Design Principles and Patterns for Highly Concurrent Applications
Last updated: January 8, 2024


Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
1. Overview
In this tutorial, we’ll discuss some of the design principles and patterns that have been established over time to build highly concurrent applications.
However, it’s worthwhile to note that designing a concurrent application is a wide and complex topic, and hence no tutorial can claim to be exhaustive in its treatment. What we’ll cover here are some of the popular tricks often employed!
2. Basics of Concurrency
Before we proceed any further, let’s spend some time understanding the basics. To begin with, we must clarify our understanding of what do we call a concurrent program. We refer to a program being concurrent if multiple computations are happening at the same time.
Now, note that we’ve mentioned computations happening at the same time — that is, they’re in progress at the same time. However, they may or may not be executing simultaneously. It’s important to understand the difference as simultaneously executing computations are referred to as parallel.
2.1. How to Create Concurrent Modules?
It’s important to understand how can we create concurrent modules. There are numerous options, but we’ll focus on two popular choices here:
- Process: A process is an instance of a running program that is isolated from other processes in the same machine. Each process on a machine has its own isolated time and space. Hence, it’s normally not possible to share memory between processes, and they must communicate by passing messages.
- Thread: A thread, on the other hand, is just a segment of a process. There can be multiple threads within a program sharing the same memory space. However, each thread has a unique stack and priority. A thread can be native (natively scheduled by the operating system) or green (scheduled by a runtime library).
2.2. How Do Concurrent Modules Interact?
It’s quite ideal if concurrent modules don’t have to communicate, but that’s often not the case. This gives rise to two models of concurrent programming:
- Shared Memory: In this model, concurrent modules interact by reading and writing shared objects in the memory. This often leads to the interleaving of concurrent computations, causing race conditions. Hence, it can non-deterministically lead to incorrect states.
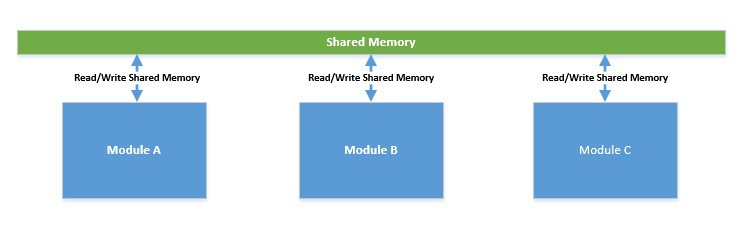
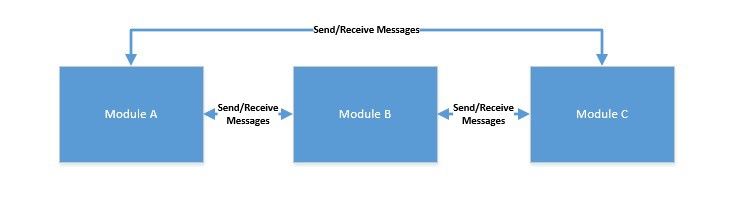
- Message Passing: In this model, concurrent modules interact by passing messages to each other through a communication channel. Here, each module processes incoming messages sequentially. Since there’s no shared state, it’s relatively easier to program, but this still isn’t free from race conditions!
2.3. How Do Concurrent Modules Execute?
It’s been a while since Moore’s Law hit a wall with respect to the clock speed of the processor. Instead, since we must grow, we’ve started to pack multiple processors onto the same chip, often called multicore processors. But still, it’s not common to hear about processors that have more than 32 cores.
Now, we know that a single core can execute only one thread, or set of instructions, at a time. However, the number of processes and threads can be in hundreds and thousands, respectively. So, how does it really work? This is where the operating system simulates concurrency for us. The operating system achieves this by time-slicing — which effectively means that the processor switches between threads frequently, unpredictably, and non-deterministically.
3. Problems in Concurrent Programming
As we go about discussing principles and patterns to design a concurrent application, it would be wise to first understand what the typical problems are.
For a very large part, our experience with concurrent programming involves using native threads with shared memory. Hence, we will focus on some of the common problems that emanate from it:
- Mutual Exclusion (Synchronization Primitives): Interleaving threads need to have exclusive access to shared state or memory to ensure the correctness of programs. The synchronization of shared resources is a popular method to achieve mutual exclusion. There are several synchronization primitives available to use — for example, a lock, monitor, semaphore, or mutex. However, programming for mutual exclusion is error-prone and can often lead to performance bottlenecks. There are several well-discussed issues related to this like deadlock and livelock.
