Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 20, 2023

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’re going to analyze the complex ideas that enable us to build sophisticated central processor units (CPU). Even though we use registers, the arithmetic logic unit, and the control unit to make an abstraction of a CPU, it has some other complex parts such as caches and advanced mechanisms like instruction pipelining, branch prediction, and many more.
Devices that we’re writing and publishing these articles are probably running at gigahertz speeds. That’s a billion instructions executed every second. When we think of the early computers that perform only one calculation per second, we can understand that computers have come a long way since then.
In the early days of computing, processor designers usually used to try to improve the switching time of transistors or to increase the number of transistors inside the chip. However, due to the limitations in the nature of transistors and the chips, processor designers have developed different mechanisms to boost performance.
CPU even performs the tiniest computations via instructions. For example, to divide two numbers, it can break down this operation into the smaller problem of subtraction. It keeps extracting one number from the other one until it hits zero or a negative number. This method consumes a lot of clock cycles.
Today, most computer processors have the divide instruction that the ALU can perform in hardware. Even though it makes the ALU bigger and more complicated, it’s a useful complexity-for-speed trade-off that has been preferred many times in computing history.
Beyond this divide instruction, there are some specialized CPUs that have specific circuits for things like encrypting files, decoding compressed video, and graphics operations. For instance, Intel’s MMX and AMD’s 3DNow! are some of the examples of specialized CPUs in the figure below:


These extensions to the instruction set have grown over time. When people take advantage of these instructions, it’s difficult to remove them. Therefore, instruction sets tend to get bigger and larger keeping all the opcodes. One of the first CPUs, the Intel 4004, only had 46 instructions, which was enough to build a fully functional computer such as Kenbak-1.
Modern computer processors have thousands of various instructions. They utilize all sorts of complex internal circuitry. These fancy instruction sets and high clock speeds lead to another issue. It’s getting data in and out of the CPU quickly enough. Imagine that we have a furniture factory that can produce so many products in seconds. It would need a lot of woods inside the factory all the time.
At this point, the bottleneck is the RAM. It’s a memory module that lies outside the CPU. Imagine that it’s a forest outside the city for our furniture factory analogy. This means that data ought to be transferred from and to RAM along with the data wires, called a bus.
This bus is just a few centimeters. Even though electrical signals travel at near the speed of light, when working gigahertz rates, which means billionths of a second, even a tiny delay becomes troublesome. The RAM also needs time to search up the address and retrieve the data. Therefore loading from RAM may take hundreds of clock cycles. If we get back to our analogy if try to take the wood from a forest all the time in the meantime the factory can’t do anything because it has no wood to build furniture. Similarly, the CPU is just sitting there idly waiting for the data.
One solution to overcome this bottleneck is to put a little piece of storage unit on the CPU. It’s called a cache. As we can see from the figure below, there isn’t a lot of area on a processor’s chip. Thus, most caches are just kilobytes or megabytes in size, whereas RAM is gigabytes. If we think about our analogy again, it’s like a warehouse for the woods to build furniture. Instead of waiting for the wood coming from the forest, we can store it in a warehouse near the factory. In this way, we can speed up the process in a clever way:
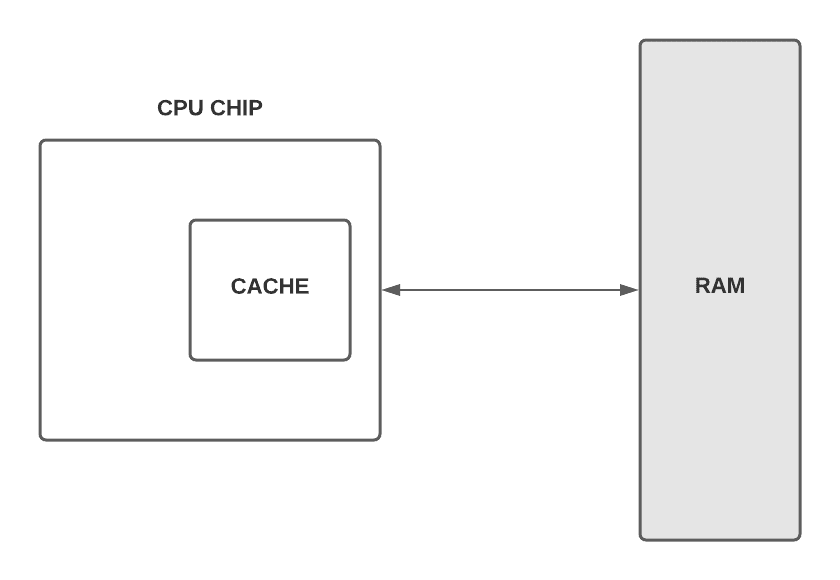
Whenever the CPU requests a memory location from RAM, the RAM can send not just one value, but an entire block of data. This takes somewhat longer than sending a single value, but it permits this data block to be stored in the cache. This is extremely beneficial since computers store data frequently organized and processed consecutively.
