

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Overview
Kafka is a powerful distributed event streaming platform that helps businesses process real-time data. Kafka follows an append-only log structure at its core, making it an ideal fit for event-driven architectures. Due to the perpetually increasing number of logs, cleanup strategies are crucial to properly managing the lifecycle of logs in Kafka.
Kafka offers two different cleanup strategies for its log: compact or delete. The cleanup strategies behave differently to cater to different data retention requirements. Additionally, they’re controlled by a separate set of configurations.
In this tutorial, we’ll learn about the compact cleanup strategy in Kafka.
2. Limitation of delete Cleanup Policy
In Kafka, the delete cleanup mechanism allows us to discard a message based on time. Essentially, the life of every message is time-bounded. Upon reaching a predefined duration, a background process will delete the message, reclaiming the disk storage.
This cleanup mechanism works for transient events that aren’t meant to be long-lasting. For example, event data such as application logs, sensor data, or notification triggers is typically processed once, and older data, if not already processed, is generally less meaningful than the latest data.
However, we can’t apply the delete policy on a Kafka topic that contains events that aren’t merely time-bounded. For example, an event-sourced system that uses Kafka as the persistent event store can’t afford to delete messages just because it got too old. It typically requires that the Kafka topic keep at least the latest event of a given message key. This allows the possibility of the system to build up its current state by replaying the events in the future.
To solve this problem, we can use the compact cleanup policy.
3. Log Compaction
The compact cleanup policy in Kafka offers a per-record retention for our messages. Specifically, it treats messages with the same message key as duplicates. During a cleanup process, the compact cleanup policy keeps the latest message value for a given message key, removing the older records.
A topic with a compact cleanup policy is commonly known as a compacted topic. To enable log compaction on a Kafka topic, we can set the Kafka topic-level property, cleanup.policy, to compact.
3.1. Differences Between compact and delete Cleanup Policy
The most critical difference between the two cleanup policies is that the delete policy only considers the message timestamp during removal. In contrast, the compact policy removes duplicate messages within the same Kafka partition.
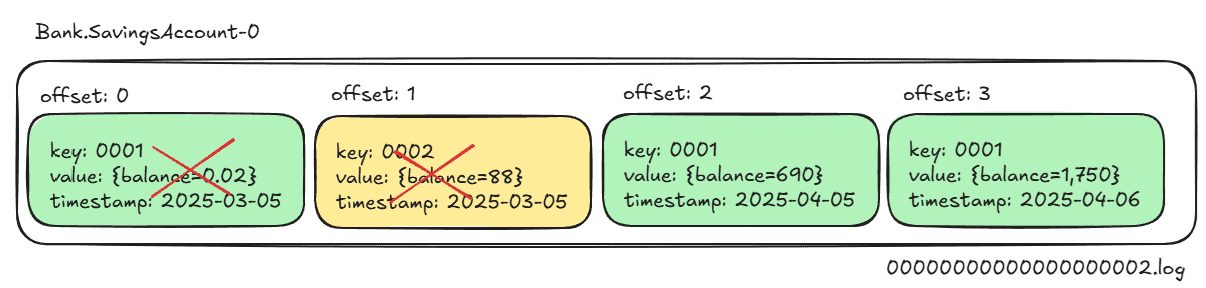
To illustrate the difference, consider that for our Kafka topic, Bank.SavingsAccount, partition 0 is made up of one log segment, 00000000000000000000.log. Then, the log segment contains four different messages:

As illustrated, the log segment contains four messages. The messages at offsets zero, two, and three share the same message key, 0001. Subsequently, the message at offset one has a different message key, 0002.
On 6th of April 2025, with a delete cleanup policy, messages at offset zero and one will be removed if we use the delete cleanup policy for our Kafka topic with a retention period of two days:
The removal is simply because both messages have been in the topic partition for more than the retention period of two days. As the messages at offsets zero and one are older than the 4th of April 2025 (two days before the cleanup operation ran), they’re removed by the log cleaner when using the delete cleanup policy.
On the other hand, a compact cleanup policy will remove messages at offsets zero and two:

The log cleaner removes the messages at offsets zero and two because the same message key has a newer message at offset three. The message at offset one is not removed because it’s the latest message for message key 0002.
3.2. Structure of Topic Partitions
Before diving into the compaction process, it’s important to understand that each topic partition consists of multiple log segments stored as files on disk.
A partition isn’t a single contiguous file, but a collection of segment files, each with a specific offset range. When a segment reaches its maximum size as defined by log.segment.bytes, or if it reaches the duration limit as imposed by the log.roll.ms parameter, Kafka closes it and creates a new one.
Let’s look at the directory structure of a typical Kafka topic partition:
/kafka-logs/
└── Bank.SavingsAccount-0/ # Topic "Bank.SavingsAccount", partition 0
├── 00000000000000000000.index # Index file for the first segment
├── 00000000000000000000.log # Log data for the first segment
├── 00000000000000000000.timeindex # Time index for the first segment
├── 00000000000000000150.index # Index file for the second segment
├── 00000000000000000150.log # Log data for the second segment
├── 00000000000000000150.timeindex # Time index for the second segment
├── leader-epoch-checkpoint
└── partition.metadataThe example above shows the log segment files within the topic Bank.SavingsAccount partition 0. Conventionally, the event data is stored in the .log file with its filename set to the earliest offset that the file contains. Then, the .index file stores the offset to each message’s mapping that pinpoints the exact location of that message in the .log file. Besides that, the .timeindex file stores the mapping between messages and timestamps that allows us to query events by timestamp.
3.3. Mechanism of Log Compaction
The Kafka broker runs a background process, the log cleaner, in a separate thread. The log cleaner periodically scans for topic partitions that are eligible for compaction. Concretely, the process looks for a topic that enables the compaction cleanup policy and has sufficiently large portions of uncleaned log segments over all its log segments.
The ratio of uncleaned log segments that triggers the compaction can be configured through the parameter min.cleanable.dirty.ratio. By default, the value is set to 0.5, which triggers log compaction whenever there are at least 50% uncleaned segments within a topic partition.
For those eligible partitions, the log cleaner performs the compaction. Starting off, it does a first pass to read the log segment. During this pass, it builds a map that maps a message key to the last offset for the log segment.
With the offset map, the log cleaner copies each log segment, omitting obsolete messages. A message is considered obsolete if the offset for its key is lower than recorded in the offset map and has existed in the segment for at least min.compaction.lag.ms. At the end of the process, the process produces a new log segment file along with its corresponding .index and .timeindex files. The old segment file is then deleted, freeing up disk storage space.
3.4. Monitoring Log Compaction
Log compaction incurs disk I/O and CPU overhead due to reading, writing, and deleting log segment files. As such, it’s vital to continuously monitor the log cleaner’s metrics to ensure the stability of the Kafka broker.
First, the LogCleaner_cleaner_recopy_percent_Value tells us the percentage of log segments that were recopied during cleaning. This metric indicates the effectiveness of the compaction done on our topic. Concretely, when the metric value is high, it means the log cleaner copies over a large amount of log during the rewrite. As a result, it indicates the efficiency of the log cleaner at removing duplicate records in a partition.
Besides that, the LogCleaner_max_clean_time_secs_Value indicates the maximum time in seconds the log cleaning operation took. If the log cleaner takes too long to clean up, it means the log cleaner requires more compute resources to catch up with the segment production rate. We can solve that issue by allocating more threads to the log cleaner process by changing the log.cleaner.threads parameter. Importantly, we need to ensure that the computing resources of our server can support the increase in concurrency of the log cleaning process.
3.5. Common Pitfall
Events with randomly generated message keys won’t benefit from the compaction cleanup policy. The compaction cleanup policy is designed to keep only the latest message, removing older and redundant messages that share the same key. When every message in a partition has a unique key, the log cleaner has nothing to compact because there are no duplicate keys.
4. Conclusion
In this article, we’ve learned that Kafka offers two ways to clean up old logs in our topic partition. Firstly, we can use the delete cleanup policy to limit how long our messages stay in the partition. Besides that, we can use the compact policy, which offers a fine-grained, per-record message retention policy.
We’ve also looked at the mechanism of the compact cleanup policy. Concretely, we’ve learned that the compact cleanup policy rewrites dirty log segments to remove duplicated messages with the same key. Additionally, we’ve also explored the different configurations for the compact cleanup policy, including the min.cleanable.dirty.ratio property. Finally, we highlighted that topic events with a randomly generated message key per event won’t benefit from compaction.