

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this topic, we’ll cover Ukkonen’s algorithm. It’s a space-efficient linear-time algorithm for building suffix trees.
The suffix tree of a string  is a rooted directed tree built out of the suffixes in . Each node in the tree is labeled with a substring of , and no two edges out of the same node start with the same character. Additionally, each suffix ends in a terminal node. To locate a suffix, we need to start from the root node and move along the edges, concatenating their labels in the process until we reach a terminal node.
is a rooted directed tree built out of the suffixes in . Each node in the tree is labeled with a substring of , and no two edges out of the same node start with the same character. Additionally, each suffix ends in a terminal node. To locate a suffix, we need to start from the root node and move along the edges, concatenating their labels in the process until we reach a terminal node.
In our discussion, we assume  is a zero-indexed string. Below is the suffix tree of string
is a zero-indexed string. Below is the suffix tree of string  :
:
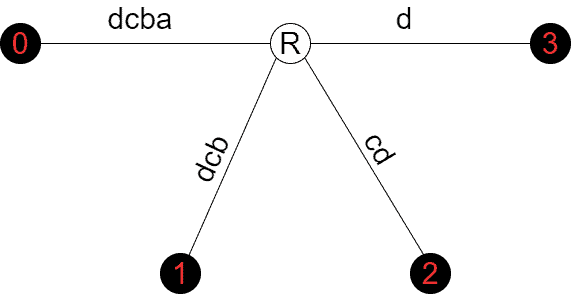
The tree above contains the following suffixes:
 – starts at 3
– starts at 3 – starts at 2
– starts at 2 – starts at 1
– starts at 1 – starts at 0
– starts at 0The root node is denoted by  . Each terminal node is black and contains the starting index of the suffix it represents. For example, the terminal node containing 1 represents suffix
. Each terminal node is black and contains the starting index of the suffix it represents. For example, the terminal node containing 1 represents suffix  which starts at position 1 in .
which starts at position 1 in .
The example above is a primitive suffix tree for a string without repeating characters. Such simple suffix trees don’t contain internal nodes. For complex strings, the suffix tree is complex as well. Below is the suffix tree of string  :
:
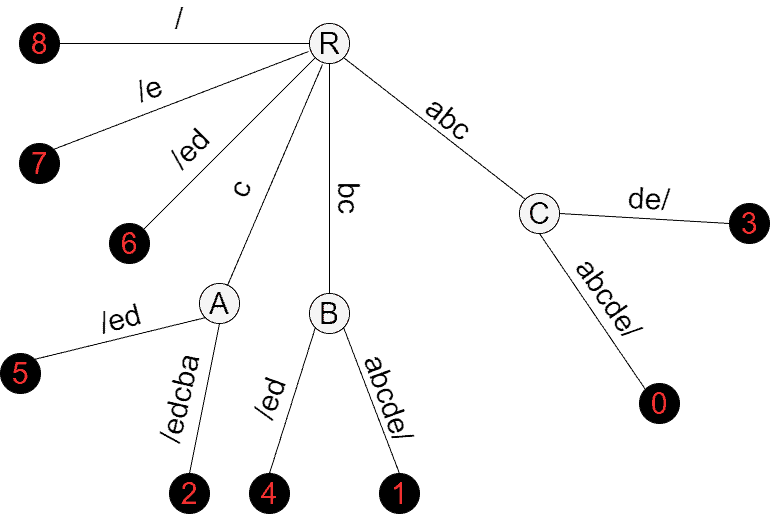
Note that we append the slash symbol at the end of the string. That’s done for the suffixes to end in terminal nodes. Without it, suffixes will end in the middle of edges or in internal nodes. We could actually append any character that is absent in instead of the slash. The suffix tree represents the following suffixes:
 – starts at 8
– starts at 8 – starts at 7
– starts at 7 – starts at 6
– starts at 6 – starts at 5
– starts at 5 – starts at 4
– starts at 4 – starts at 3
– starts at 3 – starts at 2
– starts at 2 – starts at 1
– starts at 1 – starts at 0
– starts at 0It’s very easy to build the suffix tree for strings with non-repeating characters. In such suffix trees, there’re no internal nodes, and a single edge connects each terminal node to the root. Complications arise when characters repeat, and we need clever algorithms that build suffix trees efficiently.