When the processor is calculating some expressions, it doesn’t need to go all the way to RAM. Since the cache is so close to the processor, it can typically provide the data in a single clock cycle. Just rethink our analogy, instead of going all the way to the forest, we can directly use the resources that we have in our warehouse which is the cache in the processor.
If data requested from RAM is already in the cache, we call it a cache hit. If the data requested is not in the cache, we must go all way to the RAM and we call it a cache miss.
Having data in two separate places can cause a synchronization issue. When we change the value of an address in the cache we need to update it in RAM as well. For this purpose, the cache has a flag for each block of memory it stores. It’s called the dirty bit. Mostly, this synchronization occurs when the cache is full. Before the cache erases the old block to free up space, it checks its dirty bit. If it’s dirty the old block of data is written back to RAM.
Instruction pipelining is another mechanism that is employed by the CPU designers to increase the throughput of the CPU. Let’s get back to our analogy where we have a furniture company, so in order to build furniture, we need some operations right. Like getting the wood, cutting the wood into pieces, and assemble them somehow. Instead of getting all the wood and cutting all the wood processes separately, we can parallelize them.
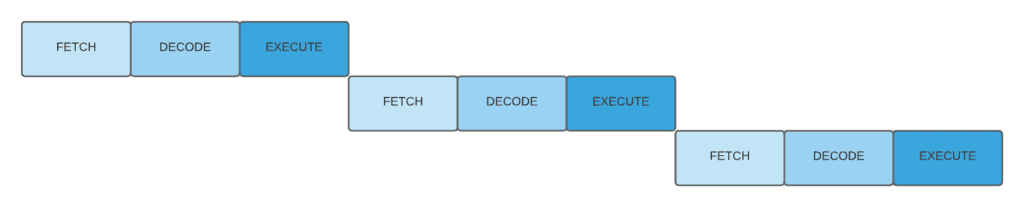
Like in the furniture example, the CPU should follow the instruction cycle which simply includes, fetch, decode, and execute. We can finish all three stages and start the new cycle after that. However, we have another choice right after the fetch of the first instruction: we can fetch another instruction. Since each stage uses a different part of the CPU we can parallelize them.
Let’s take look at the figure below to understand better. As we’ve seen, in order to fetch to second instruction, we’re waiting for the first instruction to execute:
However, while one instruction is getting executed, the next instruction can be getting decoded. All of these separate processes can overlap so that all parts of the CPU are active at any given time. With this design in the figure below, we can triple the throughput:
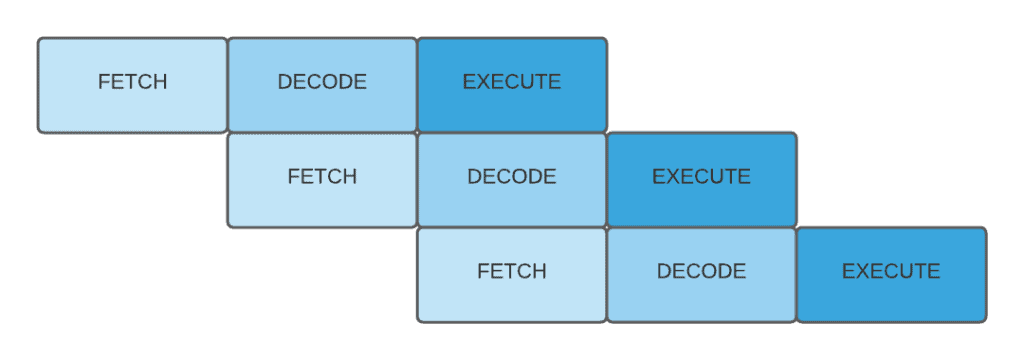
There can be dependencies among the instructions. For example, we may fetch something that is about to be changed by another instruction. In that case, we’ll end up with the old value in the pipeline.
To recover such cases, pipelined processors must look ahead for data dependencies and if there is, stall their pipelines to get rid of problems. Exclusive and sophisticated processors such as those present in laptops and smartphones can dynamically reorder instructions with dependencies in order to reduce stalls and keep the pipeline flowing. We call it out-of-order execution.
