have one column per word, which are the embeddings for each word.
The whole concept of CBOW is that we know the context of a word (the surrounding words), and our goal is to predict that word.
For example, imagine we train with the former text:
John likes to watch movies. Mary likes movies too.
and we decide to use a window of 3 (meaning we’ll pick one word before the target word and one word after it).
These are the training examples we’d use:
John ____ to (Expected word: "likes") likes ____ watch (Expected word: "to") to ____ movies (Expected word: "watch") ...
all encoded as one-hot vectors:
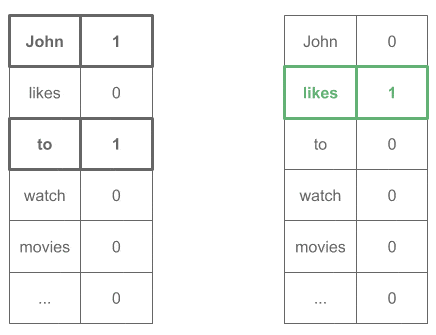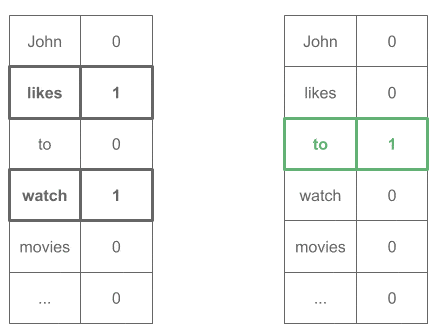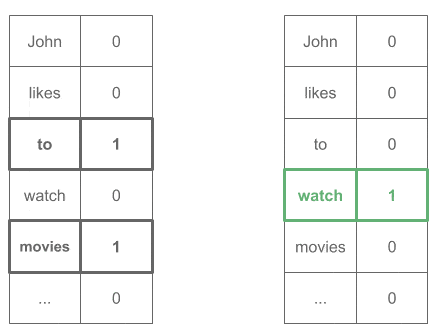
Then we would train this network as any other neural classifier, and we would obtain our word embeddings in the weights matrix.
The only difference in this approach is that we’d use the word as input and the context (surrounding words) as output (predictions).
Therefore, we’d generate these examples:
"likes" (Expected context: ["John", "to"]) "to" (Expected context: ["likes", "watch"]) "watch" (Expected context: ["to", "movies"]) ...
Which expressed as one-hot vectors would look like:
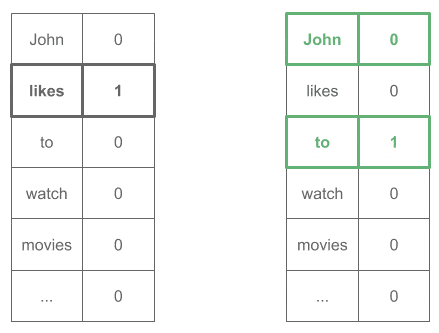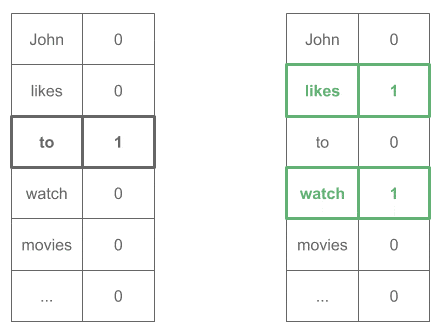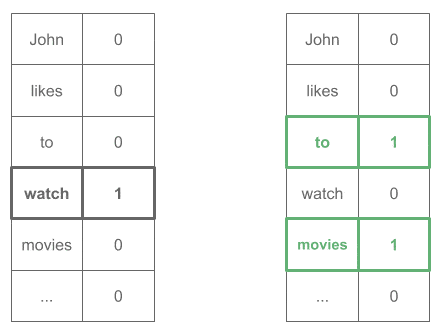
GloVe embeddings relate to the probabilities that two words appear together. Or simply put: embeddings are similar when their words appear together often.
Pros:
Cons:
fastText is an extension of Word2vec consisting of using n-grams of characters instead of whole words.
Pros:
Cons:
ELMo solves the problem of having a word with different meanings depending on the sentence.
Consider the semantic difference of the word “cell” in: “He went to the prison cell with his phone” and “He went to extract blood cell samples”.
Pros:
Cons:
There are a few additional techniques that aren’t as popular:
In this tutorial, we learned the two main approaches to generate vectors from words: one-hot vectors and word embeddings, as well as the main techniques to implement them.
We also considered the pros and cons of those techniques, so now we are ready to apply them wisely in real life.