An intuitive approach to building the suffix tree of the given string is to insert each suffix gradually. For example, we can insert the suffixes starting from the shortest suffix and ending with the longest one. We can also insert the suffixes in the opposite order. Or we can even insert them randomly. Anyway, the result is the same suffix tree.
The time complexity of the approaches that directly insert the suffixes in some order is  , where
, where  is the length of : there’re suffixes, and each one is inserted in
is the length of : there’re suffixes, and each one is inserted in  time.
time.
This section describes Ukkonen’s algorithm for building suffix trees. The algorithm builds a series of implicit suffix trees, one for each prefix of . The final implicit suffix tree then appears to be the suffix tree of as the last character of is distinct.
Let’s denote the substring of starting at position  and ending at
and ending at  by
by ![S[i, j]](/wp-content/ql-cache/quicklatex.com-2b0aa570aaa4e1bb23aaed98a59010ff_l3.svg "Rendered by QuickLaTeX.com") . Additionally, let’s denote the implicit suffix tree of prefix
. Additionally, let’s denote the implicit suffix tree of prefix ![S[0, j]](/wp-content/ql-cache/quicklatex.com-9be3075f8331154877299ee5881b43a2_l3.svg "Rendered by QuickLaTeX.com") by
by  . So, the algorithm builds
. So, the algorithm builds  , then
, then  , etc.
, etc.  is built in the end. is built using
is built in the end. is built using  ,
,  .
.
More specifically, here’re the steps of the algorithm:
 , build on top of
, build on top of And below are the steps to build having :
 , add suffix to
, add suffix to As we see, each suffix of is added to to get .
First, we’ll explore the compound parts of the algorithm. Then, we’ll demonstrate the algorithm with an example.
An implicit suffix tree is a tree that is built from the suffix tree by removing the slash, then removing edges without labels and their terminal nodes, then removing internal nodes with a single outgoing edge. Thus, the implicit suffix tree is very similar to the suffix tree in that it contains all the suffixes of the original string. The only difference is that not all the suffixes may end in terminal nodes, some of them may end in internal nodes or even in the middle of edges.
When consists of distinct characters, the implicit suffix tree is the same as the suffix tree. There’s also a weaker condition when the two match: if the last character of has no other entries in the string. In both cases, no suffix is a prefix of another suffix. Below is the implicit suffix tree of string  :
:
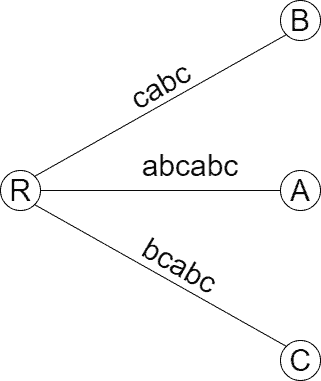
The implicit suffix tree above contains all the suffixes of :
 – ends in the middle of edge (R, B)
– ends in the middle of edge (R, B) – ends in the middle of edge (R, C)
– ends in the middle of edge (R, C) – ends in the middle of edge (R, A)
– ends in the middle of edge (R, A) – ends in terminal node B
– ends in terminal node B – ends in terminal node C
– ends in terminal node C – ends in terminal node A
– ends in terminal node ABesides, the tree also contains strings that aren’t suffixes of , e.g.,  .
.
