

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
IPC Performance Comparison: Anonymous Pipes, Named Pipes, Unix Sockets, and TCP Sockets
Last updated: October 29, 2025
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Overview
When we have multiple processes working together, they may need to communicate. This is called Inter-Process Communication (IPC). In Linux, there are several IPC methods, like pipes and sockets.
In this article, we’ll analyze the performance of different IPC methods. We’ll compare the speed of anonymous pipes, named pipes, UNIX sockets, and TCP sockets. To benchmark each method, we’ll use the socat command.
If you want to jump directly into the results, check section 8, “Comparing the Results”.
2. Introduction and Methodology
Each IPC method has its advantages and disadvantages. For instance, we can’t use anonymous pipes if we want to communicate between two processes running on different computers. Also, each IPC method works differently, making some faster than others. For instance, when we use TCP sockets, the system adds the TCP header to the payload, thus adding some overhead.
To calculate the speed of each IPC method, we’ll write a script to iterate a test several times and calculate the speed in each iteration. Then, we’ll use those results to calculate the average speed of each method.
As we want to compare the results, we should use the same software and parameters with each method, and we should try to differ only in the IPC method. So, we’ll use the socat command in every test. This command allows us to read from and write to files, pipes, and sockets. Also, we’ll always transfer the same number of bytes and the same content.
Finally, we should also take into account the block size we use. The block size determines how much data is transferred at a time, and it is expected that transmitting big blocks of data is faster than transmitting small blocks of data. So, we’ll measure the speed of each method using different block sizes.
For this article, we’ll use the following parameters:
- Input file: /dev/zero
- Transfer size: 2GB
- Block size: 100 bytes, 500 bytes, 10KB, and 1MB
If we need to test some specific use case, we can adjust the parameters to fit our needs.
3. Script Template to Benchmark the Performance
We’ll benchmark the IPC methods using a Bash script in the following sections. So, we’ll use a script template and test all IPC methods with a similar script.
3.1. The Script Template
To calculate the performance, we need to calculate the bitrate of each method. So, for each test, we need to know the transfer size and the time it took to complete the transfer. Then, we can divide the transfer size by the transfer duration to obtain the bitrate.
Also, we’ll test each method with different block sizes, so we need to iterate over the block sizes. And for each block size, we should run the same test several times to calculate the average speed of each method.
Let’s write a script template to calculate the performance:
#!/bin/bash
BYTES=2000000000
BITS=$(($BYTES*8))
BSS=(100 500 10000 1000000)
IF=/dev/zero
OF=/dev/null
N=50
CSV=output.csv
echo "N,BS,BITS/S" > $CSV
for BS in ${BSS[@]}; do
for i in `seq 1 $N`; do
START=$(date +%s%N)
## Here goes the command that we need to benchmark ##
END=$(date +%s%N)
DURATION=$((($END - $START) / 1000000))
BITRATE=$(($BITS * 1000 / $DURATION))
echo $i,$BS,$BITRATE >> $CSV
done
doneThere, we can write the command that we want to measure, and the script will calculate its speed. We can see that we left a blank line with a comment.
3.2. Understanding the Script Template
The script starts out initializing variables that we’ll use to benchmark the performance. There, we can change the variables to fit our needs. For instance, we can change the N variable to run more or fewer iterations or modify the BYTES variable to change the transfer size.
After the initialization, the script iterates over the block sizes we want to test. Then, for each block size, it iterates the same test N times.
We should remember that the Bash arithmetic only supports integers to calculate the transfer duration. So, we multiply the transfer size by 1,000 and divide the result by the transfer duration in milliseconds. That gives us the bitrate in bits per second.
Finally, we can notice the script writes the result to the file specified in the CSV variable. The CSV file will contain the iteration number, the block size, and the bitrate in bits per second.
3.3. Calculating the Average Speed
After running the test, we can parse the CSV file to calculate the average speed. Let’s write a Bash function to read the CSV file and print the average bitrate for each block size:
$ calculate_averages() {
tail -n+2 "$1" | awk -F, '{
bitrate[$2] += $3;
count[$2]++;
}
END {
for (bs in count) {
printf "Block size %s: %f Mbits/s\n", bs, bitrate[bs] / count[bs] / 1000000;
}
}'
}When we call the calculate_averages function, we must give the file name as a parameter. The function calculates the averages using tail and awk. With the tail command, we skip the first line in the CSV that contains the names of each column. Then, we use awk‘s arrays to calculate the average value. In this case, we can use floating-point arithmetic, so we divide by 1,000,000 to obtain the results in megabits per second.
