

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: February 28, 2025
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll present the use of the Bellman equation in enforcing reinforcement learning.
In machine learning, we usually use traditional supervised and unsupervised methods to train the model. In addition, we can use an independent learning model called reinforcement learning. This technique allows designing a framework where we let the model understand the environment and derive the solution:
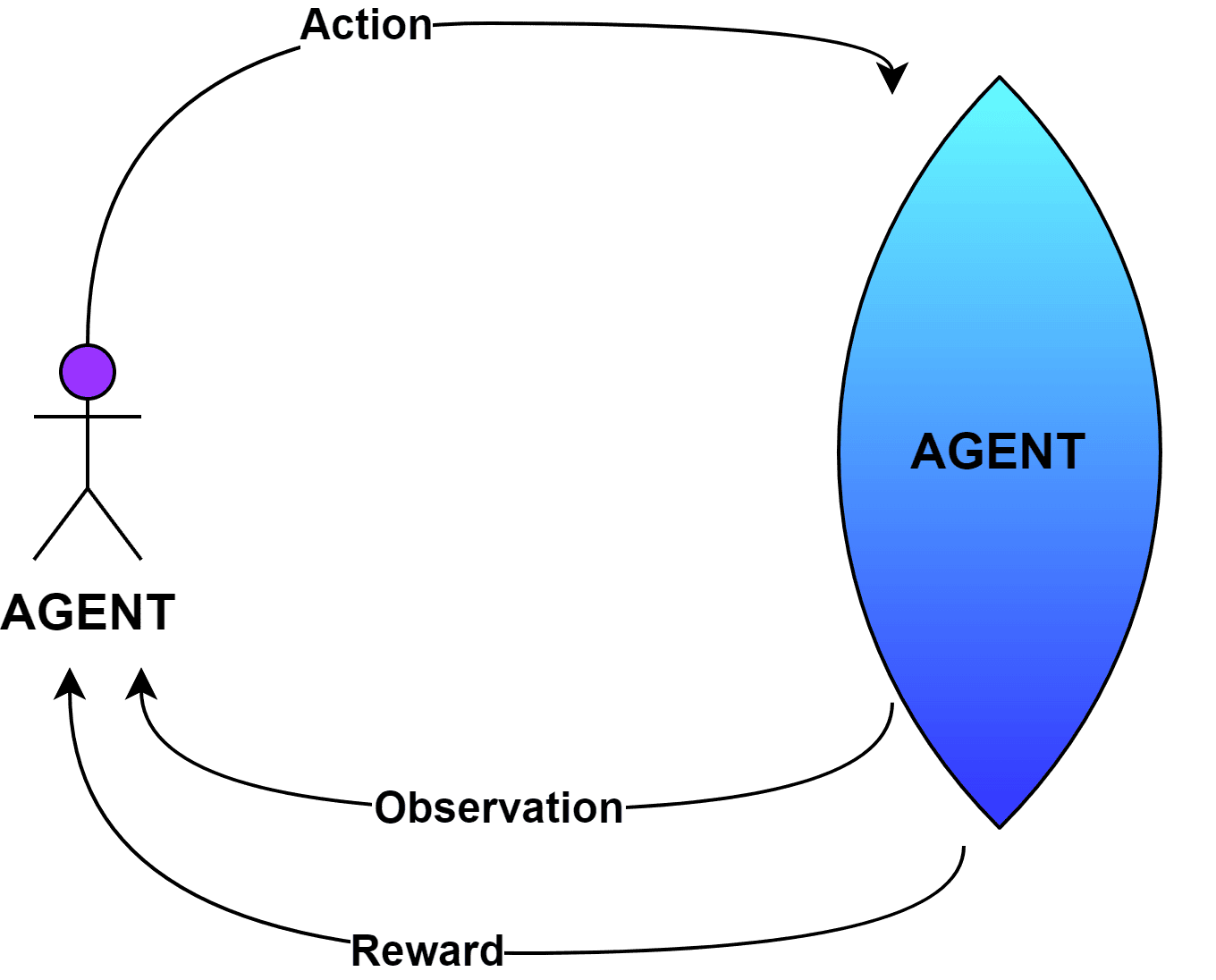 Moreover, the model works by assigning rewards for each action it takes to learn about the environment to reach the goal. The agent tries to find a target output but sometimes finds an approximate output. The agent then mistakes it as the only path and marks it as the solution while backtracking. Since all the states in the path are marked with a value of
Moreover, the model works by assigning rewards for each action it takes to learn about the environment to reach the goal. The agent tries to find a target output but sometimes finds an approximate output. The agent then mistakes it as the only path and marks it as the solution while backtracking. Since all the states in the path are marked with a value of  (positive reward), this will cause difficulty in reaching the target location.
(positive reward), this will cause difficulty in reaching the target location.
In other words, the value function for such an environment may not always be suitable. Consequently, the Bellman operator was created to enhance the solution derivation using reinforcement learning.
The Bellman equation, named after Richards E. Bellman, sets the reward with hints about its next action.
The reinforcement agent will aim to proceed with the actions, producing maximum reward. Bellman’s method considers the current action’s reward and the predicted reward for future action, and it can be illustrated by the formulation:
![V(S_{c})= max_{a}[R(S_{c},a) + \curlyvee V(S_{n})]](/wp-content/ql-cache/quicklatex.com-1e41c2936220087b861fb72c3cb02f96_l3.svg "Rendered by QuickLaTeX.com")
where,  and
and  indicate the current and next state,
indicate the current and next state,  represents action,
represents action,  indicates the value of the state,
indicates the value of the state,  is the reward of an action at a state and
is the reward of an action at a state and  represents the factor limiting the value range to be
represents the factor limiting the value range to be  .
