Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 26, 2025

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll discuss the difference between internal and external sort.
If the data sorting process takes place entirely within the Random-Access Memory (RAM) of a computer, it’s called internal sorting. This is possible whenever the size of the dataset to be sorted is small enough to be held in RAM.
For sorting larger datasets, it may be necessary to hold only a smaller chunk of data in memory at a time, since it won’t all fit in the RAM. The rest of the data is normally held on some larger, but slower medium, like a hard disk. The sorting of these large datasets will require different sets of algorithms which are called external sorting.
Following are few algorithms that can be used for internal sort:
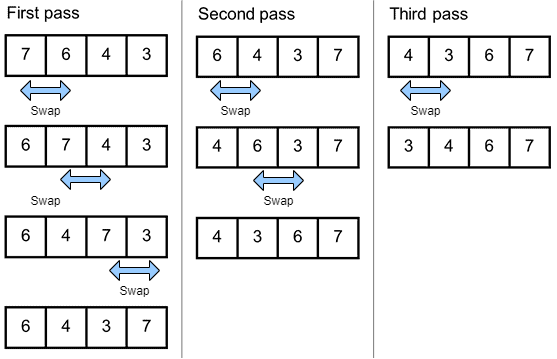
It’s a simple sorting algorithm that repeatedly steps through the list, compares adjacent elements, and swaps them if they’re in the wrong order. More about it can be found in another article:
The algorithm loops through the list until it’s sorted:
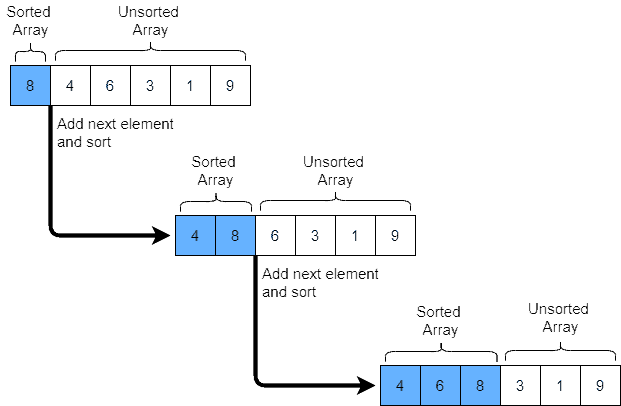
This sorting algorithm works similarly to the way to sort playing cards. The dataset is virtually split into a sorted and an unsorted part, then the algorithm picks up the elements from the unsorted part and places them at the correct position in the sorted part as shown below:
To learn more, please check our article.
This sorting algorithm picks up a pivot element, then partitions the dataset into two sub-arrays, one sub-array is greater than the element and another sub-array is less than the element. The same process is repeated for sub-arrays till the dataset is sorted as shown below:
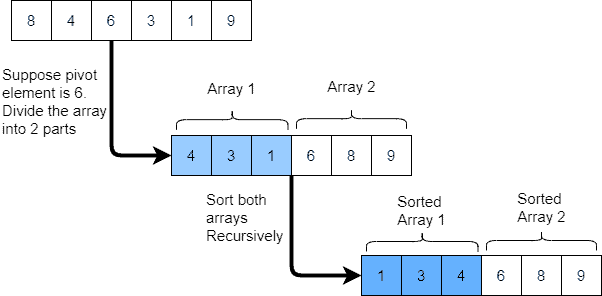 Please check our article to learn more. The space complexity of all these algorithms is O(
Please check our article to learn more. The space complexity of all these algorithms is O( ) which means that the space requirement goes up with the size of the dataset.
) which means that the space requirement goes up with the size of the dataset.
External sort requires algorithms whose space complexity doesn’t increase with the size of the dataset. While the space complexity of Merge Sort is O(), we can optimize it to O( )
)
The following diagram has the high-level data flow to sort a large dataset of 50 GB using a computer with RAM of 8GB and Merge Sort Algorithm:
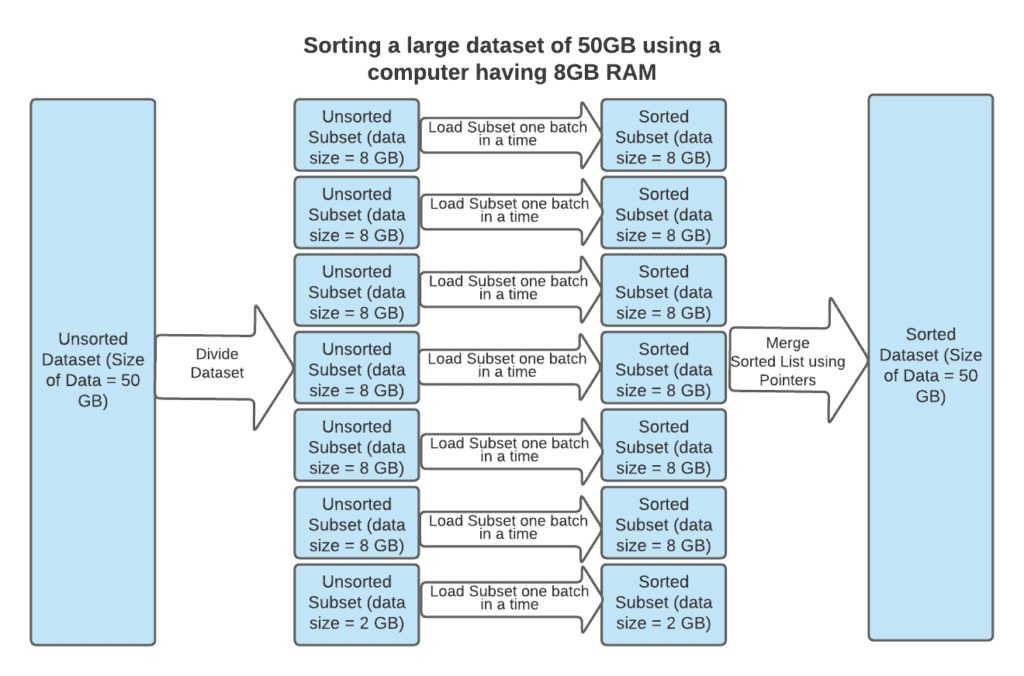
It contains the following steps:
) as it doesn’t increase with the size of the dataset.). The size of these subsets is less than 8GB, it’ll require the same amount of memory to sort them.) and it doesn’t increase with the size of the dataset.We’ll process the following example using this method:
A S O R T I N G A N D M E R G I N G E X A M P L E
We’re assuming that the computer can store 10 elements.
The first step would be to divide the dataset into 3 subsets and they’re loaded in an external disk.
Then, as a part of step 2, we’d:
Then, finally:
Initialize the 3 pointers (one each input subsets) and 1 for output. Pointer for 1st Subset, 2nd Subset, and 3rd Subset is 1. Also, the pointer for the output dataset is 1.
A A A D E E E G G G I I L M M N N N O P R R S T X
In summary, we use internal sorting when the dataset is relatively small enough to fit within the RAM of the computer and external sorting when the dataset is large and it utilizes algorithms that have minimum space complexity.