

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this article, we’ll explain preemptive and non-preemptive scheduling, highlighting their advantages and disadvantages.
A Scheduler is the OS component that decides which process will use the CPU at any point in time. The scheduler acts in four cases:
The first two scenarios are straightforward. A process in the ready queue will be chosen for execution. Non-preemptive scheduling allows switching only in these two cases. Preemptive scheduling admits the third and fourth scenarios. They are trickier because there are two ways a running process can move to the ready state, which gives the scheduler different options.
This is the type of scheduling algorithm in which a process runs till it finishes or goes to the wait state. We can’t interrupt it while it’s running.
Examples of non-preemptive scheduling algorithms include the popular first-come-first-serve (FCFS), in which the order of execution is strictly based on the arrival time. As the name implies, the first to arrive is the first to be served.
Another example is the shortest-job-first (SJF) algorithm which gives priority to the process with the shortest time required for completion. Here, the shortest process runs to completion before the next shortest job takes over the CPU.
All non-preemptive scheduling algorithms follow the same pattern:
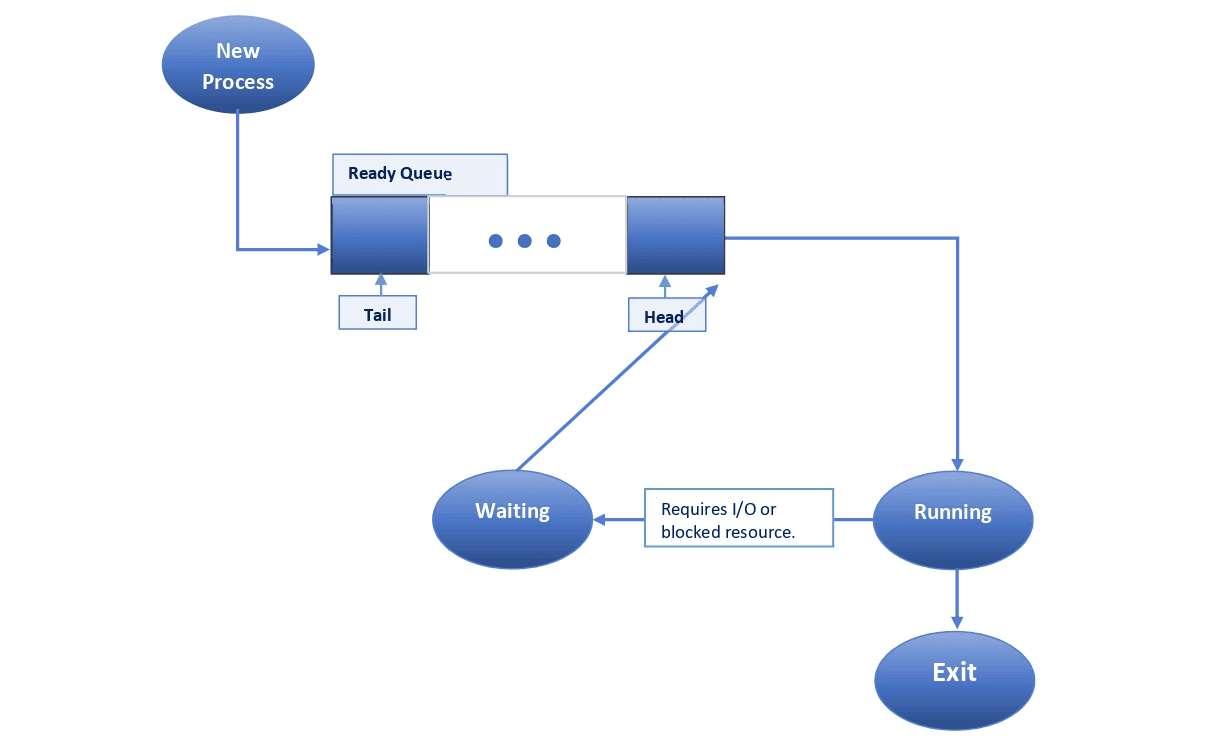
A new process is inserted at the tail of the queue (typically in FCFS). Based on the specific algorithm, a process is selected for execution. The selected process continues until completion without any interruption.
However, if the process requires any I/O operation or some blocked resource while running, it will switch to the waiting state. On completion of the I/O operation or receipt of the needed resource, the process immediately returns to the top of the queue.
Non-preemptive scheduling has minimal computational overhead and is very simple to understand and implement. Additionally, it has higher throughput (i.e., the volume of processes that the CPU executes in a certain length of time).
However, it has certain shortcomings.
The average response time (time between arrival and first scheduled execution) in non-preemptive scheduling is definitely poor. This is because every process has to wait for all the processes ahead of it to complete before it can access the CPU.
It is also considered a very rigid scheduling algorithm owing to the fact that it insists on a process holding to the CPU until it’s completed. That way, critical processes may be denied access to the CPU.
