

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this article, we’ll talk about stemming and lemmatization, two techniques widely used in Natural Language Processing and Information Retrieval. Although they can serve similar purposes, they have their unique pros and cons, and we’re going to see when it’s best to use one or the other.
Both stemming and lemmatization are word normalization techniques. They are very often used when implementing search engines to handle variations of the same word properly.
For example, if a user is searching for “dog foods”, we most likely want to retrieve results that mention the singular word “food” as well, meaning that we need to normalize the plural form of “foods” to “food”. Similarly, we want to handle similar variations for verbs and adjectives.
This is where stemming or lemmatization comes in handy.
Stemming is a straightforward normalization technique, most often implemented as a series of rules that are progressively applied to a word to produce a normalized form.
These rules vary from language to language, and they reflect the morphological structure of the language at hand. For example, for English, a possible rule could be to remove the “s” at the end of a word to transform it into its singular form.
One important thing to keep in mind about stemming is that it’s not required that the normalized word be valid, but only that variations of the same word map to the same stem.
We can see this phenomenon in action by experimenting with the Porter stemmer, a widely used stemming algorithm for English. Using it on the words “engine” or “engines”, will result in “engin”. Although this is not a valid English word, we only care that both words map to the same stem.
Although it may seem counter-intuitive at first, this doesn’t represent a problem. Stemming is mostly used to index documents in a search engine, so these stems, which may be non-valid words, are only processed internally to search documents and are never displayed to the user.
We can think of lemmatization as a more sophisticated version of stemming. It reduces each word to its proper base form, that is, a word that we can find in a dictionary.
To do this, lemmatization algorithms depend on the availability of part-of-speech information on the input words because different normalization rules might need to be applied whether the word is a noun, verb, adjective, or other.
As an example, let’s consider the word “following”. According to the context, this can either be a noun (e.g., “he has a huge following”), a verb (e.g., “he started following the rabbit”) or an adjective (e.g., “the following day”). If it’s an adjective or verb, lemmatization will return “following”, while if it’s a verb it will return “follow”. A stemming algorithm won’t be aware of this, and will remove the “ing” suffix to return “follow” in all cases.
Search engines can use lemmatization to index documents in a similar fashion to stemming. However, given its higher accuracy, it’s used in a variety of NLP tasks where having valid words is a must, for example, Word Sense Disambiguation.
Here’s the difference between stemming and lemmatization on a real English sentence:
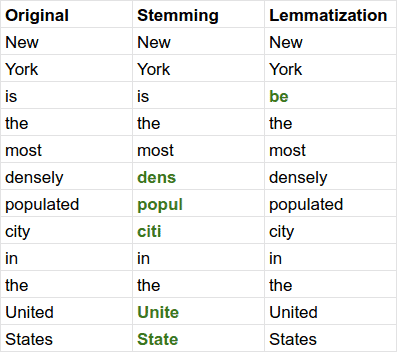
Whether to use stemming or lemmatization heavily depends on our specific requirements.
In general, the advantages of stemming are that it’s straightforward to implement and fast to run. The trade-off here is that the output might contain inaccuracies, although they may be irrelevant for some tasks, like text indexing.
Instead, lemmatization provides better results by performing an analysis that depends on the word’s part-of-speech and producing real, dictionary words. As a result, lemmatization is harder to implement and slower compared to stemming.
To sum up, lemmatization is almost always a better choice from a qualitative point of view. With today’s computational resources, running lemmatization algorithms shouldn’t have a significant impact on the overall performance. However, if we are heavily optimizing for speed, a simpler stemming algorithm can be a possibility.
In this article, we’ve seen an overview of stemming and lemmatization, and we’ve examined their differences, pros, and cons to understand how to choose between the two of them.