- Context Switching (Heavyweight Threads): Every operating system has native, albeit varied, support for concurrent modules like process and thread. As discussed, one of the fundamental services that an operating system provides is scheduling threads to execute on a limited number of processors through time-slicing. Now, this effectively means that threads are frequently switched between different states. In the process, their current state needs to be saved and resumed. This is a time-consuming activity directly impacting the overall throughput.
4. Design Patterns for High Concurrency
Now, that we understand the basics of concurrent programming and the common problems therein, it’s time to understand some of the common patterns for avoiding these problems. We must reiterate that concurrent programming is a difficult task that requires a lot of experience. Hence, following some of the established patterns can make the task easier.
4.1. Actor-Based Concurrency
The first design we will discuss with respect to concurrent programming is called the Actor Model. This is a mathematical model of concurrent computation that basically treats everything as an actor. Actors can pass messages to each other and, in response to a message, can make local decisions. This was first proposed by Carl Hewitt and has inspired a number of programming languages.
Scala’s primary construct for concurrent programming is actors. Actors are normal objects in Scala that we can create by instantiating the Actor class. Furthermore, the Scala Actors library provides many useful actor operations:
class myActor extends Actor {
def act() {
while(true) {
receive {
// Perform some action
}
}
}
}In the example above, a call to the receive method inside an infinite loop suspends the actor until a message arrives. Upon arrival, the message is removed from the actor’s mailbox, and the necessary actions are taken.
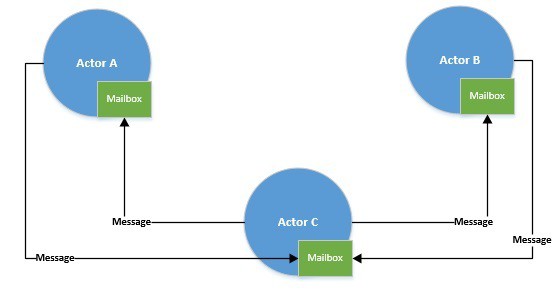
The actor model eliminates one of the fundamental problems with concurrent programming — shared memory. Actors communicate through messages, and each actor processes messages from its exclusive mailboxes sequentially. However, we execute actors over a thread pool. And we’ve seen that native threads can be heavyweight and, hence, limited in number.
There are, of course, other patterns that can help us here — we’ll cover those later!
4.2. Event-Based Concurrency
Event-based designs explicitly address the problem that native threads are costly to spawn and operate. One of the event-based designs is the event loop. The event loop works with an event provider and a set of event handlers. In this set-up, the event loop blocks on the event provider and dispatches an event to an event handler on arrival.
Basically, the event loop is nothing but an event dispatcher! The event loop itself can be running on just a single native thread. So, what really transpires in an event loop? Let’s look at the pseudo-code of a really simple event loop for an example:
while(true) {
events = getEvents();
for(e in events)
processEvent(e);
}Basically, all our event loop is doing is to continuously look for events and, when events are found, process them. The approach is really simple, but it reaps the benefit of an event-driven design.
Building concurrent applications using this design gives more control to the application. Also, it eliminates some of the typical problems of the multi-threaded applications — for example, deadlock.
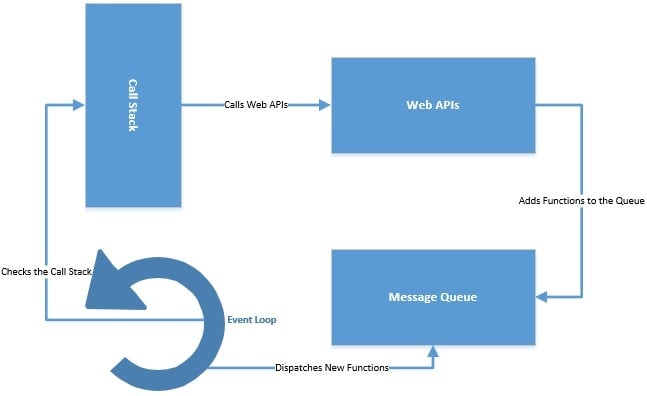
JavaScript implements the event loop to offer asynchronous programming. It maintains a call stack to keep track of all the functions to execute. It also maintains an event queue for sending new functions for processing. The event loop constantly checks the call stack and adds new functions from the event queue. All async calls are dispatched to the web APIs, typically provided by the browser.
