

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Does Code Obfuscation Bring Security Benefits?
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In computer science, obfuscation is a technique to hide implementation details. It is the obscuring of the intended meaning of things. So, Code Obfuscation is anything employed to make code, or its compiled objects, harder to read and understand.
And why would anyone want that?
Well, there are some who advocate security through obscurity. Their argument: as the cost of exploiting gets higher, it will discourage some. Even though this may sound reasonable, in practice we’ve seen it’s not so. Perhaps less skilled attackers may face harder times, but we’re seeing increasingly skilled criminals nowadays. But the point is to increase the costs of an attack.
Of course, for better maintainability, the easier the code is understood, the better. Simpler coding makes simplify adding new coders to the team. Also, it makes it easier to spot and fix bugs or add new functions.
Hence, in companies that use this technique, the code obfuscation is usually done at the production release build stream. Automated tools analyze and obfuscate the source code or the resulting byte-code objects.
However, some might obfuscate manually critical functions in the source code directly. In this case, the logic is over-engineered so that the resulting object creates complex objects.
2. Code Obfuscation Use-cases
Obfuscation can be applied in the source code itself, or in the compiled objects. The latter being the most usual. In general, people have been using code obfuscation in these cases:
- Trade secret projection: the key algorithms would be harder to find, extract and reverse engineer
- Prevention of circumvention: as the software is harder to analyze, abusing it would take more effort
- Reduce loading times: removing debugging data, comments, non-needed characters (spaces, newlines, etc), and reducing object names. Also, many can remove non-used library calls, greatly reducing the built package footprint. This is done by specific obfuscation tools called minimizers. One of the more famous is WebPack, used in many Javascript frameworks like ReactJs and VueJs. The resulting app should have fewer and smaller assets, thus reducing loading latency
On the other hand, as a security measure, it is not considered effective protection. There are even automated tools that simplify the reverse engineering of obfuscated code. By the way, as a matter of fact, we must never rely on security through obscurity alone.
Besides not being as effective as protection, other issues arise: stack traces from defects are harder to analyze. Also, it adds complexity to the build process.
3. Reverse Engineering
Before reviewing how obfuscation works, let’s talk a little about what it tries to avoid. Reverse-engineering is the process of analyzing a product its architecture and functions. In software, it can go as far as recreating a working similar source code. That means, it can make it possible to modify and rebuild a similar system.
That is the same kind of procedure that is used to analyze malware or to find ways to reverse ransomware cryptographic challenges.
There are diverse approaches to reverse engineering software. We can use static analysis to translate the binary or byte-code objects into a readable form.
The results can be in assembly language (very hard to read) or, depending on the framework used, in the original language. For instance, Java JVM or .Net CLR byte-code objects can be easily translated back to their original languages, Java and C#.
The dynamic reverse-engineer approach analyses (or simulates) the program execution, observing its system calls, inputs, and outputs. It can trace the software’s interaction with other systems and the external world. Current decompiler tools can use both approaches to achieve better results.
4. Obfuscation Example
Let’s see a little example taking this very simple java class. This sample used the following tools:
- Proguard, an open-source byte-code Java obfuscator, and optimizer. It works by analyzing the application’s byte-code objects. It can be easily integrated into the building pipeline.
- Jad. This is an open-source java decompiler. It reverses the JVM byte code back into Java code. Even though it is quite old, it is still usable and reliable.
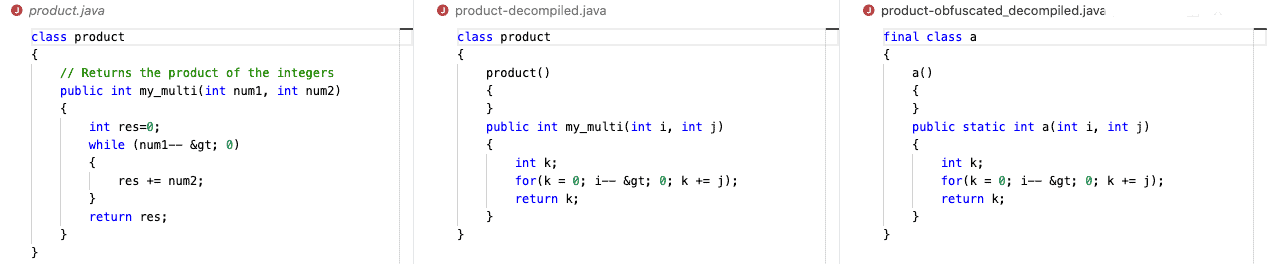
As we can see, in the reverse-engineered code, the class name was preserved, while variable names and comments were lost. The while loop was optimized by the java compiler into a simpler for loop. We can also note an empty instantiator method, added during compilation.
In the obfuscated version the class was made final, and its name was lost. The obfuscator can be configured to generate long, complex, class names. Additionally, it can reutilize names in different scopes and signatures (polymorphism). That can make it harder to figure out. The code is still readable, however, in complex applications, sorting out what each class, method, and variable stands for can be quite time-consuming.
5. Is There Any Actual Security Benefit?
In byte-code-based frameworks, e.g, Java or .Net, most modern decompiling tools can help to map class and variable names to something readable. That means, that once you name a class or variable, it refactor the code accordingly. Also, they can map so that future decompilations will take advantage of it.
While obfuscation does indeed makes reversing harder, it’s not able to prevent it. So, we can say that its security benefits are not as effective.
Some have tried going beyond obfuscation by encrypting the software itself. However, to run, it must be decrypted on the runtime. So, attackers first reverse-engineer the decryption routines or take a snapshot of the in-memory decrypted software.
6. Conclusion
In this tutorial, we`ve seen how obfuscation works and how this technique applies to Java. We also discussed how it affects reverse engineering and if there is any tangible security benefit.
Even though some may think code obfuscation shall improve security, it is not so. Software engineering is time-consuming in any case. And, given incentive enough, it would, most likely, not deter malicious parties’ attempts.
Of course compiled languages, that generate machine code, are much harder to reverse-engineer. C++, for instance. In that case, we should use a disassembler, such as IDA. As a result, the resulting code should be much harder to analyze and very long. Small C++ routines can easily lead to a hundred-page assembly language listing.