There’re three suffix extension rules used by the algorithm to get  from
from  ,
,  :
:
get extended by ![S[j]](/wp-content/ql-cache/quicklatex.com-e646b1e646699ecb7c81a202103506e9_l3.svg "Rendered by QuickLaTeX.com") . No additional work is done for such suffixes. doesn’t have continuation starting at position
. No additional work is done for such suffixes. doesn’t have continuation starting at position  when tracking its path down the root. In this case, we need to add a new terminal node, along with a new edge with the label
when tracking its path down the root. In this case, we need to add a new terminal node, along with a new edge with the label ![S[k, j]](/wp-content/ql-cache/quicklatex.com-f8a08286675f67a0243163cb4eae7f61_l3.svg "Rendered by QuickLaTeX.com") leading to it. If label
leading to it. If label ![S[i, k - 1]](/wp-content/ql-cache/quicklatex.com-cabff11e272b6c9353dbc447dfb69381_l3.svg "Rendered by QuickLaTeX.com") ends in an internal node, then no new internal node is added, otherwise, we add an internal node. If ends in the middle of an edge, the edge is split into two parts, an internal node is added between the parts and an outgoing edge with label is added to the new internal node. ends in an internal node or in the middle of an edge, do nothing and go to the next phase.
ends in an internal node, then no new internal node is added, otherwise, we add an internal node. If ends in the middle of an edge, the edge is split into two parts, an internal node is added between the parts and an outgoing edge with label is added to the new internal node. ends in an internal node or in the middle of an edge, do nothing and go to the next phase.If we simply follow the steps of the algorithm, we get an  algorithm for building suffix trees. It’s worse than the straightforward approach discussed earlier. The asymptotic is obvious, as there’re
algorithm for building suffix trees. It’s worse than the straightforward approach discussed earlier. The asymptotic is obvious, as there’re  implicit suffix trees to be built, and each one is built using
implicit suffix trees to be built, and each one is built using  time by inserting O(N) suffixes of the current prefix in O(N) time each.
time by inserting O(N) suffixes of the current prefix in O(N) time each.
We leverage several optimizations to turn the algorithm into a linear one:
This optimization helps to reduce space usage. Instead of keeping the actual substrings for edge labels, we keep the coordinates of substrings in , i.e. the substrings’ start and end indices in .
We can observe that once a suffix is added to an implicit suffix tree, i.e., when it ends in a terminal node, it can be extended automatically by appending the current extension symbol to it. More specifically, we apply Rule 1 for such suffixes by keeping the global end index. The global end is written as the ending index of the edges leading to terminal nodes.
If some substring is present in the current implicit suffix tree, then all the suffixes of must also be present by the definition of the algorithm. Thus, once we observe it, we stop building and move to  .
.
Suffix links are used to add suffixes that only differ in some starting symbols quickly. For example, if suffix is present in the current implicit suffix tree and we’re adding suffix ![S[i, j + 1]](/wp-content/ql-cache/quicklatex.com-d54221d599b32da9c7236fc768fe35bf_l3.svg "Rendered by QuickLaTeX.com") , then the rest of the remaining suffixes
, then the rest of the remaining suffixes ![S[i + 1, j + 1]](/wp-content/ql-cache/quicklatex.com-2bf50d209ff748865377640620092a7e_l3.svg "Rendered by QuickLaTeX.com") ,
, ![S[i + 2, j + 1]](/wp-content/ql-cache/quicklatex.com-114ecafc60c253ab5d65b4d62db8c3ff_l3.svg "Rendered by QuickLaTeX.com") and etc., are added efficiently by using the previously gathered information.
and etc., are added efficiently by using the previously gathered information.
Suffix links enable jumps between the internal nodes and the root. Suffix links point from internal nodes to other internal nodes or to the root node. They are created during the algorithm.
To move fast in the tree, we keep the lengths of the edges. Along with the active state variables described in the following example, this trick enables us to locate suffixes very quickly.
