

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
1. Overview
In this tutorial, we’ll venture into the realm of data modeling for event-driven architecture using Apache Kafka.
2. Setup
A Kafka cluster consists of multiple Kafka brokers that are registered with a Zookeeper cluster. To keep things simple, we’ll use ready-made Docker images and docker-compose configurations published by Confluent.
First, let’s download the docker-compose.yml for a 3-node Kafka cluster:
$ BASE_URL="https://raw.githubusercontent.com/confluentinc/cp-docker-images/5.3.3-post/examples/kafka-cluster"
$ curl -Os "$BASE_URL"/docker-compose.ymlNext, let’s spin-up the Zookeeper and Kafka broker nodes:
$ docker-compose up -dFinally, we can verify that all the Kafka brokers are up:
$ docker-compose logs kafka-1 kafka-2 kafka-3 | grep started
kafka-1_1 | [2020-12-27 10:15:03,783] INFO [KafkaServer id=1] started (kafka.server.KafkaServer)
kafka-2_1 | [2020-12-27 10:15:04,134] INFO [KafkaServer id=2] started (kafka.server.KafkaServer)
kafka-3_1 | [2020-12-27 10:15:03,853] INFO [KafkaServer id=3] started (kafka.server.KafkaServer)3. Event Basics
Before we take up the task of data modeling for event-driven systems, we need to understand a few concepts such as events, event-stream, producer-consumer, and topic.
3.1. Event
An event in the Kafka-world is an information log of something that happened in the domain-world. It does it by recording the information as a key-value pair message along with few other attributes such as the timestamp, meta information, and headers.
Let’s assume that we’re modeling a game of chess; then an event could be a move:
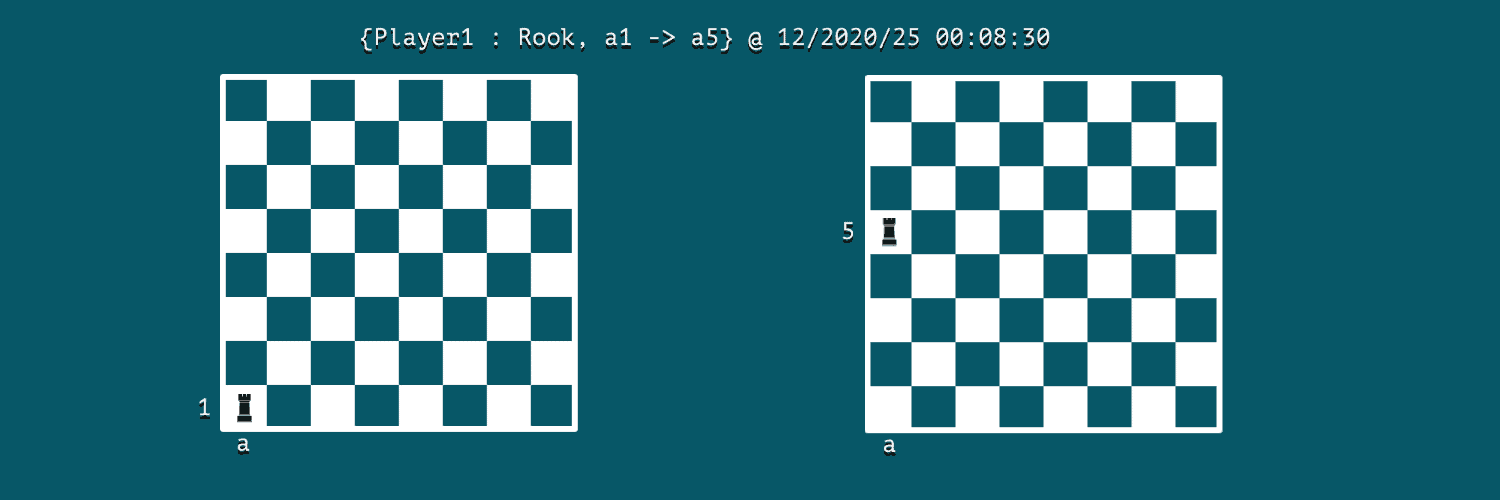
We can notice that event holds the key information of the actor, action, and time of its occurrence. In this case, Player1 is the actor, and the action is moving of rook from cell a1 to a5 at 12/2020/25 00:08:30.
3.2. Message Stream
Apache Kafka is a stream processing system that captures events as a message stream. In our game of chess, we can think of the event stream as a log of moves played by the players.
At the occurrence of each event, a snapshot of the board would represent its state. It’s usually common to store the latest static state of an object using a traditional table schema.
On the other hand, the event stream can help us capture the dynamic change between two consecutive states in the form of events. If we play a series of these immutable events, we can transition from one state to another. Such is the relationship between an event stream and a traditional table, often known as stream table duality.
Let’s visualize an event stream on the chessboard with just two consecutive events:

4. Topics
In this section, we’ll learn how to categorize messages routed through Apache Kafka.
