

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll talk about the problem of finding the number of distinct subsequences of a string.
First, we’ll define the problem and provide an example to explain it. Then, we’ll present two different approaches to solving this problem and work through their implementations and space and time complexity.
Suppose we have a string  , and we were asked to count the number of distinct subsequences in it.
, and we were asked to count the number of distinct subsequences in it.
Recall that a subsequence of a string is a sequence that can be derived from the given string by deleting zero or more elements without changing the order of the remaining elements.
Let’s take a look at the following example:
Given a string  , let’s get all the distinct subsequences of that string (red squares represent the selected characters):
, let’s get all the distinct subsequences of that string (red squares represent the selected characters):
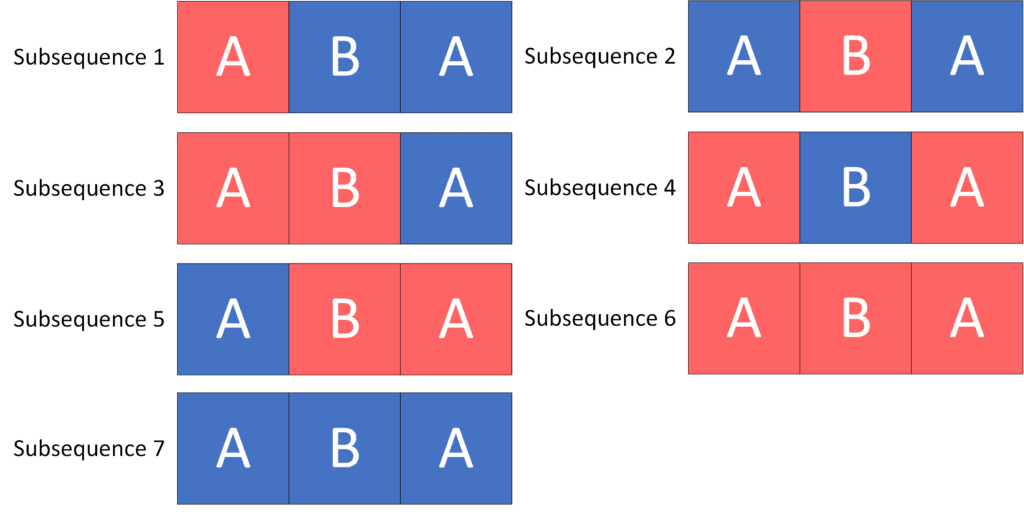
As we can see, there are  different subsequences of the given string .
different subsequences of the given string .
The main idea in this approach is to generate all possible subsequences of the given string. Then, we put them into a set to get rid of the duplicates. In the end, the size of that set will be equal to the number of distinct subsequences we have.
Initially, we’ll have a backtracking method that will generate all the possible subsequences of the given string . Next, for each character in the given string, we’ll try to either pick it in the current subsequence or leave it. Then, when we reach the end of the string, we’ll have one potential subsequence. Thus, we append it to the set that will store the different subsequences.
Finally, the number of distinct subsequences of the given string will be equal to the size of the set.
Let’s take a look at the implementation of the algorithm:
algorithm Backtrack(S, index, cur_subsequence, subsequences_set):
// INPUT
// S = the given string
// index = the current position in the given string S
// cur_subsequence = the current subsequence generated so far
// subsequences_set = the set of all distinct subsequences generated from the given string S
// OUTPUT
// Adds all possible distinct subsequences of S to subsequences_set
if index = length(S):
subsequences_set.add(cur_subsequence)
return
cur_subsequence.append(S[index])
Backtrack(S, index + 1, cur_subsequence, subsequences_set)
cur_subsequence.pop()
Backtrack(S, index + 1, cur_subsequence, subsequences_set)Initially, we declare the  function to generate all possible subsequences of the given string . The function will have four parameters. is the string itself, and
function to generate all possible subsequences of the given string . The function will have four parameters. is the string itself, and  represents the current position in the given string .
represents the current position in the given string .  represents the current subsequence that we have until now, and
represents the current subsequence that we have until now, and  represents all possible distinct subsequences that we could generate from the given string .
represents all possible distinct subsequences that we could generate from the given string .
First, the base case of the backtrack function is when we reach the end of the string , then we append the current  we have to . Second, for each character, we have two choices:
we have to . Second, for each character, we have two choices:
 and move to the next one. When we’re back from that recursive call, we’ll backtrack on appending the character and pop the last character of the .
and move to the next one. When we’re back from that recursive call, we’ll backtrack on appending the character and pop the last character of the .Finally, the size of the  will be equal to the number of distinct subsequences of the given string .
will be equal to the number of distinct subsequences of the given string .
The time complexity of this algorithm is  , where
, where  is the length of the given string . The reason is that for each character of the string, we have two options: to pick or leave it.
is the length of the given string . The reason is that for each character of the string, we have two options: to pick or leave it.