Another issue is conditional jump conditions. These instructions can alter the execution path of a program depending on the value.
When a basic pipelined processor detects a jump instruction, it’ll execute a long stall while waiting for the value to be completed. The processor begins refilling its pipeline only if it knows the jump outcome. However, this might result in significant delays. Therefore high-end processors have various techniques to deal with this issue.
Consider a forthcoming jump instruction, a branch. Advanced CPUs estimate which path they will proceed and begin loading their pipeline with instructions based on that assumption. We call this technique speculative execution.
If these estimations are wrong, the CPU has to discard all its speculative results and perform a flush. To reduce the effects of these flushes, CPU designers have developed special ways to guess where to branch will go. It’s called branch prediction. The accuracy of branch predictors of modern processors has increased and surpassed the 50/50 guess. However, this exclusive design method may lead to security issues known as speculative execution side-channel vulnerabilities.
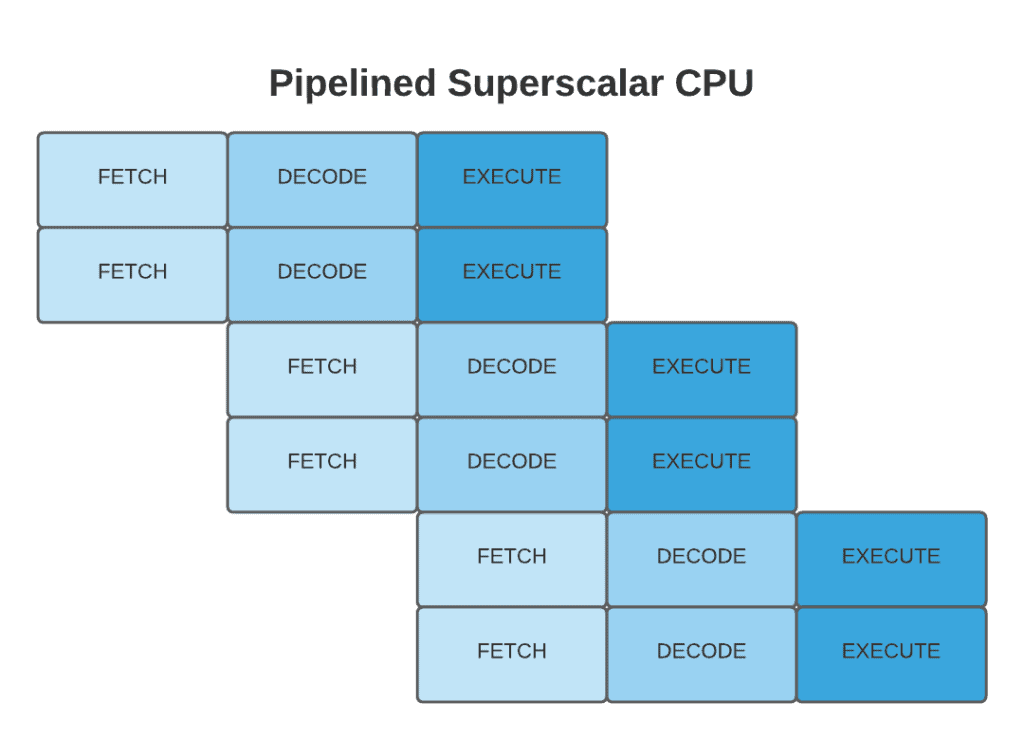
Superscalar processors can execute more than one instruction per clock cycle, as in the figure below. Even in the pipelined design, during the execute stage, some areas of the CPU might be totally idle. For instance, while executing an instruction that fetches a value from memory, the ALU will be idle.
Superscalar processor duplicates the circuitry for popular instructions. It doesn’t have a separate processor or core. It exploits the execution resources within a single CPU such as an ALU:
Another method to boost performance is to use multi-core processors to run many streams of instructions at the same time. Dual-core or quad-core processors are examples of the multiple independent processing units inside of a single CPU chip as in the figure below. It represents the core structure of the next-generation Intel microarchitecture (Nehalem) released in 2008. It has some other important parts as well, however, in the scope of this article we’re not going to get into details about them:

In this article, we’ve briefly explained the complex parts and mechanisms of advanced CPUs. We’ve shared an analogy about the cache to make things more understandable. We’ve also explained the instruction pipelining and looked at how superscalar and multi-core processors work.