Cassandra Partition Key, Composite Key, and Clustering Key
Last updated: July 8, 2026


Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
1. Overview
Data distribution and data modeling in the Cassandra NoSQL database are different from those in a traditional relational database.
In this article, we’ll learn how a partition key, composite key, and clustering key form a primary key. We’ll also see how they differ. As a result, we’ll touch upon the data distribution architecture and data modeling topics in Cassandra.Further reading:
Build a Dashboard Using Cassandra, Astra, and Stargate
Build a Dashboard With Cassandra, Astra, REST & GraphQL - Recording Status Updates
Build a Dashboard With Cassandra, Astra and CQL – Mapping Event Data
2. Apache Cassandra Architecture
Apache Cassandra is an open-source NoSQL distributed database built for high availability and linear scalability without compromising performance.
Here is the high-level Cassandra architecture diagram:
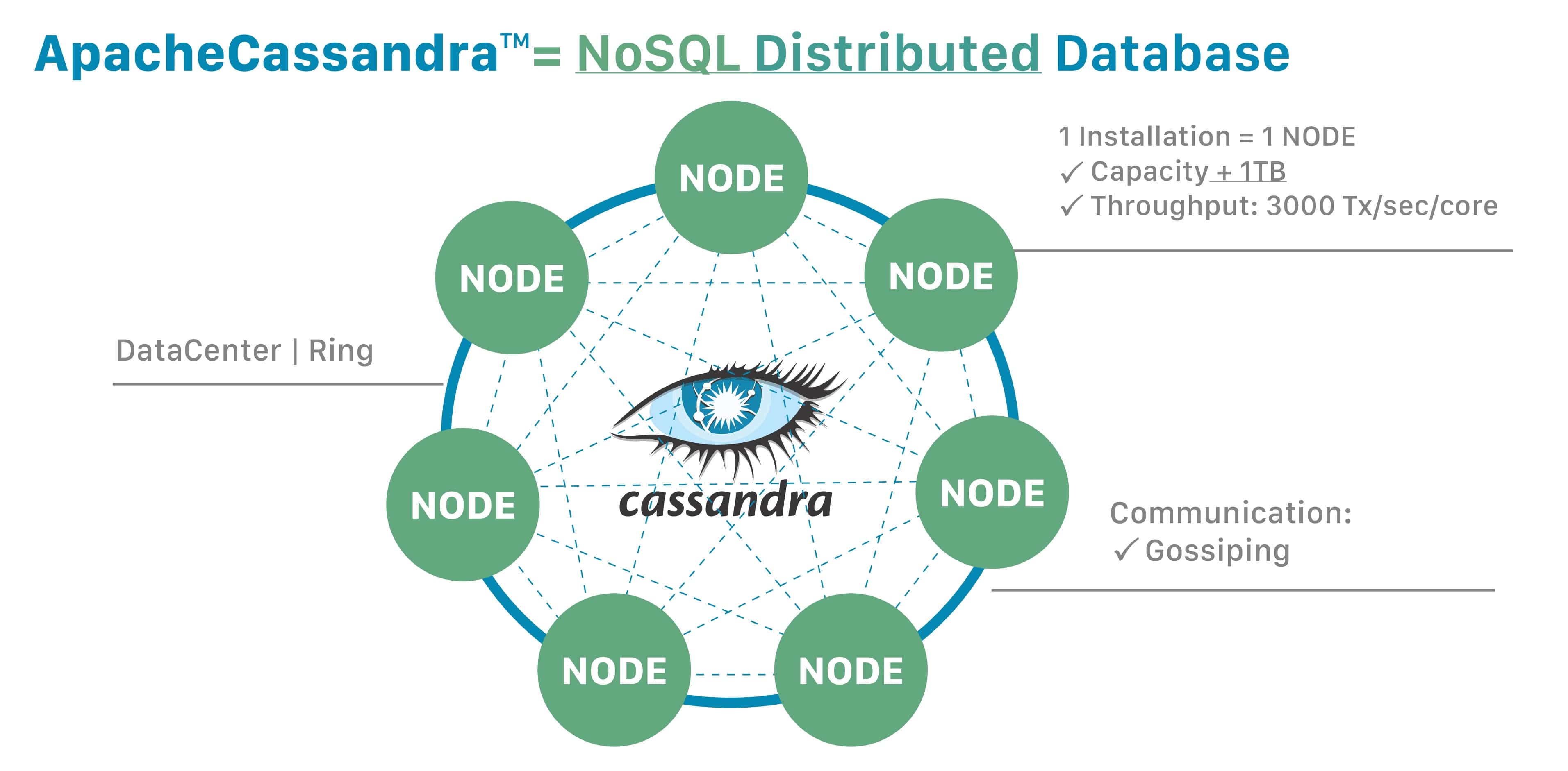
In Cassandra, the data is distributed across a cluster. Additionally, a cluster may consist of a ring of nodes arranged in racks installed in data centers across geographical regions.
