

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
1. Overview
In this tutorial, we’ll discuss how to use secondary indexes in Apache Cassandra.
We’ll see how data is distributed in the database and explore all the index types. Finally, we’ll discuss some best practices and recommendations for using secondary indexes.
2. Cassandra Architecture
Cassandra is a NoSQL distributed database with a completely decentralized communication model.
It comprises multiple nodes with equal duties, offering high availability. It can run on any cloud provider and on-premise, making it cloud-agnostic.
We can also deploy a single Cassandra cluster simultaneously across multiple cloud platforms. It’s most suited for OLTP (Online Transaction Processing) queries, where response speed is crucial, with simple queries that rarely change.
2.1. Primary Key
The primary key is the most important data modeling choice that uniquely identifies a data record. It consists of at least one partition key and zero or more clustering columns.
The partition key defines how we split data across the cluster. The clustering column orders data on disk to enable fast read operations.
Let’s look at an example:
CREATE TABLE company (
company_name text,
employee_name text,
employee_email text,
employee_age int,
PRIMARY KEY ((company_name), employee_email)
);Here, we’ve defined company_name as the partition key used to distribute the table data evenly across the nodes. Next, since we’ve specified employee_email as a clustering column, Cassandra uses it to keep the data in ascending order on each node for efficient retrieval of rows.
2.2. Cluster Topology
Cassandra offers linear scalability and performance directly proportional to the number of nodes available.
The nodes are placed in a ring, forming a data center, and by connecting multiple geographically distributed data centers, we create a cluster.
Cassandra automatically partitions the data without manual intervention, thus making it big data ready.
Next, let’s see how Cassandra partitions our table by company_name:
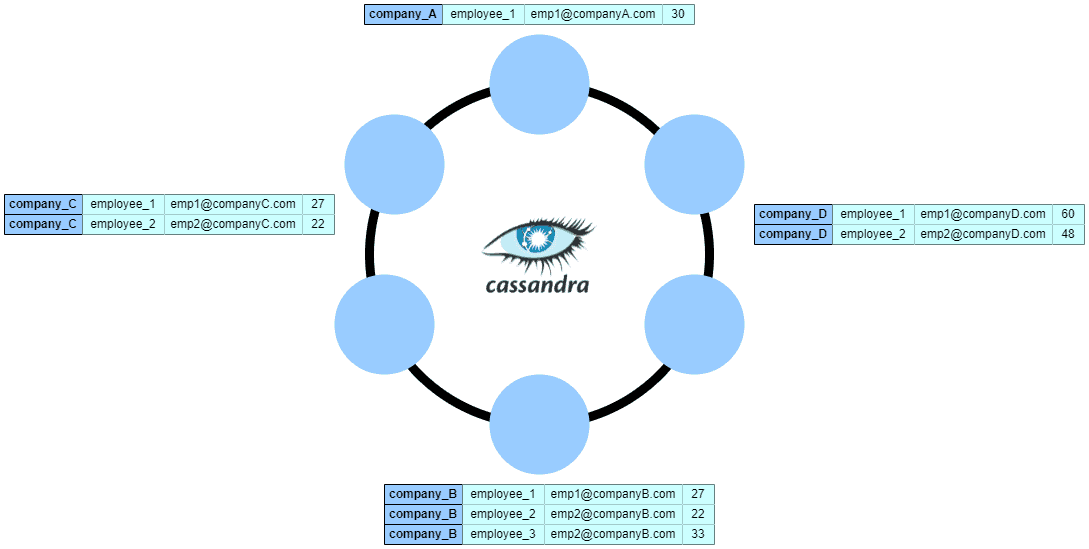
As we can see, the company table is split into partitions using the partition key company_name and distributed across the nodes. We can notice that Cassandra groups the rows with the same company_name value and stores them on the same physical partition on the disk. As a result, we can read all the data for a given company with minimal I/O cost.
Additionally, we can replicate the data across the data center by defining the replication factor. A replication factor of N will store each data row on N different nodes in the cluster.
We can specify the number of replicas at the data center level and not at the cluster level. As a result, we can have a cluster of multiple data centers, with each data center having a different replication factor.
3. Querying on Non-Primary Key
Let’s take the company table that we defined earlier and try to search by employee_age:
SELECT * FROM company WHERE employee_age = 30;
InvalidRequest: Error from server: code=2200 [Invalid query] message="Cannot execute this query as it might involve data filtering and thus may have unpredictable performance. If you want to execute this query despite the performance unpredictability, use ALLOW FILTERING"We get this error message because we cannot query a column that’s not part of the primary key unless we use the ALLOW FILTERING clause.
However, even if we technically can, we should not use it in production because ALLOW FILTERING is expensive and time-consuming. This is because, in the background, it starts full-table scans across all nodes in the cluster to fetch the results, which has a negative impact on performance.
However, one acceptable use case where we could use it is when we need to do a lot of filtering on a single partition. In this case, Cassandra still performs a table scan, but we can limit it to a single node:
SELECT * FROM company WHERE company_name = 'company_a' AND employee_age = 30 ALLOW FILTERING;Because we added the company_name clustering column as a condition, Cassandra uses it to identify the node that holds all the company data. Consequently, it performs a table scan just on the table data on that specific node.
4. Secondary Indexes
Secondary Indexes in Cassandra solve the need for querying columns that are not part of the primary key.
When we insert data, Cassandra uses an append-only file called commitlog for storing the changes, so writes are quick. At the same time, the data is written to an in-memory cache of key/column values called a Memtable. Periodically, Cassandra flushes the Memtable to disk in the form of an immutable SSTable.