On the other hand, the space complexity of this algorithm is  , where
, where  is the sum of the length of all possible subsequences of the given string . The reason behind this complexity is that for each possible subsequence, we’ll store it in the .
is the sum of the length of all possible subsequences of the given string . The reason behind this complexity is that for each possible subsequence, we’ll store it in the .
The main idea in this approach is to think about a formula to count the number of distinct subsequences of a string without generating those subsequences.
Initially, let’s say that  represents the count of distinct subsequences that could be generated from the first characters of the given string. To compute , we’ll multiply
represents the count of distinct subsequences that could be generated from the first characters of the given string. To compute , we’ll multiply  by
by  since we have two options for each character of the given string: to pick or leave it. Then, we’ll subtract the number of duplicate subsequences that could be generated when adding the current character. Therefore, we can represent the previous idea in the following formula:
since we have two options for each character of the given string: to pick or leave it. Then, we’ll subtract the number of duplicate subsequences that could be generated when adding the current character. Therefore, we can represent the previous idea in the following formula:
![\[\boldsymbol{Count(N) = 2 \times Count(N - 1) - Duplicates}\]](/wp-content/ql-cache/quicklatex.com-1240dd4f2196170d6101e6a339d1794a_l3.svg "Rendered by QuickLaTeX.com")
The problem now is finding the number of duplicates. When we append the current character to the subsequence, we have two duplication cases:
![last[S_i]](/wp-content/ql-cache/quicklatex.com-d8401d85ed2485349ee23ba4f4903290_l3.svg "Rendered by QuickLaTeX.com") is the index of the last appearance to
is the index of the last appearance to  before
before  , then the number of duplicates from adding the
, then the number of duplicates from adding the  character is
character is ![Count[last[S_i]]](/wp-content/ql-cache/quicklatex.com-424b0c4ea2cb99dd6484f5303cf646ca_l3.svg "Rendered by QuickLaTeX.com") .
.Since this problem has overlapping states, we’ll use dynamic programming to solve it.
Finally, the  will represent the number of distinct subsequences of the given string .
will represent the number of distinct subsequences of the given string .
Let’s take a look at the implementation of the algorithm:
algorithm CountSubsequences(S):
// INPUT
// S = the given string
// OUTPUT
// The number of distinct subsequences of the string S
DP <- an empty array of length (length(S) + 1)
last <- an array of with length(Alphabet) elements equal to -1
DP[0] <- 1
for i <- 1 to length(S):
DP[i] <- 2 * DP[i - 1]
if last[S[i]] != -1:
DP[i] <- DP[i] - DP[last[S[i]]]
last[S[i]] <- i
return DP[length(S)]Initially, we have the  function that will return the number of distinct subsequences of a string. It has one parameter , which represents the given string.
function that will return the number of distinct subsequences of a string. It has one parameter , which represents the given string.
First, we declare the  array, which will store the number of distinct string subsequences up to a specific position. Also, we declare
array, which will store the number of distinct string subsequences up to a specific position. Also, we declare  array which stores the position of the last time a specific character appears. Initially, all of its values equal
array which stores the position of the last time a specific character appears. Initially, all of its values equal  .
.
Second, we set the value of ![DP[0]](/wp-content/ql-cache/quicklatex.com-876b8d783d73ba3ae14ad43e87fbe844_l3.svg "Rendered by QuickLaTeX.com") to
to  , which represents the empty subsequence. Next, for each character, we have two options; either to pick or leave it. Therefore, we multiply the answer of the previous position by . Then, we check if the current character occurred before. If so, we subtract the answer of that position from the current answer. After that, we update the value of to equal the current position.
, which represents the empty subsequence. Next, for each character, we have two options; either to pick or leave it. Therefore, we multiply the answer of the previous position by . Then, we check if the current character occurred before. If so, we subtract the answer of that position from the current answer. After that, we update the value of to equal the current position.
Finally, the ![DP[length(S)]](/wp-content/ql-cache/quicklatex.com-e296d6058f9dc2eaa82354c1f684ecaa_l3.svg "Rendered by QuickLaTeX.com") will have the number of distinct subsequences of the given string .
will have the number of distinct subsequences of the given string .
The time complexity of this algorithm is  , where is the length of the given string . The reason behind this complexity is that we iterate over each character only once.
, where is the length of the given string . The reason behind this complexity is that we iterate over each character only once.
The space complexity of this algorithm is  , where is the length of the given string and
, where is the length of the given string and  is the size of the alphabet. The reason is that for each position of the given string, we store the answer, and for each possible character, we store the index of the last time it appears.
is the size of the alphabet. The reason is that for each position of the given string, we store the answer, and for each possible character, we store the index of the last time it appears.
In this article, we discussed the problem of finding the number of distinct subsequences in a given string. First, we provided an example to explain the problem. Then, we explored two different approaches to solve it, where the second one had a better time and space complexity.
Finally, we walked through their implementations and explained the idea behind each of them.