At a more granular level, virtual nodes known as vnodes assign the data ownership to a physical machine. Vnodes make it possible to allow each node to own multiple small partition ranges by using a technique called consistent hashing to distribute the data.
A partitioner is a function that hashes the partition key to generate a token. This token value represents a row and is used to identify the partition range it belongs to in a node.
However, a Cassandra client sees the cluster as a unified whole database and communicates with it using a Cassandra driver library.
3. Cassandra Data Modeling
Generally, data modeling is a process of analyzing the application requirements, identifying the entities and their relationships, organizing the data, and so on. In relational data modeling, the queries are often an afterthought in the whole data modeling process.
However, in Cassandra, the data access queries drive the data modeling. The queries are, in turn, driven by the application workflows.
Additionally, there are no table-joins in the Cassandra data models, which implies that all desired data in a query must come from a single table. As a result, the data in a table is in a denormalized format.
Next, in the logical data modeling step, we specify the actual database schema by defining keyspaces, tables, and even table columns. Then, in the physical data modeling step, we use the Cassandra Query Language (CQL) to create physical keyspaces — tables with all data types in a cluster.
4. Primary Key
The way primary keys work in Cassandra is an important concept to grasp.
A primary key in Cassandra consists of one or more partition keys and zero or more clustering key components. The order of these components always puts the partition key first and then the clustering key.
Apart from making data unique, the partition key component of a primary key plays an additional significant role in the placement of the data. As a result, it improves the performance of reads and writes of data spread across multiple nodes in a cluster.
Now, let’s look at each of these components of a primary key.
4.1. Partition Key
The primary goal of a partition key is to distribute the data evenly across a cluster and query the data efficiently.
A partition key is for data placement apart from uniquely identifying the data and is always the first value in the primary key definition.
Let’s try to understand using an example — a simple table containing application logs with one primary key:
CREATE TABLE application_logs (
id INT,
app_name VARCHAR,
hostname VARCHAR,
log_datetime TIMESTAMP,
env VARCHAR,
log_level VARCHAR,
log_message TEXT,
PRIMARY KEY (app_name)
);Here are some sample data in the above table:

As we learned earlier, Cassandra uses a consistent hashing technique to generate the hash value of the partition key (app_name) and assign the row data to a partition range inside a node.
Let’s look at possible data storage:
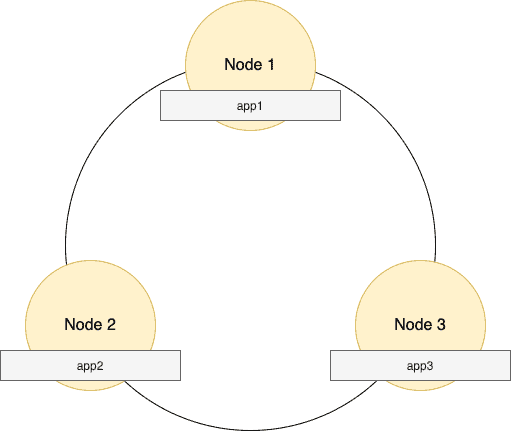
The above diagram is a possible scenario where the hash values of app1, app2, and app3 resulted in each row being stored in three different nodes — Node1, Node2, and Node3, respectively.
All app1 logs go to Node1, app2 logs go to Node2, and app3 logs go to Node3.
A data fetch query without a partition key in the where clause results in an inefficient full cluster scan.
On the other hand, with a partition key in where clause, Cassandra uses the consistent hashing technique to identify the exact node and the exact partition range within a node in the cluster. As a result, the fetch data query is fast and efficient:
select * application_logs where app_name = 'app1';4.2. Composite Partition Key
If we need to combine more than one column value to form a single partition key, we use a composite partition key.
Here again, the goal of the composite partition key is for the data placement, in addition to uniquely identifying the data. As a result, the storage and retrieval of data become efficient.