The event loop itself can be running off a single thread, but the web APIs provide separate threads.
4.3. Non-Blocking Algorithms
In non-blocking algorithms, suspension of one thread does not lead to suspension of other threads. We’ve seen that we can only have a limited number of native threads in our application. Now, an algorithm that blocks on a thread obviously brings down the throughput significantly and prevents us from building highly concurrent applications.
Non-blocking algorithms invariably make use of the compare-and-swap atomic primitive that is provided by the underlying hardware. This means that the hardware will compare the contents of a memory location with a given value, and only if they are the same will it update the value to a new given value. This may look simple, but it effectively provides us an atomic operation that otherwise would require synchronization.
This means that we have to write new data structures and libraries that make use of this atomic operation. This has given us a huge set of wait-free and lock-free implementations in several languages. Java has several non-blocking data structures like AtomicBoolean, AtomicInteger, AtomicLong, and AtomicReference.
Consider an application where multiple threads are trying to access the same code:
boolean open = false;
if(!open) {
// Do Something
open=false;
}Clearly, the code above is not thread-safe, and its behavior in a multi-threaded environment can be unpredictable. Our options here are either to synchronize this piece of code with a lock or use an atomic operation:
AtomicBoolean open = new AtomicBoolean(false);
if(open.compareAndSet(false, true) {
// Do Something
}As we can see, using a non-blocking data structure like AtomicBoolean helps us write thread-safe code without indulging in the drawbacks of locks!
5. Support in Programming Languages
We’ve seen that there are multiple ways we can construct a concurrent module. While the programming language does make a difference, it’s mostly how the underlying operating system supports the concept. However, as thread-based concurrency supported by native threads are hitting new walls with respect to scalability, we always need new options.
Implementing some of the design practices we discussed in the last section do prove to be effective. However, we must keep in mind that it does complicate programming as such. What we truly need is something that provides the power of thread-based concurrency without the undesirable effects it brings.
One solution available to us is green threads. Green threads are threads that are scheduled by the runtime library instead of being scheduled natively by the underlying operating system. While this doesn’t get rid of all the problems in thread-based concurrency, it certainly can give us better performance in some cases.
Now, it’s not trivial to use green threads unless the programming language we choose to use supports it. Not every programming language has this built-in support. Also, what we loosely call green threads can be implemented in very unique ways by different programming languages. Let’s see some of these options available to us.
5.1. Goroutines in Go
Goroutines in the Go programming language are light-weight threads. They offer functions or methods that can run concurrently with other functions or methods. Goroutines are extremely cheap as they occupy only a few kilobytes in stack size, to begin with.
Most importantly, goroutines are multiplexed with a lesser number of native threads. Moreover, goroutines communicate with each other using channels, thereby avoiding access to shared memory. We get pretty much everything we need, and guess what — without doing anything!
5.2. Processes in Erlang
In Erlang, each thread of execution is called a process. But, it’s not quite like the process we’ve discussed so far! Erlang processes are light-weight with a small memory footprint and are fast to create and dispose of with low scheduling overhead.
Under the hood, Erlang processes are nothing but functions that the runtime handles scheduling for. Moreover, Erlang processes don’t share any data, and they communicate with each other by message passing. This is the reason why we call these “processes” in the first place!
5.3. Fibers in Java (Proposal)
The story of concurrency with Java has been a continuous evolution. Java did have support for green threads, at least for Solaris operating systems, to begin with. However, this was discontinued due to hurdles beyond the scope of this tutorial.
Since then, concurrency in Java is all about native threads and how to work with them smartly! But for obvious reasons, we may soon have a new concurrency abstraction in Java, called fiber. Project Loom proposes to introduce continuations together with fibers, which may change the way we write concurrent applications in Java!
This is just a sneak peek of what is available in different programming languages. There are far more interesting ways other programming languages have tried to deal with concurrency.
Moreover, it’s worth noting that a combination of design patterns discussed in the last section, together with the programming language support for a green-thread-like abstraction, can be extremely powerful when designing highly concurrent applications.
6. High Concurrency Applications
A real-world application often has multiple components interacting with each other over the wire. We typically access it over the internet, and it consists of multiple services like proxy service, gateway, web service, database, directory service, and file systems.
How do we ensure high concurrency in such situations? Let’s explore some of these layers and the options we have for building a highly concurrent application.