Another very significant disadvantage associated with this type of scheduling is the difficulty in handling priority scheduling. This is so because a process cannot be preempted. Let’s suppose a less important process with a long burst time (time needed to complete execution) is running. Then, a critical process (very high priority) arrives in the queue. This becomes a difficult scenario since a running process cannot be interrupted – making it difficult to handle priority scheduling.
Deadlock is another drawback we associate with non-preemptive scheduling. If process “A” holds the resource that process “B” needs to continue and vice-versa, and preemption isn’t possible, then deadlock is bound to happen. Non-preemption is one of the necessary preconditions for deadlock.
Here, the scheduler allocates the CPU to a process for a set period. After the time period passes, the process is interrupted and moves to the ready state.
Therefore, preemptive scheduling is when a process transitions from running or waiting to ready states. It considers priority in switching processes, giving room for a running process to be interrupted.
An example of a preemptive algorithm is Round-Robin. It gives all processes equal priority and assigns them equal time periods in a round or circular order, as the name implies. Another example is Shortest-Remaining-Time-First (SRTF), which gives priority to the process with the shortest time left to completion.
This is how preemptive scheduling works in general:
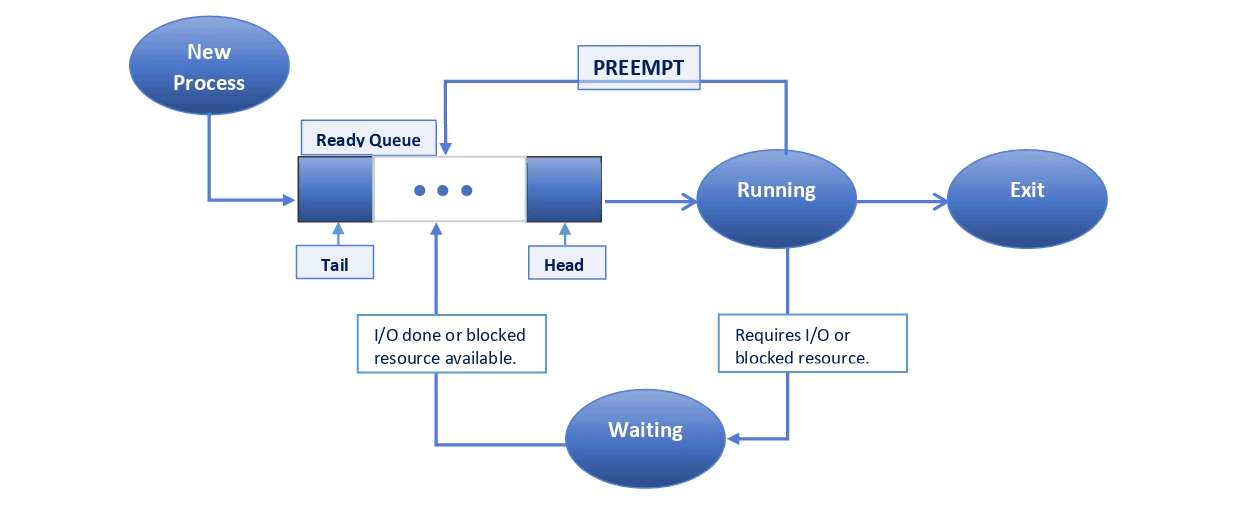
Once the allotted time slice is over or there is a higher-priority process ready for execution (depending on the algorithm), the running process is interrupted, and it switches to the ready state and joins the ready queue.
Also, whenever a process requires an I/O operation or some blocked resource, it switches to the waiting state. On completion of I/O or receipt of resources, the process switches to the ready state and joins the ready queue.
The selection of the next process to be executed depends on the specific algorithm in use.
Preemptive scheduling has a lot of advantages:
It has some disadvantages too:
Let’s use a table to clearly highlight the differences between the two concepts:
| Preemptive Scheduling | Non-preemtpive Scheduling |
|---|---|
| It allocates the CPU to a process for a set period. | It allocates the CPU to process until it finishes or goes to a wait state. |
| A process can be interrupted (stopped) while being executed. | A running process cannot be stopped (interrupted) while running. |
| A process can transit from running to the ready state or from waiting to the ready state. | A process can only transition from running to the waiting state or terminates. |
| Preemptive scheduling is flexible. A critical process accesses the CPU without delay. | It is rigid. It insists on a running process completing before any other process accesses the CPU. |
| A low-priority process can suffer starvation if high-priority processes arrive simultaneously. | Execution of a process with a high burst time can result in starvation processes will suffer starvation. |
| Process scheduling has associated overheads. | No overheads] related to scheduling. |
| High CPU utilization | Low CPU utilization |
| Examples include round-robins, SRTM, priority-scheduling (preemptive version) | Examples include FCFS, SJF, and priority scheduling. |
In this article, we talked about preemptive and non-preemptive scheduling techniques and how they differ from each other.
The latter ones enable a process to execute until it ends or switches to a wait state when it requires some I/O operations/blocked resources. In contrast, the former type of scheduling assigns the CPU to a task for a specific duration, and a process can be interrupted while executing.