

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Algorithm to Find All Subarrays With a Given Sum K
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Overview
In this tutorial, we’ll talk about the problem of finding the number of subarrays with a given sum  .
.
First, we’ll define the problem and provide an example to explain it. Then, we’ll present two different approaches to solving it and work through their implementations and time complexity.
2. Defining the Problem
Suppose we have an array  , and we were asked to count the number of subarrays with a sum equal to .
, and we were asked to count the number of subarrays with a sum equal to .
Recall that a subarray of an array is a consecutive range of the array elements.
Let’s take a look at the following example:
Given an array ![A = [1, 3, 0, 5, -2]](/wp-content/ql-cache/quicklatex.com-4c2e5eec0eb77df90eed9dd1d8b24f83_l3.svg "Rendered by QuickLaTeX.com") and a desired sum
and a desired sum  (red cells define a subarray with sum equal to ):
(red cells define a subarray with sum equal to ):
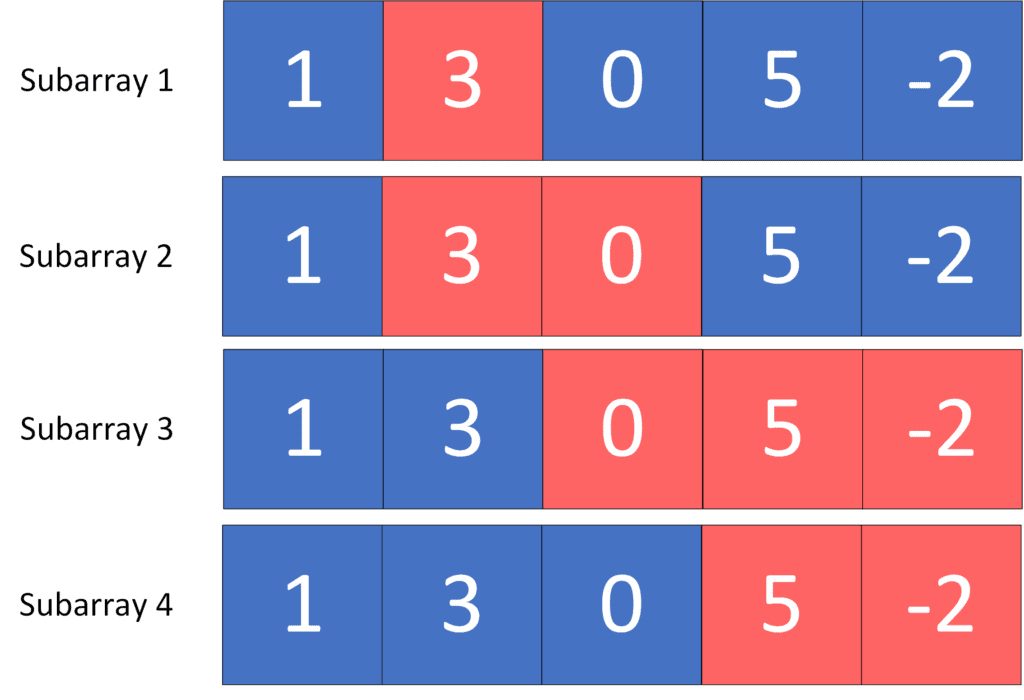
As we can see, the answer here is four because there are  subarrays with a sum equal to
subarrays with a sum equal to  .
.
3. Naive Approach
3.1. Main Idea
The main idea in this approach is to check for each possible subarray if its sum is equal to  , or not.
, or not.
Initially, we’ll go through every possible start of a subarray. Then, we’ll fix it for each start and try all the possible ends. Next, while we’re looking for a valid end, we’ll add the current number to the sum of that subarray. If the sum of the current subarray is equal to at some moment, we’ll increase the answer by one. Otherwise, we’ll ignore that subarray.
Finally, the answer will be equal to the number of subarrays with a sum equal to .
3.2. Algorithm
Let’s take a look at the implementation of the algorithm:
algorithm CountSubarrays(A, K):
// INPUT
// A = a zero-indexed array
// K = the desired sum
// OUTPUT
// The number of subarrays whose sum is equal to K
answer <- 0
for start <- 0 to length(A) - 1:
sum <- 0
for end <- start to length(A) - 1:
sum <- sum + A[end]
if sum = K:
answer <- answer + 1
return answerInitially, we declare the  function that will return the number of subarrays with a sum equal to . The function will have two parameters, , which represents the given array, and , the desired sum.
function that will return the number of subarrays with a sum equal to . The function will have two parameters, , which represents the given array, and , the desired sum.