4. Anonymous Pipes
Anonymous pipes are commonly used in the command line. It’s straightforward to communicate between two processes in Bash using the | character.
4.1. Test
So, we can measure the anonymous pipe speed by launching two processes: One process should write to the standard output connected to a pipe, and the other process should read from the standard input connected to the same pipe.
We can do this using the socat command. Let’s see how to launch two socat processes to transfer 2 GB of data from one to the other:
$ socat -b 1000000 OPEN:/dev/zero,readbytes=2000000000 STDOUT | socat -b 1000000 STDIN OPEN:/dev/nullWhen we run that line, both socat commands communicate using an anonymous pipe. The first socat uses a 1 MByte block size, reads 2 GB from /dev/zero, and writes it to the standard output. Simultaneously, the second socat reads from the standard input using a 1 MByte block size and writes it to /dev/null.
Now, we can use the script template from the previous section and write the socat line. Also, we can use variables instead of hardcoding the parameters.
Let’s write a script called anonpipe.sh using the script template to benchmark the anonymous pipes:
#!/bin/bash
BYTES=2000000000
BITS=$(($BYTES*8))
BSS=(100 500 10000 1000000)
IF=/dev/zero
OF=/dev/null
N=50
CSV=anonpipe.csv
echo "N,BS,BITS/S" > $CSV
for BS in ${BSS[@]}; do
for i in `seq 1 $N`; do
START=$(date +%s%N)
socat -b $BS OPEN:$IF,readbytes=$BYTES STDOUT | socat -b $BS STDIN OPEN:$OF
END=$(date +%s%N)
DURATION=$((($END - $START) / 1000000))
BITRATE=$(($BITS * 1000 / $DURATION))
echo $i,$BS,$BITRATE >> $CSV
done
doneAs we see, we changed the CSV variable to anonpipe.csv. We can now run the previous script by running ./anonpipe.sh. Also, we should consider that it takes several minutes to complete the benchmark.
4.2. Results
Once the script has finished, let’s call the function calculate_averages from the previous section with the anonpipe.csv file:
$ ./anonpipe.sh
$ calculate_averages anonpipe.csv
Block size 100: 278.062607 Mbits/s
Block size 500: 1270.474921 Mbits/s
Block size 10000: 8070.641040 Mbits/s
Block size 1000000: 9039.146532 Mbits/sWe can see that the lowest performance was 278 Mbits/s when we used the 100-byte block size, and the highest performance was 9,039 Mbits/s when we used the 1 Mbyte block size.
5. Named Pipes
Named pipes are an alternative to anonymous pipes. We can create a named pipe with the mkfifo command, and it creates a special file that will behave as a pipe. However, we’ll use the socat command to create the pipe if it doesn’t exist.
5.1. Test
Similar to the anonymous pipes example, we can benchmark the named pipe by running two processes in parallel. One process should write from the input and write to the named pipe. The other process should read from the named pipe. We can do this using the socat command and the PIPE: parameter. Let’s see how we can do it:
$ socat -b 1000000 PIPE:namedpipe,rdonly OPEN:/dev/null &
$ socat -b 1000000 OPEN:/dev/zero,readbytes=2000000000 PIPE:namedpipe,wronlyWe first run a socat command in the background that reads from the named pipe called namedpipe and writes to /dev/null. While the first socat process waits for data from the named pipe, we run another socat command that reads 2 Gbytes from /dev/zero and writes it to the named pipe. Also, we configure each pipe as read-only or write-only, accordingly.
Let’s write a script called namedpipe.sh using the script template to benchmark the named pipes:
#!/bin/bash
BYTES=2000000000
BSS=(100 500 10000 1000000)
IF=/dev/zero
OF=/dev/null
N=50
CSV=namedpipe.csv
PIPENAME=namedpipe
echo "N,BS,BITS/S" > $CSV
for BS in ${BSS[@]}; do
for i in `seq 1 $N`; do
socat -b $BS PIPE:$PIPENAME,rdonly OPEN:$OF &
START=$(date +%s%N)
socat -b $BS OPEN:$IF,readbytes=$BYTES PIPE:$PIPENAME,wronly
wait
END=$(date +%s%N)
DURATION=$((($END - $START) / 1000000))
BITS=$(($BYTES*8))
BITRATE=$(($BITS * 1000 / $DURATION))
echo $i,$BS,$BITRATE >> $CSV
done
doneIn this case, we changed the CSV variable to namedpipe.csv. Also, we start to measure the time only after running the first socat command. This is because we aren’t transmitting any data until we run the second socat command. After the second socat finishes, we use wait to wait for the first socat command to finish. We do this to ensure sure all the data was transferred and received from one socat to the other.
