

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Compiled vs. Interpreted Programming Languages
Last updated: October 16, 2025
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this tutorial, we’ll present the difference between compiled and interpreted programming languages.
2. Why Do We Need Compilers and Interpreters?
Computers can understand and run only binary code. Programmers use high–level programming languages, such as C, Python, or Java. Those languages are easier to work with since they resemble human languages and mathematical notation. However, computers cannot run the code written in a high–level language. We first have to translate it into binary code. To do so, we use compilers and interpreters.
Languages whose programs we usually compile are called compiled languages. Similarly, those we usually interpret are called interpreted languages.
3. Compilers
Compilers take a whole program as input and translate it to an executable binary code in several steps.
We can run the binary code only on the machine on which we compiled it. That’s because the binary code depends on the hardware and is not portable.
The compilation step is required only once. Afterward, we can run the binary code as many times as we want.
Because compilers process whole programs, they can catch some errors and warn us to correct them. Those are syntax and type errors. Compilation fails if they are present.
C is an example of a compiled language.
4. Interpreters
Interpreters read and execute the program at hand instruction by instruction. After being read, each instruction is translated into the machine’s binary code and run.
Unlike compilers, the interpreters do not produce a binary executable file. Each time we run a program, we invoke the interpreter. It then reads and executes the program one instruction at a time.
That’s why it must be present in the computer’s RAM whenever we run a program. In contrast to interpreters, we need compilers only during compilation.
On the other hand, unlike the compilers, the interpreters catch all the errors at runtime.
Python is an example of an interpreted language.
5. Example of Compilation and Interpretation
Imagine a code in an unnamed language:
a := 1;
b := 2;
c := a + b;
print(c);A compiler would translate it to the binary code, which we can run later:
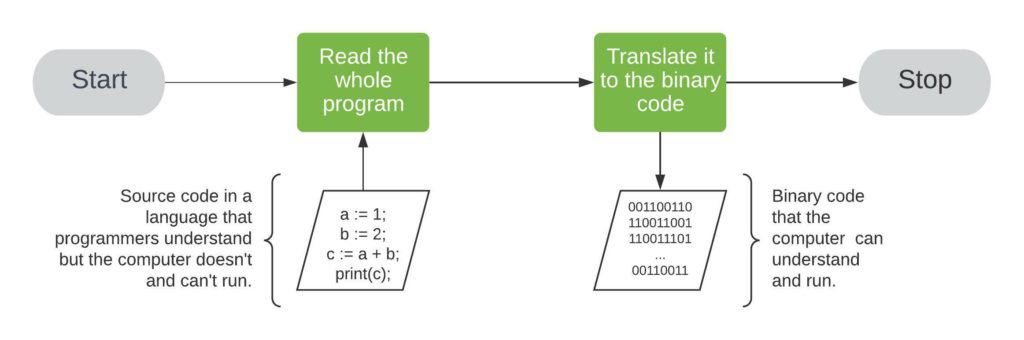
All those binary instructions are the commands for the computer at hand. They instruct it to set the appropriate CPU register to 1. Afterward, they choose a free address in RAM to write the register’s content. That is how a compiler translates a := 1; to the binary code. Other binary instructions are translations of the rest of the code to the machine’s binary language.
Once we run the binary code, it gets loaded into RAM, and the CPUs execute it.
On the other hand, an interpreter would first read the instruction a := 1;. It would load it into the computer’s RAM, translate it into binary code and let the CPU(s) execute it. Then, the interpreter would do the same with instruction b := 2;. After the second instruction, it would move on to the third, and finally, to the last one:
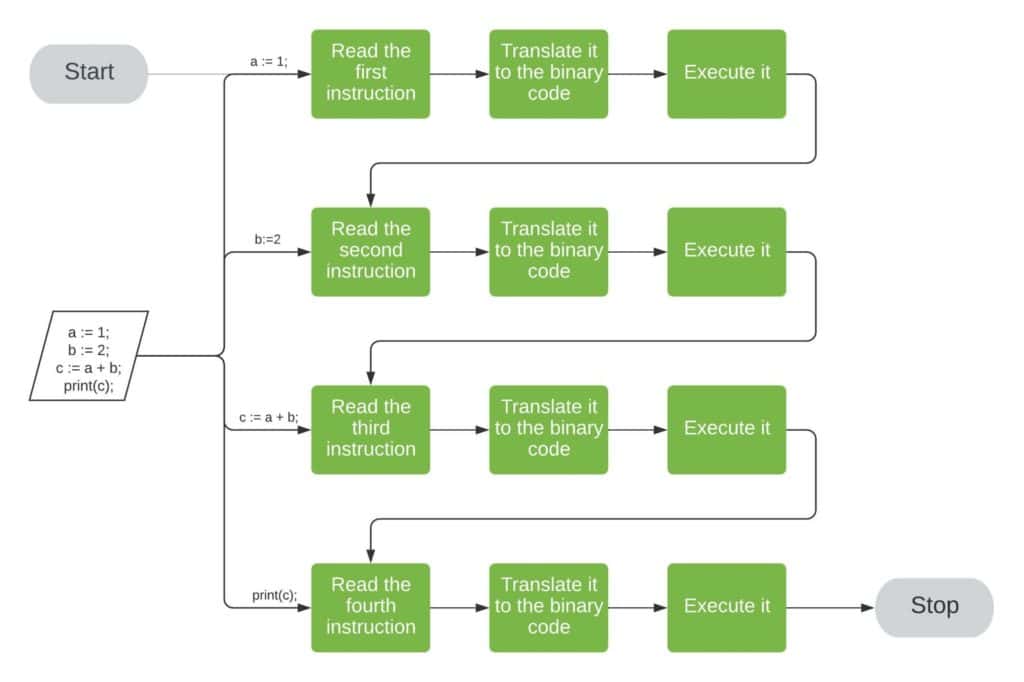
So, we see that translation and execution are separated if we use compilers. However, they are intertwined if we interpret our programs. That’s why interpretation is usually slower than running compiled programs.
6. Differences
Let’s sum up the differences between compilers and interpreters:
| Compiler | Interpreter |
|---|---|
| Processes whole programs at once | Processes programs one instruction at a time |
| Translates programs to binary machine code | Executes programs by loading and translating instructions one by one on the fly |
| Needed only once after the program is completed | Runs each time the program is executed |
| Allows for detection of some errors prior to execution | All the errors are caught during execution |
| Need not be present in RAM during execution | Must be in RAM during a program’s execution |
| Compiled programs usually run faster | Interpreted programs are usually slower |
Note that we usually think of programming languages as either compiled or interpreted. Still, we can make interpreters for C just as we can create compilers for Python.
Furthermore, some languages mix both concepts. For example, we first compile Java programs to bytecode, the code of Java Virtual Machine. Afterward, we interpret the bytecode.
7. Conclusion
In this article, we talked about executing programs after compilation or during interpretation. We also talked about the differences between those two ways of execution.