

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
The Differences Between BRE, ERE, and PCRE Syntax in Linux
Last updated: February 16, 2025
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Overview
In this tutorial, we’ll learn the differences among the different flavors of regular expressions, such as BRE, ERE, and PCRE in Linux.
2. Regular Expressions
The regular expression, also known as regex or regexp, is a sequence of characters that defines a search pattern. The search pattern is typically used for matching text and performing manipulation on those matches. To understand its power, let us consider that we have a spending.txt file that contains simple spending data in tabular form:
$ cat spending.txt
date | spending | description
----------------|---------------|------------------------
01032023 | 20$ | restaurant - mcdonalds
02032023 | 10$ | home depot
03032023 | 5.9$ | restaurants
04032023 | 22$ | barber
05032023 | 29.9$ | fitness - weekly pass
06032023 | 2.99$ | 7-eleven
07032023 | 2$ | convenient storesWe can easily extract the row with 20$ in the spending column using the grep command:
$ cat spending.txt | grep -E '20\$'
01032023 | 20$ | restaurant - mcdonaldsBut, what if we want to select rows that are anything between 20$ and 29.99$? In this case, we can derive a search pattern that matches that pattern using a regular expression:
$ cat spending.txt | grep -E '2[0-9]{1}(\.[0-9]{,2})?\$'
01032023 | 20$ | restaurant - mcdonalds
04032023 | 22$ | barber
05032023 | 29.9$ | fitness - weekly passThe regular expression above matches anything that starts with the character “2”, at least 1 character in the range of “0” to “9”, and ends with a dollar sign. In the middle, there is a parenthese expression that accounts for the possibility of the presence of decimal points.
There are several flavors of regular expressions available in Linux, and each of them sometimes supports operators that are not available in the other. Let’s look at the different flavors of regular expression in detail.
3. The Different Flavors of Regular Expressions
In Linux, there are three primary flavors of regular expressions: the basic regular expression (BRE), the extended regular expression (ERE), and the Perl-compatible regular expression (PCRE). The BRE and ERE can be further categorized into POSIX BRE/ERE and GNU BRE/ERE. Before we go into the details of each of the flavors, it’s helpful to first learn how each of them came about and why there is more than 1 flavor of regular expression in the scene.
In the beginning, the BRE codified a series of metacharacters, such as asterisks, and square brackets, to have special meaning in the context of pattern matching. Later on, the ERE extends the idea to include more metacharacters to allow a more flexible matching pattern. These two flavors are then standardized in the POSIX standard.
Later, the GNU projects extend on both the POSIX BRE and ERE to extend them further for their command-line tools such as grep, gawk, and sed. Since they do not fit into the POSIX definition, they are known as GNU BRE and GNU ERE.
Finally, the PCRE is the later revision of regular expression and contains much more advanced functionality. The PCRE is the standard that is most commonly adopted by languages such as PHP, Java, and Javascript, though most of the implementation does not follow exactly the specification and has minor variations.
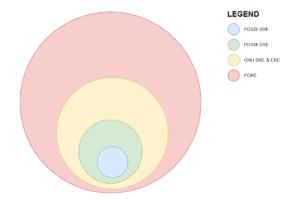
Figuratively, the functionality of POSIX BRE is a subset of POSIX ERE which in turn is a subset of GNU BRE and ERE. At the highest level of all, the PCRE is the superset of all the flavors.
4. POSIX BRE and ERE
The POSIX BRE is considered the oldest regular expression flavor that is still in use today. Therefore, it has the most basic set of operators for pattern matching. Concretely, the POSIX BRE supports the dot (.) metacharacter, the caret (^) and dollar ($) sign anchors, the asterisk (*) and curly braces quantifiers, and bracket expression.
In addition to these operators, the POSIX ERE supports the alternation through the pipe (|) symbol. Furthermore, the POSIX ERE also defines the plus (+) and question mark (?) operators quantifiers to support a 1 or more and zero or 1 matching.
One distinct characteristic of BRE is that backslash must precede some of the metacharacters for it to take on special meaning. Specifically, metacharacters like {, }, (, and ) loses their special meaning without the backslash character. This is in contrast to the ERE, where backslash preceding those metacharacters makes them lose their special meaning.
Let’s look at each of the operators in detail.
4.1. Dot
The dot metacharacter (.) matches any character except for the linebreak. For instance, we can write a pattern to match the texts of Brendon, Brenden, and Brandon:
Br.nd.nIn the expression above, the dot can be thought of as a wildcard and will match any symbol.
4.2. Bracket Expression
The bracket expression can be thought of as a subset of the dot metacharacter. Essentially, the bracket expression allows us to restrict the character we want to match. For example, let’s say we want to match Brendon, Brenden, and Brandon, but not Brundun, we can use the bracket expression to restrict the match of wildcard characters to e, a, and o:
Br[ae]nd[eo]n4.3. Caret and Dollar Anchors
The caret (^) and dollar ($) signs are anchor operators that can match the start and end of the string. For example, we can match only texts that start with the text package using the caret symbol:
^packageTo match text that ends with the text package we’ll use the dollar sign instead:
package$4.4. Curly Braces Quantifiers
The quantifiers are a set of operators that specify the number of times we want to match the preceding character. The most general quantifier syntax is the quantifier using curly braces. It takes on the syntax of {n,m} where n is the minimum amount of preceding characters to match. On the other hand, the m value is the maximum amount of preceding characters to match and is optional. If m is absent, it means the upper bound is not limited.