Initially, we declare the  , which will store the number of valid subarrays. Next, we’ll try to start a new subarray from each position of the given array . Also, we declare
, which will store the number of valid subarrays. Next, we’ll try to start a new subarray from each position of the given array . Also, we declare  , which will store the sum of the subarray that will begin at
, which will store the sum of the subarray that will begin at  .
.
Then, we’ll iterate over all the possible subarray ends. While we move the end pointer, we’ll add the element at the end to the of the current subarray. After that, we’ll check if the current subarray is valid by checking if the is equal to . If so, we increase the by one. Otherwise, the current subarray is not valid.
Finally, the will equal the number of subarrays that have a sum equal to .
3.3. Complexity
The time complexity of this algorithm is  , where
, where  is the length of the given array . This complexity is because we fixed it as a start of a subarray for each position of the given array and iterated overall positions that could be an end to that subarray.
is the length of the given array . This complexity is because we fixed it as a start of a subarray for each position of the given array and iterated overall positions that could be an end to that subarray.
4. Prefix Sum Approach
4.1. Main Idea
The main idea in this approach is to get the advantage of the prefix sum technique (Recall  stores the sum of all elements from the beginning of the array until index
stores the sum of all elements from the beginning of the array until index  ).
).
Initially, we’ll calculate the prefix sum of the given array . Next, for each given array position, we’ll try to fix it as an end to the subarray and get the count of possible subarray starts that make the subarray valid. We can represent the valid starts that give us a valid subarrays end at the fixed position in the following formula:
![\[\boldsymbol{prefixSum_{start - 1} = prefixSum_{end} - K}\]](/wp-content/ql-cache/quicklatex.com-0ede62961268315ab481a0dc43d29f3a_l3.svg "Rendered by QuickLaTeX.com")
Therefore, the number of valid subarray starts that could end at the current position will equal the count of the prefix sum values of positions that come before the  . Then, while we’re moving the pointer, we’ll increase the
. Then, while we’re moving the pointer, we’ll increase the  of the prefix sum value at that position.
of the prefix sum value at that position.
Finally, the will represent the number of subarrays with a sum equal to .
4.2. Algorithm
Let’s take a look at the implementation of the algorithm:
algorithm CountSubarrays(A, K):
// INPUT
// A = the given array
// K = the desired sum
// OUTPUT
// the number of subarrays with a sum equal to K
prefixSum <- an array of size length(A) + 1 filled with zeroes
for i <- 0 to length(A) - 1:
prefixSum[i + 1] <- prefixSum[i] + A[i]
answer <- 0
count <- an empty hash map
for i <- 0 to length(A):
answer <- count[prefixSum[i] - K]
count[prefixSum[i]] <- count[prefixSum[i]] + 1
return answerInitially, we have the same function as the previous approach.
First, we declare the  array, which will store the sum of all elements from the beginning of the given array up to a specific position. We compute the of the given array by applying the formula
array, which will store the sum of all elements from the beginning of the given array up to a specific position. We compute the of the given array by applying the formula  .
.
Second, we declare , which will store the number of valid subarrays. Furthermore, we declare the hashmap, which will store the count of occurrences of a specific value.
Third, we iterate over each position and fix it as the end of the subarray, and we will want to get the count of all possible subarray starts. The subarray that ends at position  will have a valid start
will have a valid start  , if, and only if,
, if, and only if,  . So, we’ll add to the the number of positions with a equal to
. So, we’ll add to the the number of positions with a equal to  . After that, we’ll increase the of the
. After that, we’ll increase the of the  by one.
by one.
Finally, the will equal the number of subarrays that have a sum equal to .
4.3. Complexity
The time complexity of this algorithm is  , where is the length of the given array . This complexity is because we iterate over each element only once.
, where is the length of the given array . This complexity is because we iterate over each element only once.
Note: the previous time complexity could be multiplied by a constant factor representing the hashmap operations’ complexity.
5. Conclusion
In this article, we discussed the problem of finding the number of subarrays with a given sum . We provided an example to explain the problem and explored two different approaches to solve it, where the second one had a better time complexity.
Finally, we walked through their implementations and explained the idea behind each of them.