4.1. Categorization
In a messaging system such as Apache Kafka, anything that produces the event is commonly called a producer. While the ones reading and consuming those messages are called consumers.
In a real-world scenario, each producer can generate events of different types, so it’d be a lot of wasted effort by the consumers if we expect them to filter the messages relevant to them and ignore the rest.
To solve this basic problem, Apache Kafka uses topics that are essentially groups of messages that belong together. As a result, consumers can be more productive while consuming the event messages.
In our chessboard example, a topic could be used to group all the moves under the chess-moves topic:
$ docker run \
--net=host --rm confluentinc/cp-kafka:5.0.0 \
kafka-topics --create --topic chess-moves \
--if-not-exists \
--partitions 1 --replication-factor 1 \
--zookeeper localhost:32181
Created topic "chess-moves".4.2. Producer-Consumer
Now, let’s see how producers and consumers use Kafka’s topics for message processing. We’ll use kafka-console-producer and kafka-console-consumer utilities shipped with Kafka distribution to demonstrate this.
Let’s spin up a container named kafka-producer wherein we’ll invoke the producer utility:
$ docker run \
--net=host \
--name=kafka-producer \
-it --rm \
confluentinc/cp-kafka:5.0.0 /bin/bash
# kafka-console-producer --broker-list localhost:19092,localhost:29092,localhost:39092 \
--topic chess-moves \
--property parse.key=true --property key.separator=:
Simultaneously, we can spin up a container named kafka-consumer wherein we’ll invoke the consumer utility:
$ docker run \
--net=host \
--name=kafka-consumer \
-it --rm \
confluentinc/cp-kafka:5.0.0 /bin/bash
# kafka-console-consumer --bootstrap-server localhost:19092,localhost:29092,localhost:39092 \
--topic chess-moves --from-beginning \
--property print.key=true --property print.value=true --property key.separator=:
Now, let’s record some game moves through the producer:
>{Player1 : Rook, a1->a5}As the consumer is active, it’ll pick up this message with key as Player1:
{Player1 : Rook, a1->a5}5. Partitions
Next, let’s see how we can create further categorization of messages using partitions and boost the performance of the entire system.
5.1. Concurrency
We can divide a topic into multiple partitions and invoke multiple consumers to consume messages from different partitions. By enabling such concurrency behavior, the overall performance of the system can thereby be improved.
By default, Kafka versions that support –bootstrap-server option during the creation of a topic would create a single partition of a topic unless explicitly specified at the time of topic creation. However, for a pre-existing topic, we can increase the number of partitions. Let’s set partition number to 3 for the chess-moves topic:
$ docker run \
--net=host \
--rm confluentinc/cp-kafka:5.0.0 \
bash -c "kafka-topics --alter --zookeeper localhost:32181 --topic chess-moves --partitions 3"
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
Adding partitions succeeded!5.2. Partition Key
Within a topic, Kafka processes messages across multiple partitions using a partition key. At one end, producers use it implicitly to route a message to one of the partitions. On the other end, each consumer can read messages from a specific partition.
By default, the producer would generate a hash value of the key followed by a modulus with the number of partitions. Then, it’d send the message to the partition identified by the calculated identifier.
Let’s create new event messages with the kafka-console-producer utility, but this time we’ll record moves by both the players:
# kafka-console-producer --broker-list localhost:19092,localhost:29092,localhost:39092 \
--topic chess-moves \
--property parse.key=true --property key.separator=:
>{Player1: Rook, a1 -> a5}
>{Player2: Bishop, g3 -> h4}
>{Player1: Rook, a5 -> e5}
>{Player2: Bishop, h4 -> g3}Now, we can have two consumers, one reading from partition-1 and the other reading from partition-2:
# kafka-console-consumer --bootstrap-server localhost:19092,localhost:29092,localhost:39092 \
--topic chess-moves --from-beginning \
--property print.key=true --property print.value=true \
--property key.separator=: \
--partition 1
{Player2: Bishop, g3 -> h4}
{Player2: Bishop, h4 -> g3}We can see that all moves by Player2 are being recorded into partition-1. In the same manner, we can check that moves by Player1 are being recorded into partition-0.
6. Scaling
How we conceptualize topics and partitions is crucial to horizontal scaling. On the one hand, a topic is more of a pre-defined categorization of data. On the other hand, a partition is a dynamic categorization of data that happens on the fly.
Further, there’re practical limits on how many partitions we can configure within a topic. That’s because each partition is mapped to a directory in the file system of the broker node. When we increase the number of partitions, we also increase the number of open file handles on our operating system.
As a rule of thumb, experts at Confluent recommend limiting the number of partitions per broker to 100 x b x r, where b is the number of brokers in a Kafka cluster, and r is the replication factor.
7. Conclusion
In this article, we used a Docker environment to cover the fundamentals of data modeling for a system that uses Apache Kafka for message processing. With a basic understanding of events, topics, and partitions, we’re now ready to conceptualize event streaming and further use this architecture paradigm.

















