

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this article, we’ll discuss the problem of validating a binary search tree. After explaining what the problem is, we’ll see a few algorithms for solving it. Then we’ll see the pseudocode for these algorithms as well as a brief complexity analysis.
2. Problem Explanation
We’re given as input a binary tree and would like to determine whether it’s a valid binary search tree. In other words, we’ll need to check four things:
- Is every node value in the root’s left subtree less than the root’s value?
- Is every node value in the root’s right subtree greater than the root’s value?
- Is the root’s left subtree also a binary search tree?
- Is the root’s right subtree also of a binary search tree?
If these four conditions are met, then we can be sure that the binary tree is a binary search tree. For example, this tree is a binary search tree since the conditions are met:
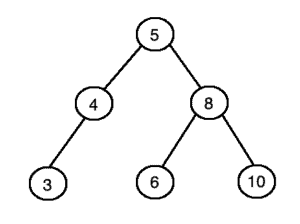
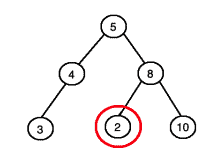
Whereas this tree is not a binary search tree since we have a node value (circled in red) in the right subtree of the root which is less than the root’s value:
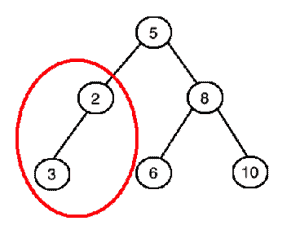
Finally, this tree is not a binary search tree because the left subtree of the root (circled in red) is not a binary search tree:
3. Algorithms
3.1. Naive Approach
An extremely naive approach would be to traverse the tree and check at each node whether the left child’s value is smaller and the right child’s value is bigger. This approach is wrong because it’ll only work on certain trees, not all trees.
A correct naive method (which is suggested by the conditions in the previous section) is this:
- If the tree is a single node, return true
- Traverse every node in the left subtree, checking whether each value is smaller than the root’s value
- Traverse every node in the right subtree, checking whether each value is larger than the root’s value
- If we found a node in the left subtree whose value is bigger than the root’s or a node in the right subtree whose value is smaller than the root’s, then return false
- Recursively check whether both the left and right subtrees of the root are also binary search trees and if yes then return true
3.2. Efficient Method Using Upper and Lower Limits
The previous algorithm is too slow and we can do better. One possibility is to keep track of upper and lower limits for each node as we traverse the tree. At each node, we’ll check whether that node’s value falls within the current limits.
Whenever we recurse on a left subtree we’ll use the current node’s value as the new upper limit and keep the original lower limit. If we recurse on a right subtree, we’ll use the current node’s value as the lower limit and keep the original upper limit. The inputs to the algorithm are  (we’ll begin with the root),
(we’ll begin with the root),  , and
, and  .
.
So, let’s outline this in detail:
- If equals
 , return
, return 
- If does not equal and the value at is less than or equal to , return

- If does not equal and the value at is greater than or equal to , return
- Recursively check that the left subtree of is a binary search tree, with the value of as the upper limit and as the lower limit. If the left subtree is not a binary search tree then return .
- Recursively check that the right subtree of is a binary search tree, with the value of as the lower limit and as the upper limit. If the right subtree is not a binary search tree, then return .
- Return
The above algorithm is much faster than the previous one because we only visit each node exactly once.
3.3. Efficient Method Using Inorder Traversal
There is another algorithm we can use to solve this problem. We can do an inorder traversal of the given tree, storing the node values in a list, and then checking whether the list is sorted or not.
If an inorder traversal produces a sorted order, then the tree must be a binary search tree. But why is this the case and how can we know for sure? We can answer these questions using mathematical induction.
The base case is that if we have a single node then the statement holds. Inorder traversal of a single node will always return a sorted order, and a single node will always be a binary search tree.
Now we can inductively assume that the statement holds for any left subtree and any right subtree. Using this inductive hypothesis along with the base case, we can show that the original statement holds.
If the inorder traversal of our tree returns a sorted order, then the inorder traversal of the left and right subtrees must’ve been in sorted order as well. This is because the inorder traversal will always traverse the entire left subtree, then the root, and finally the entire right subtree.
This also means that every node value in the left subtree must be smaller than the root’s value, and every node value in the right subtree must be larger than the root’s value. Also, we know inductively that both the left and right subtrees must be binary search trees, so we’re done with our proof.
This inorder traversal based method can be further improved by noticing that we do not have to store all the node values in a list. We can simply always check whether the previous element in the traversal is less than the current element.
4. Pseudocode
Here, we’ll show pseudocode for four different algorithms.
4.1. Naive Algorithm
The algorithm below is the naive approach where we first traverse the left and right subtrees and then recursively check whether the two subtrees are binary search trees:
algorithm validateBST(root):
// INPUT
// root = the root node of the binary search tree
// OUTPUT
// true if the tree is a valid binary search tree, false otherwise
if root != null:
if valid(root.left, root.val, true) and valid(root.right, root.val, false):
return validateBST(root.left) and validateBST(root.right)
else:
return false
return true
algorithm valid(root, nodeVal, lessThan):
// INPUT
// root = current node being validated
// nodeVal = value of the node against which current node is being compared
// lessThan = boolean indicating if the current node's value should be less than nodeVal
// OUTPUT
// true if subtree rooted at current node satisfies BST properties
// with respect to nodeVal and lessThan, false otherwise
if root != null:
if lessThan:
if root.val >= nodeVal:
return false
return (valid(root.left, nodeVal, lessThan) and
valid(root.right, nodeVal, lessThan))
else:
if root.val <= nodeVal:
return false
return (valid(root.left, nodeVal, lessThan)
and valid(root.right, nodeVal, lessThan))
return true
In the above code, we can see that there are two functions:  and
and  . takes as input the root node of a binary tree and returns if the given binary tree is a valid binary search tree. In the beginning, we have a condition that checks whether all the node values in the left subtree are smaller than the root’s value and all the node values in the right subtree are larger than the root’s value.