.
We can assume an example of a game environment where the player aims to reach a goal location where the player gets the highest reward. Let’s visualize the game environment:
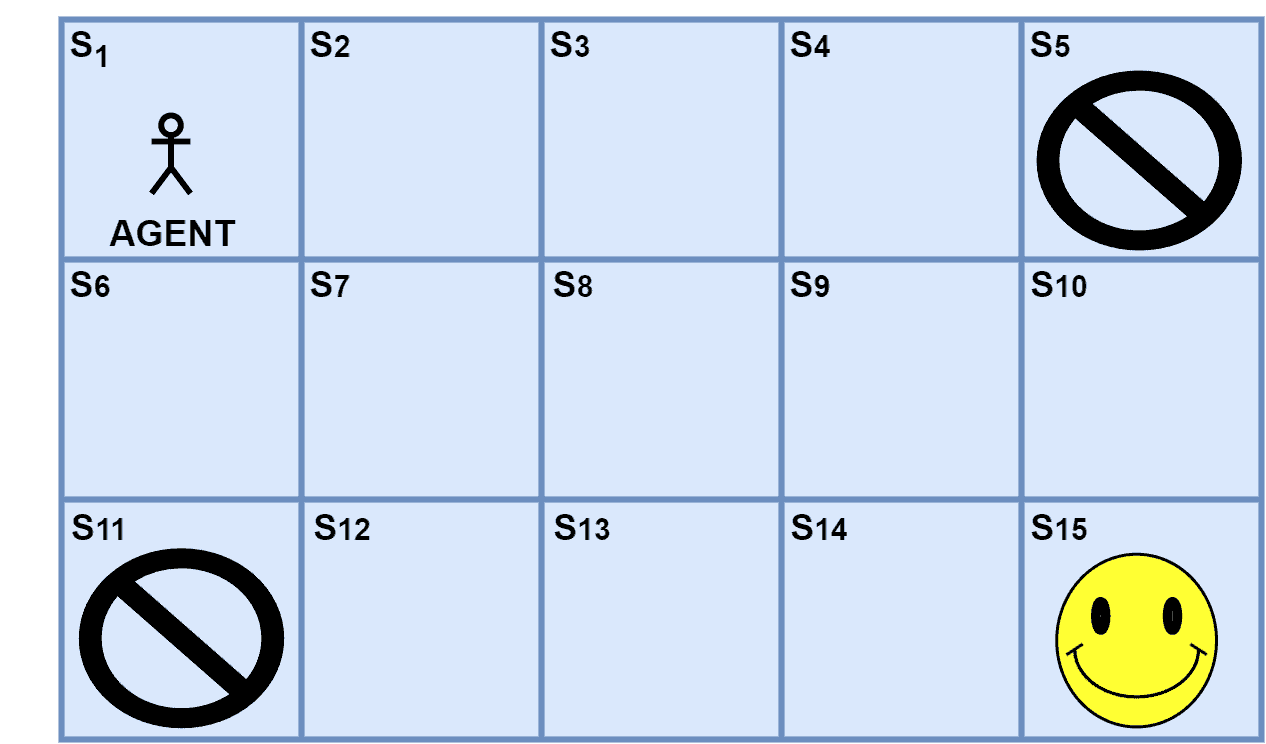
The environment space has an agent from a source location aiming to reach a target location. Additionally, the agent gets three types of rewards such as positive  , neutral
, neutral  , and negative
, and negative  . Further, the reward at the target location is . Furthermore, normal states have neutral rewards, and any undesirable states have negative rewards. However, the actions possible are right, left, up and down. Moreover, we take the value of as
. Further, the reward at the target location is . Furthermore, normal states have neutral rewards, and any undesirable states have negative rewards. However, the actions possible are right, left, up and down. Moreover, we take the value of as  so that the value of the next state makes a difference in deciding the value of the states.
so that the value of the next state makes a difference in deciding the value of the states.
The agent explores the environment and calculates the value of each state as per Bellman’s operator. For example, the target location is  , and the reward to reach it is . Let’s assume the agent moves in the path of covering states
, and the reward to reach it is . Let’s assume the agent moves in the path of covering states  and finally without moving to the states that are closer to the negative reward states. Since the Bellman considers the value of the next state, we present the calculation in the reverse order:
and finally without moving to the states that are closer to the negative reward states. Since the Bellman considers the value of the next state, we present the calculation in the reverse order:
Let’s take the value of state to be  since it’s the final goal state. Now, we can calculate:
since it’s the final goal state. Now, we can calculate:
 .
.
 .
.
 .
.
 .
.
 .
.
 .
.
As a result, it gets a picture of the states that lead to the target state. Finally, the agent reaches the target location, regardless of its source location, by following states with increasing values.
Let’s examine some of the main advantages and disadvantages of using Bellman’s operator in reinforcement learning.
Using other algorithms that find a path from source to solution, when found, we mark the value of all states as . However, this information can’t be used for future purposes. Starting from a different source location, the agent observes that the value of all the states in the path is . Moreover, this means there’s no difference between the goal and intermediary steps. Thus collapsing the setup.
By using Bellman’s formulation, even after an agent has found the path to the goal, we can obtain the mapping of the environment. For example, we can suitably use the Bellman operator for the single-source shortest path algorithm.
Bellman works as an optimization equation where at least a basic knowledge of the environment is available, for example, in environments where we don’t know which states should be marked with negative reward and neutral. This makes it difficult for the value function to give incorrect results and fail the whole idea. As a result, it’s not suitable for complex and bigger environment spaces.
In this article, we presented a generic idea behind reinforcement learning and how the Bellman operator aids in achieving the learning technique. Additionally, we have discussed an example along with the merits and demerits of the Bellman operator.