We can now run the script to test the named pipes running ./namedpipe.sh and wait until it finishes.
5.2. Results
Once the script has finished, we can call the function calculate_averages with the namedpipe.csv file. Let’s see the result:
$ ./namedpipe.sh
$ calculate_averages namedpipe.csv
Block size 100: 318.413648 Mbits/s
Block size 500: 1475.198028 Mbits/s
Block size 10000: 8843.554059 Mbits/s
Block size 1000000: 9699.212714 Mbits/sWe can notice the named pipe had the lowest speed of 318 Mbits/s when using the 100-byte block size, and its top speed was 9,699 Mbits/s when it used the 1 Mbyte block size.
6. UNIX Sockets
We can communicate between two local processes using UNIX sockets. With this socket type, we bind to a path instead of an IP address and port.
6.1. Test
To benchmark the UNIX socket, we can run two processes in parallel, one writing to the socket and the other reading from the socket. The socat command has two parameters to use the UNIX socket. We can listen to a UNIX socket using the UNIX-LISTEN: parameter. Then, we can connect to a UNIX socket using the UNIX: parameter.
Let’s run two socat commands in parallel that are connected by a UNIX socket called socket:
$ socat -b 1000000 UNIX-LISTEN:socket OPEN:/dev/null &
$ socat -b 1000000 OPEN:/dev/zero,readbytes=2000000000 UNIX:socketThe first socat command runs in the background and listens to the UNIX socket called socket. Then, the second socat command connects to the socket and transfers 2 Gbytes of data from /dev/zero.
Let’s use the script template and write a script called unixsocket.sh to benchmark the UNIX socket:
#!/bin/bash
BYTES=2000000000
BSS=(100 500 10000 1000000)
IF=/dev/zero
OF=/dev/null
N=50
CSV=unixsocket.csv
SOCKET=socket
echo "N,BS,BITS/S" > $CSV
for BS in ${BSS[@]}; do
for i in `seq 1 $N`; do
socat -b $BS UNIX-LISTEN:$SOCKET OPEN:$OF &
START=$(date +%s%N)
socat -b $BS OPEN:$IF,readbytes=$BYTES UNIX:$SOCKET
wait
END=$(date +%s%N)
DURATION=$((($END - $START) / 1000000))
BITS=$(($BYTES*8))
BITRATE=$(($BITS * 1000 / $DURATION))
echo $i,$BS,$BITRATE >> $CSV
done
doneWe can see that we follow a similar idea to the named pipes script. We start to measure the time after we run the first socat. Also, we use wait after the second command finishes its execution. In this case, we set the CSV variable to unixsocket.csv. We can now test the UNIX socket by running ./unixsocket.sh, and then wait until it finishes.
6.2. Results
Once the script has finished, we can call the function calculate_averages with the unixsocket.csv file. Let’s see the result:
$ ./unixsocket.sh
$ calculate_averages unixsocket.csv
Block size 100: 245.992742 Mbits/s
Block size 500: 1184.959553 Mbits/s
Block size 10000: 15885.902502 Mbits/s
Block size 1000000: 41334.862565 Mbits/sIn this case, the lowest bitrate was 245 Mbits/s when the block size was 100 bytes, and the maximum bitrate was 41,334 Mbits/s when the block size was 1 Mbyte.
7. TCP Sockets
Another way to communicate between two processes is by using TCP sockets. In fact, several protocols designed to communicate between two processes over the internet use TCP sockets. We can also use TCP sockets to communicate between two processes on the same computer.
7.1. Test
We can follow the same idea from the UNIX socket script, but we should change the socket type to TCP in this case. So, we should use socat with the TCP-LISTEN: parameter to listen to a port and the TCP: parameter to connect to a port. Let’s change the UNIX socket test, using TCP instead:
$ socat -b 1000000 TCP-LISTEN:9999 OPEN:/dev/null &
$ socat -b 1000000 OPEN:/dev/zero,readbytes=2000000000 TCP:127.0.0.1:9999In this case, the first socat command listens to port number 9999, and the second socat command connects to port 9999 on the localhost IP 127.0.0.1.