Here’s an example of the table definition that combines the app_name and env columns to form a composite partition key:
CREATE TABLE application_logs (
id INT,
app_name VARCHAR,
hostname VARCHAR,
log_datetime TIMESTAMP,
env VARCHAR,
log_level VARCHAR,
log_message TEXT,
PRIMARY KEY ((app_name, env))
);The important thing to note in the above definition is the inner parenthesis around app_name and env primary key definition. This inner parenthesis specifies that app_name and env are part of a partition key and are not clustering keys.
If we drop the inner parenthesis and have only a single parenthesis, then the app_name becomes the partition key, and env becomes the clustering key component.
Here’s the sample data for the above table:

Let’s look at the possible data distribution of the above sample data. Please note: Cassandra generates the hash value for the app_name and env column combination:
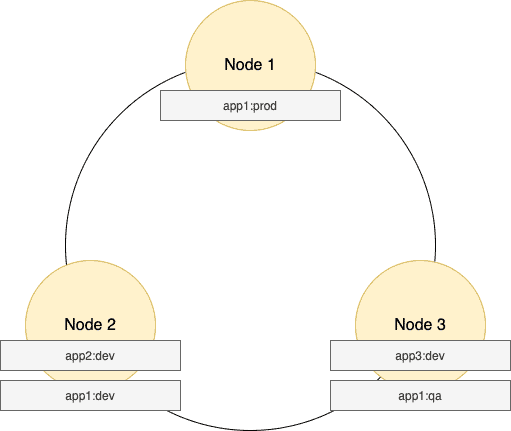
As we can see above, the possible scenario where the hash value of app1:prod, app1:dev, app1:qa resulted in these three rows being stored in three separate nodes — Node1, Node2, and Node3, respectively.
All app1 logs from the prod environment go to Node1, while app1 logs from the dev environment go to Node2, and app1 logs from the qa environment go to Node3.
Most importantly, to efficiently retrieve data, the where clause in fetch query must contain all the composite partition keys in the same order as specified in the primary key definition:
select * application_logs where app_name = 'app1' and env = 'prod';4.3. Clustering Key
As we’ve mentioned above, partitioning is the process of identifying the partition range within a node the data is placed into. In contrast, clustering is a storage engine process of sorting the data within a partition and is based on the columns defined as the clustering keys.
Moreover, identification of the clustering key columns needs to be done upfront — that’s because our selection of clustering key columns depends on how we want to use the data in our application.
All the data within a partition is stored in continuous storage, sorted by clustering key columns. As a result, the retrieval of the desired sorted data is very efficient.
Let’s look at an example table definition that has the clustering keys along with the composite partition keys:
CREATE TABLE application_logs (
id INT,
app_name VARCHAR,
hostname VARCHAR,
log_datetime TIMESTAMP,
env VARCHAR,
log_level VARCHAR,
log_message TEXT,
PRIMARY KEY ((app_name, env), hostname, log_datetime)
);And let’s see some sample data:

As we can see in the above table definition, we’ve included the hostname and the log_datetime as clustering key columns. Assuming all the logs from app1 and prod environment are stored in Node1, the Cassandra storage engine lexically sorts those logs by the hostname and the log_datetime within the partition.
By default, the Cassandra storage engine sorts the data in ascending order of clustering key columns, but we can control the clustering columns’ sort order by using WITH CLUSTERING ORDER BY clause in the table definition:
CREATE TABLE application_logs (
id INT,
app_name VARCHAR,
hostname VARCHAR,
log_datetime TIMESTAMP,
env VARCHAR,
log_level VARCHAR,
log_message TEXT,
PRIMARY KEY ((app_name,env), hostname, log_datetime)
)
WITH CLUSTERING ORDER BY (hostname ASC, log_datetime DESC);Per the above definition, within a partition, the Cassandra storage engine will store all logs in the lexical ascending order of hostname, but in descending order of log_datetime within each hostname group.
Now, let’s look at an example of the data fetch query with clustering columns in the where clause:
select * application_logs
where
app_name = 'app1' and env = 'prod'
and hostname = 'host1' and log_datetime > '2021-08-13T00:00:00';What’s important to note here is that the where clause should contain the columns in the same order as defined in the primary key clause.
5. Conclusion
In this article, we learned that Cassandra uses a partition key or a composite partition key to determine the placement of the data in a cluster. The clustering key provides the sort order of the data stored within a partition. All of these keys also uniquely identify the data.
We also touched upon the Cassandra architecture and data modeling topics.
For more information on Cassandra, visit the DataStax and Apache Cassandra documentation.


