In this section, we’ll build the suffix tree for string step by step using Ukkonen’s suffix tree algorithm. During the process, we maintain the variables related to the active state:
Initially, we have the root node:

Then, we add the single suffix of prefix ![S[0, 0]](/wp-content/ql-cache/quicklatex.com-c99c93af093fa5c86b2481a09ea67fe6_l3.svg "Rendered by QuickLaTeX.com") =
=  :
:
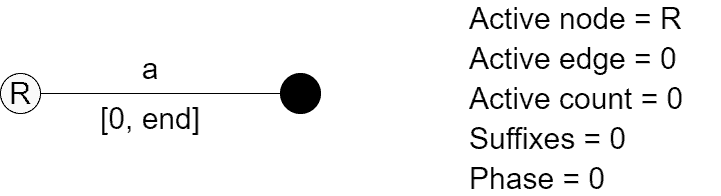
Note that we display the edge labels for verbosity, according to the edge label compression, they’re absent, and only the [start, end] index pair is there. The ‘end’ variable is a placeholder for the global end. Next, we consider prefix ![S[0, 1]](/wp-content/ql-cache/quicklatex.com-d5e44df3848d60290935871dd8b3d09c_l3.svg "Rendered by QuickLaTeX.com") =
=  :
:
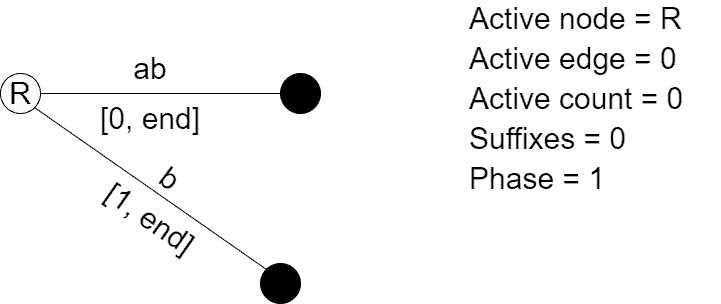
Note how suffix got updated automatically, we literally did nothing to update it. We added suffix  using Rule 2 and finished Phase 1. Phase 2 considers prefix
using Rule 2 and finished Phase 1. Phase 2 considers prefix ![S[0, 2]](/wp-content/ql-cache/quicklatex.com-62b2c599560a6c88ad4e10b37b322969_l3.svg "Rendered by QuickLaTeX.com") =
=  :
:
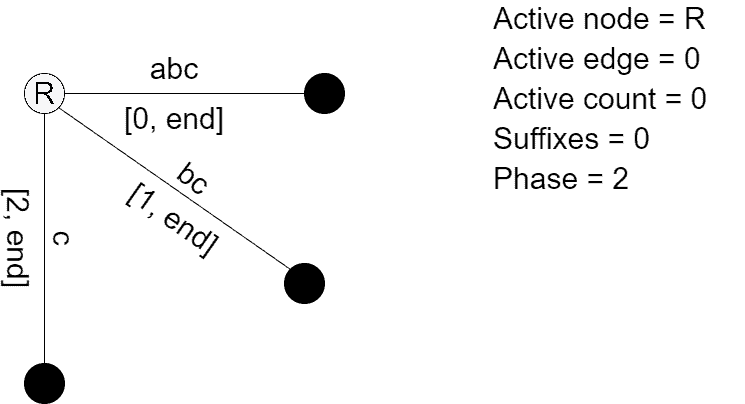
The interesting part starts now. We consider prefix ![S[0, 3]](/wp-content/ql-cache/quicklatex.com-0bd38fb06887400ea7c321e71f1c8bf7_l3.svg "Rendered by QuickLaTeX.com") =
=  , and it’s the first case with a repeating character:
, and it’s the first case with a repeating character:

Suffixes ,  , and
, and  got updated automatically according to Rule 1. While trying to insert suffix , we encountered Rule 3 and terminated Phase 3. The appropriate state variables got updated, and the red arrow now shows the point where the next step starts. Now, prefix
got updated automatically according to Rule 1. While trying to insert suffix , we encountered Rule 3 and terminated Phase 3. The appropriate state variables got updated, and the red arrow now shows the point where the next step starts. Now, prefix ![S[0, 4]](/wp-content/ql-cache/quicklatex.com-da38373979ac68e4533d73f5b79f7862_l3.svg "Rendered by QuickLaTeX.com") =