. takes as input the root node of a binary tree and returns if the given binary tree is a valid binary search tree. In the beginning, we have a condition that checks whether all the node values in the left subtree are smaller than the root’s value and all the node values in the right subtree are larger than the root’s value.
If this condition is met then we recursively check whether both the left and right subtrees are also binary search trees. Otherwise, we return . Finally, we return if the root is equal to .
The function takes as input the root node of a subtree, the value that we want to compare all the subtree values to, and a boolean variable which tells us whether the values in this subtree should be less than or greater the given value. This function iterates through every node of the given subtree and checks whether all the nodes in the subtree are less than or greater than the given value (depending on whether  is or ).
is or ).
4.2. Efficient Algorithm Using Upper and Lower Limits
Here, we’re using the idea of lower and upper limits and traverse each node exactly once:
algorithm isValidWithUpperAndLowerLimits(node, low, high):
// INPUT
// node = the current node in the BST
// low = lower limit for the current node's value
// high = upper limit for the current node's value
// OUTPUT
// true if the subtree rooted at node is a valid BST, false otherwise
if node = null:
return true
if low != null and node.val <= low:
return false
if high != null and node.val >= high:
return false
if isValid(node.right, node.value, high) = false:
return false
if isValid(node.left, low, node.value) = false:
return false
return true
This algorithm first checks whether the tree is empty. If it is, we return since an empty tree is a valid binary search tree.
Then, we have two  statements that check whether the current node’s value is within the lower and upper bounds.
statements that check whether the current node’s value is within the lower and upper bounds.
After that, two statements recursively check whether the left and right subtrees also obey the lower and upper bounds. Note that for the left subtree the new upper bound is the current node’s value, and for the right subtree the new lower bound is the current node’s value.
Finally, we return if we get past all the statements since this means the tree must be a binary search tree.
4.3. Efficient Algorithm Using Inorder Traversal
This algorithm uses an inorder traversal and stores all the node values in a list. Then it checks whether the list is sorted:
algorithm isValidInorderTraversal(root):
// INPUT
// root = root of the binary search tree
// OUTPUT
// true if the binary search tree is valid, otherwise false
list <- []
inorder(root, list)
return isSorted(list)
algorithm inorder(root, list):
if root != null:
inorder(root.left, list)
list.add(root.value)
inorder(root.right, list)
algorithm isSorted(list):
for i <- 1 to list.size() - 1:
if list[i] <= list[i-1]:
return false
return true4.4. Space-Optimized Inorder Traversal Based Algorithm
The algorithm below is an optimized version of the above algorithm in the sense that it does not use an extra list to store the values:
algorithm isValidOptimizedInorderTraversal(root):
// INPUT
// root = root of the binary search tree
// OUTPUT
// true if the binary search tree is valid, otherwise false
isValid <- [true]
prev <- [null]
inorder(root, prev, isValid)
return isValid[0]
algorithm inorder(root, prev, isValid):
if root != null:
inorder(root.left, prev, isValid)
if prev[0] != null and prev[0].value >= root.value:
isValid[0] = false
return
prev[0] = root
inorder(root.right, prev, isValid)In this last algorithm, the function  takes as input the root node, an array
takes as input the root node, an array  which stores the previous node in the traversal as its only element, and an array
which stores the previous node in the traversal as its only element, and an array  of one boolean which indicates whether the tree is valid or not.
of one boolean which indicates whether the tree is valid or not.
Initially, the boolean variable inside is set to true. If at any point in the traversal the previous node’s value is greater than or equal to the current value, then the boolean in is set to false and we quit the function by returning.
5. Complexity
The naive algorithm is the slowest of all four algorithms. Its time complexity is equal to  where n is the number of nodes in the tree.
where n is the number of nodes in the tree.
We’ll show that the naive algorithm has a worst-case time complexity of by showing an example where it is and then showing that it cannot be worse than .
What is a case when the running time is ? One possibility is if the tree happens to be a path of length  . Since we’re iterating through all the descendants of each node, the total number of times we visit some node in such a path is equal to
. Since we’re iterating through all the descendants of each node, the total number of times we visit some node in such a path is equal to  . This is because in a path of length the root node has descendants, the second node has
. This is because in a path of length the root node has descendants, the second node has  descendants, and so on.
descendants, and so on.
How do we know that the worst-case complexity of the naive algorithm cannot be worse than ?
The maximum number of descendants possible for any node is since there are  nodes in the tree. So even if every node had descendants, we would still only have
nodes in the tree. So even if every node had descendants, we would still only have  iterations in the algorithm. This is still .
iterations in the algorithm. This is still .
The algorithm which uses upper and lower limits has a time complexity of  since we visit each node exactly once.
since we visit each node exactly once.
In the inorder traversal based algorithm, we perform an inorder traversal which takes time. Then we check whether a list is sorted which also takes time. This gives us an overall time complexity of .
Finally, the space-optimized inorder traversal based algorithm has a time complexity of since we’re simply doing an inorder traversal with constant-time operations.
6. Conclusion
In this article, we have seen four different algorithms for validating a binary search tree. We have also seen pseudocode for these algorithms as well as a time complexity analysis. Our optimal solution for this problem runs in time.