Let’s use the script template and write a script called tcpsocket.sh to benchmark the TCP socket:
#!/bin/bash
BYTES=2000000000
BSS=(100 500 10000 1000000)
IF=/dev/zero
OF=/dev/null
N=50
CSV=tcpsocket.csv
PORT=9999
IP=127.0.0.1
echo "N,BS,BITS/S" > $CSV
for BS in ${BSS[@]}; do
for i in `seq 1 $N`; do
socat -b $BS TCP-LISTEN:$PORT,reuseaddr OPEN:$OF &
START=$(date +%s%N)
socat -b $BS OPEN:$IF,readbytes=$BYTES TCP:$IP:$PORT
wait
END=$(date +%s%N)
DURATION=$((($END - $START) / 1000000))
BITS=$(($BYTES*8))
BITRATE=$(($BITS * 1000 / $DURATION))
echo $i,$BS,$BITRATE >> $CSV
done
doneIn this case, the CSV variable is set to tcpsocket.csv. We can now run the script ./tcpsocket.sh to benchmark the TCP socket, and wait until it finishes.
7.2. Results
Once the script has finished, we can call the function calculate_averages with the tcpsocket.csv file. Let’s see the results:
$ ./tcpsocket.sh
$ calculate_averages tcpsocket.csv
Block size 100: 269.562354 Mbits/s
Block size 500: 1284.184400 Mbits/s
Block size 10000: 14798.750616 Mbits/s
Block size 1000000: 36208.454080 Mbits/sIn this last method, we can see the lowest performance was 269 Mbits/s when we used the 100-byte block size. Also, we can notice the fastest speed was 36,208 Mbits/s when we used the 1 Mbyte block size.
8. Comparing the Results
Finally, after measuring the performance of each method, we can now compare them. Let’s plot the results from the previous sections on a chart so we can visualize the performance:
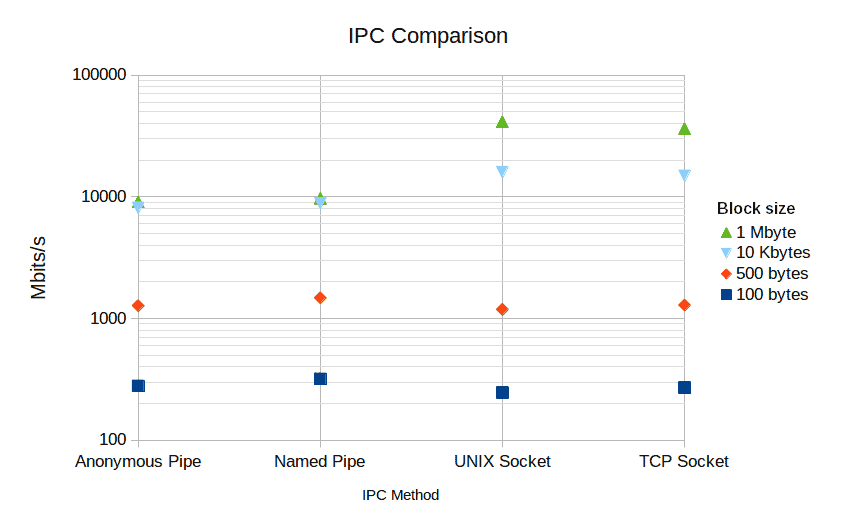
As we can see, the chart shows the four IPC methods we tested on the X-axis and the speed in Mbits/s on the Y-axis. Also, we used a logarithmic scale on the Y-axis.
After analyzing the chart, we can notice that the performance of each method depends on the block size. We can see that pipes are slightly faster than sockets when we use the smallest block sizes of 100 bytes and 500 bytes. However, when we used the biggest block sizes of 10 Kbytes and 1 Mbyte, sockets were faster than pipes.
The fastest IPC method with a 100-byte block size was the named pipe, and the slowest was the UNIX socket. The named pipe transmitted at a speed of 318 Mbits/s, while the UNIX socket transmitted at 245 Mbits/s. So, in relative terms, named pipes are approximately 30% faster than UNIX sockets with a block size of 100 bytes.
When we compare the biggest block size of 1 Mbyte, the fastest IPC method was the UNIX socket, and the slowest was the anonymous pipe. The UNIX socket transmitted at a speed of 41,334 Mbits/s, while the anonymous pipe transmitted at a speed of 9,039 Mbits/s. So, UNIX sockets are approximately 350% faster than anonymous pipes when using a 1 Mbyte block size.
With this information, we can conclude that we should consider the size of the message we want to transmit before deciding which IPC method to use. If we send small messages, named pipes are the fastest. However, if we send big messages, UNIX sockets are the fastest.
9. Conclusion
In this article, we analyzed the performance of four IPC methods. We compared anonymous pipes, named pipes, UNIX sockets, and TCP sockets.
We saw that pipes are faster than sockets when we used a small block size and named pipes the fastest. However, when the block size is big, sockets had a noticeably better performance than pipes, with UNIX sockets being the fastest.