=  gets processed:
gets processed:

The suffixes ending in terminal nodes got updated automatically. While comparing ![S[4]](/wp-content/ql-cache/quicklatex.com-07c6dd68eb08db7592f6fc015852579b_l3.svg "Rendered by QuickLaTeX.com") = to the current symbol located by the state variables, we saw a match; thus, Rule 3 is applied again. We updated the state variables and terminated Phase 4. Phase 5 is similar to Phase 3 and Phase 4:
= to the current symbol located by the state variables, we saw a match; thus, Rule 3 is applied again. We updated the state variables and terminated Phase 4. Phase 5 is similar to Phase 3 and Phase 4:

We have accumulated three suffixes to be built in the future steps, namely suffixes , , and . Next, we consider prefix ![S[0, 6]](/wp-content/ql-cache/quicklatex.com-d42b4e1499688021a4d35de6c3d46374_l3.svg "Rendered by QuickLaTeX.com") =
=  , and it’s the case where
, and it’s the case where ![S[6]](/wp-content/ql-cache/quicklatex.com-92383b48c14c6a1a20b05f7efb713270_l3.svg "Rendered by QuickLaTeX.com") =
=  and the symbol pointed by the active state differs:
and the symbol pointed by the active state differs:
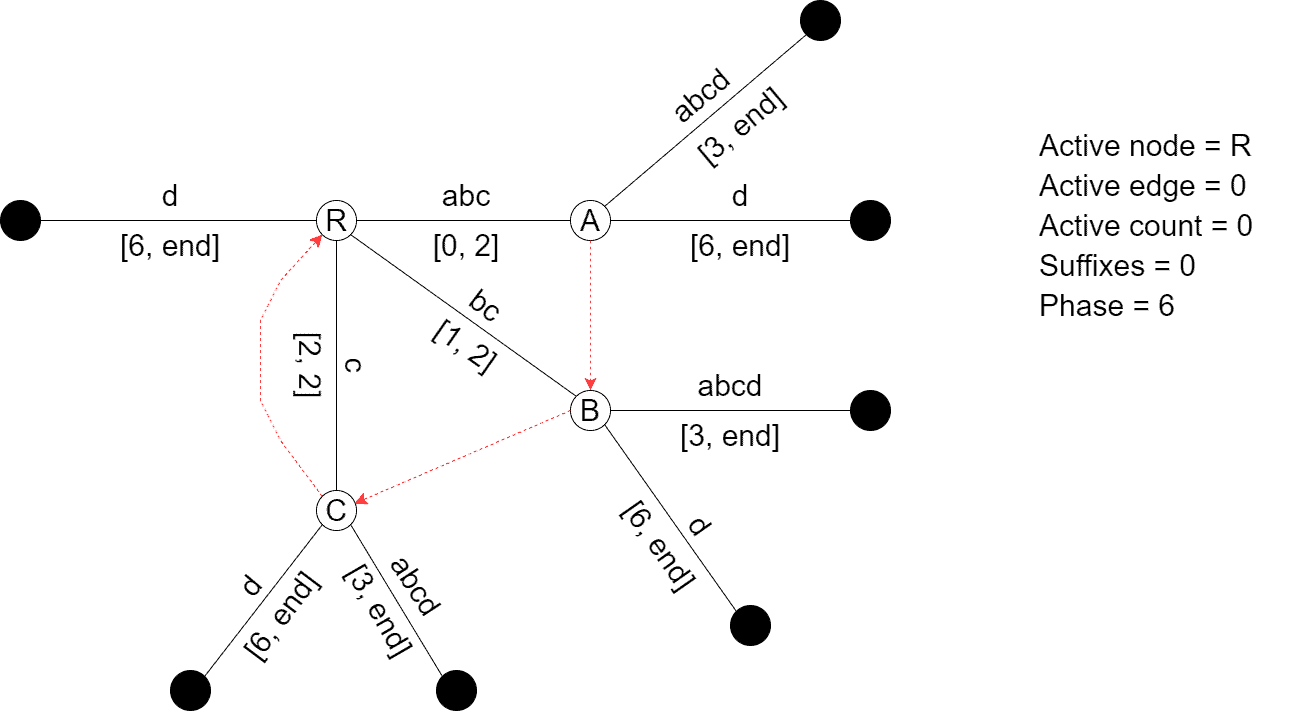
During Phase 6, all the accumulated suffixes were inserted in appropriate places, and suffix links were created. Those suffixes were added according to Rule 2. Additionally, a new branch that represents suffix was added to the root, and the suffix was added using Rule 2. When we create an internal node, we add a suffix link from it pointing to the root node. Afterward, suppose a new internal node is added during the same phase. In that case, the suffix link of the previously created internal node is redirected from the root to the newly created internal node. This way, all the internal nodes created during the same phase point to each other in the order of their creation, with the last one pointing to the root node.