For instance, we can match the restaurantss, and restaurantsss, but not restaurant or restaurants texts using the curly braces:
restaurants{2,3}4.5. Asterisk, Question Mark, and Plus Quantifiers
Because some of the quantifiers are very commonly used, they have been codified into the standard. These quantifiers include the asterisk, question mark, and plus operator.
The asterisk operator, which is a 0-or-more quantifier, is equivalent to the curly braces syntax of {0,}. Besides that, the 0-or-1 quantifier is defined by the question mark and is functionally the same as {0,1}. Finally, the plus operator defines the 1-or-more quantifier. Functionally, the plus sign is equivalent to {1,}.
One thing to note is that the question mark and plus operators are only available in the POSIX ERE standard.
4.2. Alternation
The alternation operator, through the pipe character, allows us to express an OR-based matching in our expression. For example, let’s say we want to match BrownFox, BrownFish, and BrownBear, but not BrownDog, we can use alternation in our expression:
Brown(Fox|Fish|Bear)5. GNU BRE and ERE
The GNU BRE and GNU ERE are extensions on top of the POSIX BRE and ERE. This means the GNU BRE and ERE are capable of everything from the POSIX equivalent and more. Furthermore, the GNU BRE is functionally the same as GNU ERE since they defined the same set of functions, unlike the GNU’s.
Their only difference is that the GNU BRE requires the backslash character to give special meaning to the same set of metacharacters as GNU ERE.
5.1. Word Boundary
In addition to all the POSIX functionalities, GNU BRE and ERE include support for word boundary using the \b, \B, \<, and \> operators. Specifically, the \b operator specifies the beginning or end of a word, and the \B is the negated version of \b. For example, consider that we have a word-boundary.txt file that consists of 2 lines:
$ cat word-boundary.txt
brownpancakes
brown pancakesWe can select the 2nd row by matching the word brown with a word boundary \b:
$ cat word-boundary.txt | grep -E "brown\b"
brown pancakesOn the other hand, we can select the first row that does not have a word boundary on the text brown using \B:
$ cat word-boundary.txt | grep -E "brown\B"
brownpancakesAdditionally, there are 2 more operators that allow us to match exactly the start or the end of the word. Specifically, the \< operator specifically matches the beginning of a word, and the \> operator matches the end of a word.
5.2. Shorthand Classes
Furthermore, the GNU extensions also support shorthand classes such as \w and \s which offer concise syntax for commonly used character classes. Concretely, we can use the \w syntax to match any alphanumeric values, and is equivalent to the POSIX’s bracket syntax of [a-zA-Z0-9_].
Similarly, the \s syntax is the shorthand for matching spaces, tabs, carriage returns, line feeds, or form feeds and is equivalent to [\t\r\n\f].
6. PCRE
PCRE is the regular expression standard that has the most complete features out of the different flavors in this article. In fact, popular regex engines nowadays usually implement a variation of PCRE standards to offer a more complete regex experience. Let’s look at some of the additional features in PCRE.
6.1. Lookaround
The lookaround operator is a powerful regular expression feature that allows us to perform zero-length assertions. It has 2 variants: the lookahead and lookbehind syntax. For lookahead syntax, there’s a positive and negative version to allow for negation expression. For example, we can write a positive lookahead expression to match the text brown followed by fox without considering the fox as a match:
brown(?=fox)On the other hand, to match the text brown is not followed by the word fish we can use the negative lookahead expression:
brown(?!fish)To look backward instead of forward, we use the lookbackward syntax. To change the expression above such that it matches the text fox that has brown precedes it, we can use the positive lookbackward syntax:
(?<=brown)foxSimilarly, we can match texts with fish that are not right after the word brown using a negative lookbehind:
(?<!brown)fishWithout the lookaround syntax, we have no choice but to obtain the whole brownfish as a match instead of just the word brown.
6.2. Lazy Modifier
By default, all the quantifiers such as ?, *, and {n,} are greedy. In other words, they’ll consume as many matches as possible. Consider that we have a string:
gooooooExpressions such as go+, go*, or go{1,} are greedy when they match the target. Specifically, those expressions will match the entire “goooooo” text despite that they only need to have 1 “o” after the “g” character. By applying the lazy modifier, we can make those expressions consume the minimum tokens they need. Concretely, the “lazy” equivalent for those expressions would be go+?, go*?, and go{1,}?.
7. Conclusion
In this tutorial, we’ve briefly learned how regular expressions allow a flexible pattern matching on text. Then, we learned that there are different flavors of regular expression on Linux, such as BRE, ERE, and PCRE. Furthermore, we’ve seen for BRE and ERE, there’s the POSIX version and the GNU version, and have different operators. Finally, we’ve learned that the PCRE offers even more functionality as compared to the BRE and ERE.