As we’ve seen in the previous section, the key to building high concurrency applications is to use some of the design concepts discussed there. We need to pick the right software for the job — those that already incorporate some of these practices.
6.1. Web Layer
The web is typically the first layer where user requests arrive, and provisioning for high concurrency is inevitable here. Let’s see what are some of the options:
- Node (also called NodeJS or Node.js) is an open-source, cross-platform JavaScript runtime built on Chrome’s V8 JavaScript engine. Node works quite well in handling asynchronous I/O operations. The reason Node does it so well is because it implements an event loop over a single thread. The event loop with the help of callbacks handles all blocking operations like I/O asynchronously.
- nginx is an open-source web server that we use commonly as a reverse proxy among its other usages. The reason nginx provides high concurrency is that it uses an asynchronous, event-driven approach. nginx operates with a master process in a single thread. The master process maintains worker processes that do the actual processing. Hence, the worker processes process each request concurrently.
6.2. Application Layer
While designing an application, there are several tools to help us build for high concurrency. Let’s examine a few of these libraries and frameworks that are available to us:
- Akka is a toolkit written in Scala for building highly concurrent and distributed applications on the JVM. Akka’s approach towards handling concurrency is based on the actor model we discussed earlier. Akka creates a layer between the actors and the underlying systems. The framework handles the complexities of creating and scheduling threads, receiving and dispatching messages.
- Project Reactor is a reactive library for building non-blocking applications on the JVM. It’s based on the Reactive Streams specification and focuses on efficient message passing and demand management (back-pressure). Reactor operators and schedulers can sustain high throughput rates for messages. Several popular frameworks provide reactor implementations, including Spring WebFlux and RSocket.
- Netty is an asynchronous, event-driven, network application framework. We can use Netty to develop highly concurrent protocol servers and clients. Netty leverages NIO, which is a collection of Java APIs that offers asynchronous data transfer through buffers and channels. It offers us several advantages like better throughput, lower latency, less resource consumption, and minimize unnecessary memory copy.
6.3. Data Layer
Finally, no application is complete without its data, and data comes from persistent storage. When we discuss high concurrency with respect to databases, most of the focus remains on the NoSQL family. This is primarily owing to linear scalability that NoSQL databases can offer but is hard to achieve in relational variants. Let’s look at two popular tools for the data layer:
- Cassandra is a free and open-source NoSQL distributed database that provides high availability, high scalability, and fault-tolerance on commodity hardware. However, Cassandra does not provide ACID transactions spanning multiple tables. So if our application does not require strong consistency and transactions, we can benefit from Cassandra’s low-latency operations.
- Kafka is a distributed streaming platform. Kafka stores a stream of records in categories called topics. It can provide linear horizontal scalability for both producers and consumers of the records while, at the same time, providing high reliability and durability. Partitions, replicas, and brokers are some of the fundamental concepts on which it provides massively-distributed concurrency.
6.4. Cache Layer
Well, no web application in the modern world that aims for high concurrency can afford to hit the database every time. That leaves us to choose a cache — preferably an in-memory cache that can support our highly concurrent applications:
- Hazelcast is a distributed, cloud-friendly, in-memory object store and compute engine that supports a wide variety of data structures such as Map, Set, List, MultiMap, RingBuffer, and HyperLogLog. It has built-in replication and offers high availability and automatic partitioning.
- Redis is an in-memory data structure store that we primarily use as a cache. It provides an in-memory key-value database with optional durability. The supported data structures include strings, hashes, lists, and sets. Redis has built-in replication and offers high availability and automatic partitioning. In case we do not need persistence, Redis can offer us a feature-rich, networked, in-memory cache with outstanding performance.
Of course, we’ve barely scratched the surface of what is available to us in our pursuit to build a highly concurrent application. It’s important to note that, more than available software, our requirement should guide us to create an appropriate design. Some of these options may be suitable, while others may not be appropriate.
And, let’s not forget that there are many more options available that may be better suited for our requirements.
7. Conclusion
In this article, we discussed the basics of concurrent programming. We understood some of the fundamental aspects of the concurrency and the problems it can lead to. Further, we went through some of the design patterns that can help us avoid the typical problems in concurrent programming.
Finally, we went through some of the frameworks, libraries, and software available to us for building a highly-concurrent, end-to-end application.

