Next, let’s look at three different indexing methods in Cassandra and discuss the advantages and disadvantages.
4.1. Regular Secondary Index (2i)
The regular secondary index is the most basic index we can define for executing queries on non-primary key columns.
Let’s define a secondary index on the employee_age column:
CREATE INDEX IF NOT EXISTS ON company (employee_age);With that in place, we can now run the query by employee_age without any errors:
SELECT * FROM company WHERE employee_age = 30;
company_name | employee_email | employee_age | employee_name
--------------+-------------------+--------------+---------------
company_A | [email protected] | 30 | employee_1When we set up the index, Cassandra creates a hidden table for storing the index data in the background:
CREATE TABLE company_by_employee_age_idx (
employee_age int,
company_name text,
employee_email text,
PRIMARY KEY ((employee_age), company_name, employee_email)
);Unlike regular tables, Cassandra doesn’t distribute the hidden index table using the cluster-wide partitioner. The index data is co-located with the source data on the same nodes.
Therefore, when executing a search query using the secondary index, Cassandra reads the indexed data from every node and collects all the results. If our cluster has many nodes, this can lead to increased data transfer and high latency.
We might ask ourselves why Cassandra doesn’t partition the index table across nodes based on the primary key. The answer is that storing the index data alongside the source data reduces the latency. Also, because the index update is executed locally and not over the network, there is no risk to lose the update operation due to connectivity issues. Additionally, Cassandra avoids creating wide partitions if the index column data is not evenly distributed.
When we insert data to a table with a secondary index attached, Cassandra writes to both the index and the base Memtable. Additionally, both are flushed to the SSTables simultaneously. Consequently, the index data will have a separate lifecycle than the source data.
When we read data based on the secondary index, Cassandra first retrieves the primary keys for all matching rows in the index, and after that, it uses them to fetch all the data from the source table.
4.2. SSTable-Attached Secondary Index (SASI)
SASI introduces the new idea of binding the SSTable lifecycle to the index. Performing in-memory indexing followed by flushing the index with the SSTable to disk reduces disk usage and saves CPU cycles.
Let’s look at how we define a SASI index:
CREATE CUSTOM INDEX IF NOT EXISTS company_by_employee_age ON company (employee_age) USING 'org.apache.cassandra.index.sasi.SASIIndex';The advantages of SASI are the tokenized text search, fast range scans, and in-memory indexing. On the other hand, a disadvantage is that it generates big index files, especially when enabling text tokenization.
Finally, we should note that SASI indexes in DataStax Enterprise (DSE) are experimental. DataStax does not support SASI indexes for production.
4.3. Storage-Attached Indexing (SAI)
Storage-Attached Indexing is a highly-scalable data indexing mechanism available for DataStax Astra and DataStax Enterprise databases. We can define one or more SAI indexes on any column and then use range queries (numeric only), CONTAINs semantics, and filter queries.
SAI stores individual index files for each column and contains a pointer to the offset of the source data in the SSTable. Once we insert data into an indexed column, it will be written first to memory. Whenever Cassandra flushes data from memory to disk, it writes the index along with the data table.
This approach improves throughput by 43% and latency by 230% over 2i by reducing the overhead for writing. Compared to SASI and 2i, it uses significantly less disk space for indexing, has fewer failure points, and comes with a more simplified architecture.
Let’s define our index using SAI:
CREATE CUSTOM INDEX ON company (employee_age) USING 'StorageAttachedIndex' WITH OPTIONS = {'case_sensitive': false, 'normalize': false};The normalize option transforms special characters to their base character. For example, we can normalize the German character ö to a regular o, enabling query matching without typing the special characters. So we can, for instance, search for the term “schön” by simply using “schon” as a condition.
4.4. Best Practices
Firstly, when we use secondary indexes in our queries, a recommendation is to add the partition key as a condition. As a result, we can reduce the read operation to a single node (plus replicas depending on the consistency level):
SELECT * FROM company WHERE employee_age = 30 AND company_name = "company_A";Secondly, we can restrict the query to a list of partition keys and bound the number of nodes involved in fetching the results:
SELECT * FROM company WHERE employee_age = 30 AND company_name IN ("company_A", "company_B", "company_C");Thirdly, if we need just a subset of the results, we can add a limit to the query. This also reduces the number of nodes involved in the read path:
SELECT * FROM company WHERE employee_age = 30 LIMIT 10;Additionally, we must avoid defining secondary indexes on columns with very low cardinality (gender, true/false columns, etc.) because they produce very wide partitions that impact performance.
Similarly, columns with high cardinality (social security number, email, etc.) will result in indexes with very granular partitions, which in the worst case will force the cluster coordinator to hit all the primary replicas.
Lastly, we must avoid using secondary indexes on frequently updated columns. The rationale behind this is that Cassandra uses immutable data structures, and frequent updates increases the number of write operations on disk.
5. Conclusion
In this article, we have explored how Cassandra partitions the data across the data center and explored three types of secondary indexes.
Before considering a secondary index, we should consider denormalizing our data into a second table and keeping it up to date with the main table if we plan to access it frequently.
On the other hand, if the data access is sporadic, adding a separate table adds unjustified complexity. Therefore, introducing a secondary index is a better option. Undoubtedly, storage-attached indexing is the best choice out of the three indexing options we have, offering the best performance and simplified architecture.

