Note how we updated the active state variables to reflect the changes. Generally, if we jump from an internal node to another internal node using a suffix link, the active node gets the value of the internal node that we jump, and the active edge and the active count remain the same. When we jump from an internal node to the root, the root becomes the active node, the active edge gets incremented, and the active count gets decremented.
After Phase 6, node  points to node
points to node  , and node points to node
, and node points to node  . Finally, node points to the root as it was the last internal node created during Phase 6. In the future, if one of the internal nodes becomes an active node after adding a suffix to its path, we follow its suffix link to insert the same suffix on the path of its suffix link node. The process continues until we encounter Rule 3 or we reach the root node and insert the suffix using one of the three rules.
. Finally, node points to the root as it was the last internal node created during Phase 6. In the future, if one of the internal nodes becomes an active node after adding a suffix to its path, we follow its suffix link to insert the same suffix on the path of its suffix link node. The process continues until we encounter Rule 3 or we reach the root node and insert the suffix using one of the three rules.
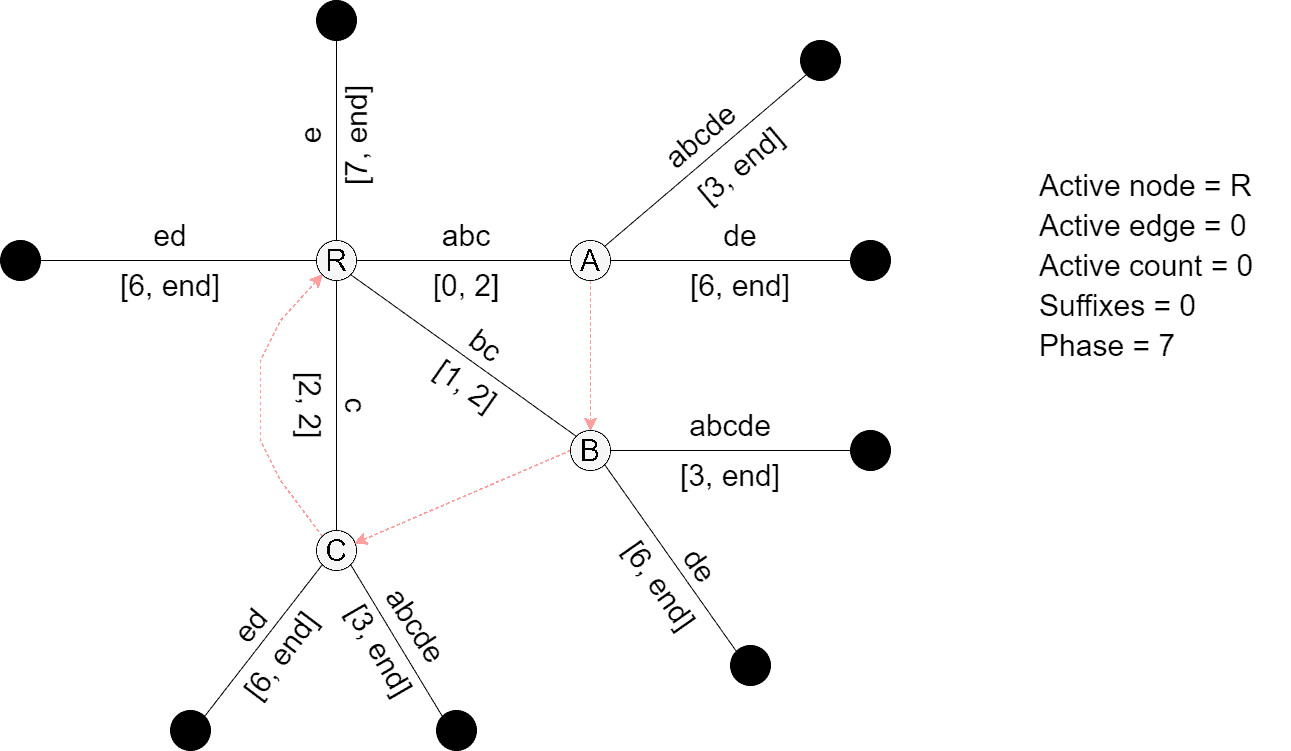
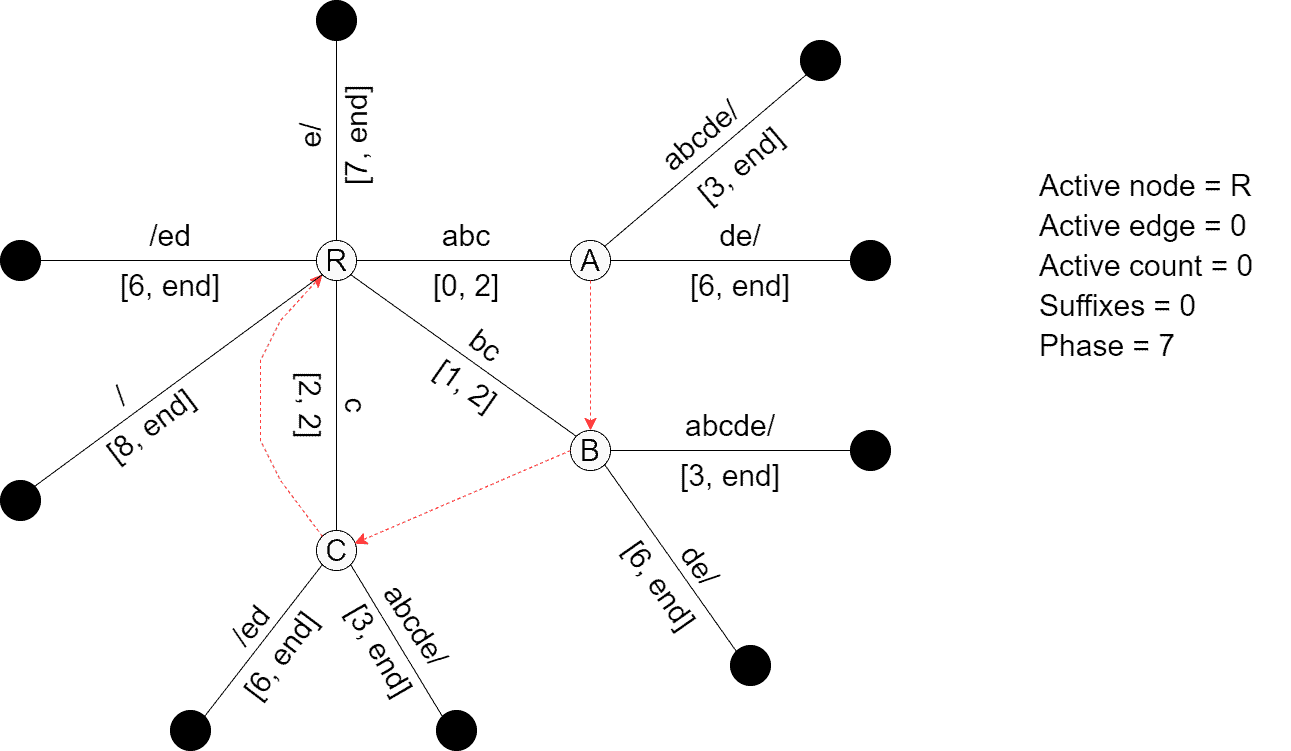
Next, we consider prefix ![S[0, 7]](/wp-content/ql-cache/quicklatex.com-7f788ad6b23dd65e89fdfa0b385a92ab_l3.svg "Rendered by QuickLaTeX.com") = . The active node is the root, the active count is zero, and symbol
= . The active node is the root, the active count is zero, and symbol ![S[7]](/wp-content/ql-cache/quicklatex.com-f275623fa8b1494c5e772dae48ce5fc3_l3.svg "Rendered by QuickLaTeX.com") is distinct, so Phase 7 extends the existing suffixes using Rule 1 and adds suffix
is distinct, so Phase 7 extends the existing suffixes using Rule 1 and adds suffix  using Rule 2:
using Rule 2:
Finally, we add the terminating slash to the tree:
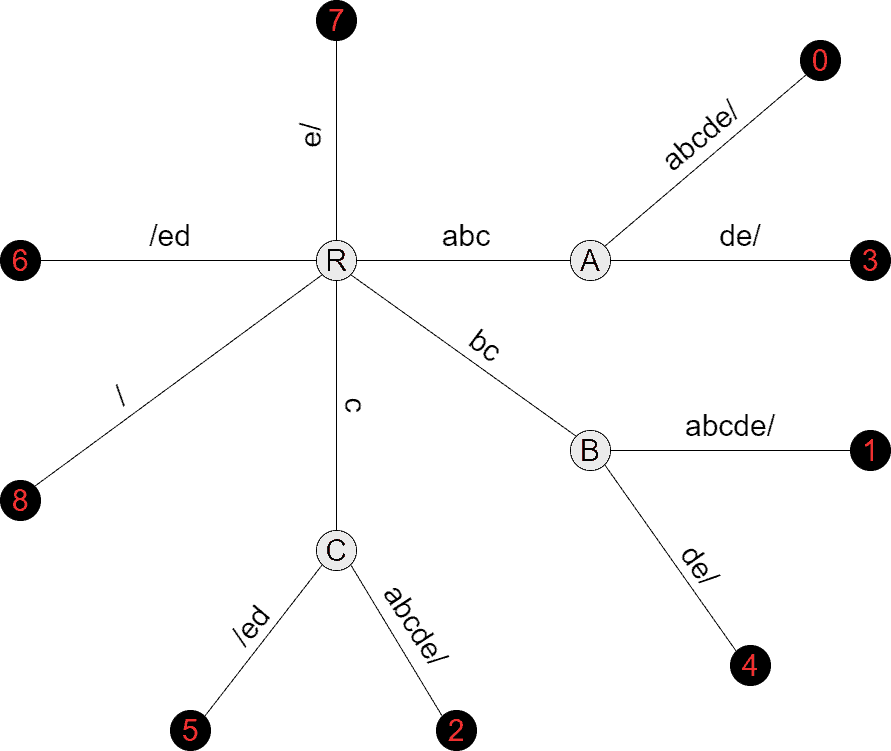
The last step is to traverse the suffix tree using DFS and write the suffix indices in the terminal nodes. We also remove the data used in the suffix tree construction but not used afterward:
The algorithm runs in linear time. The intuition behind that is the algorithm addresses each suffix once in some phase, after which the suffix is extended automatically using Rule 1. Switches between nodes to construct accumulated suffixes take constant time due to all the optimizations discussed previously. For detailed proof of the time complexity, please see Chapter 6 of Algorithms on Strings, Trees, and Sequences, by Dan Gusfield.
In this topic, we’ve discussed Ukkonen’s algorithm for building suffix trees in linear time. We started with a short introduction to suffix trees, then we discussed a straightforward approach to building suffix trees. Next, we’ve described Ukkonen’s algorithm and its compound parts. Finally, we’ve demonstrated the algorithm with a step-by-step example.