Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: May 30, 2023

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In theoretical computer science, formal languages are used to model different types of computation and to study the properties of algorithms and automata. Regular languages, context-free languages, and Turing machine languages are some common examples of formal languages used in theoretical computer science.
In this tutorial, we’ll discuss regular languages – a class of formal languages that finite automata can recognize. We’ll also discuss regular languages’ characteristics, examples, and limitations.
Regular languages are formal languages that regular expressions can describe and can also be recognized by finite automata. They are used to define sets of strings, such as sequences of characters or words, that follow specific patterns.
They are important in computer science and theoretical computer science because they form a foundation for understanding the theory of computation and the design of compilers and other software tools.
Formally, a regular language can be defined as the collection of all strings that are recognized by a finite automata (FA).
An FA is a 5-tuple  , where:
, where:
 stands for a finite number of states
stands for a finite number of states stands for a finite alphabet, representing the input symbols
stands for a finite alphabet, representing the input symbols stands for the transition function which maps
stands for the transition function which maps  to
to  stands for the initial state. It is one of the elements of
stands for the initial state. It is one of the elements of  stands for the set of final states. F is also a subset of .
stands for the set of final states. F is also a subset of .FAs and regular expressions specify patterns or rules that define a language, such as sequences of characters that must or must not appear in the strings. The words in a regular language must follow the rules specified by the finite automaton or regular expression to be part of the language.
Some common examples of regular languages include:
Regular languages have several useful properties. Let’s discuss some of these properties.
Regular languages are closed under union, concatenation, and Kleene star (zero or more repetitions). This means that if two regular languages are combined using one of these operations, the resulting language will also be regular.
 and
and  be regular languages, then
be regular languages, then  is a regular language and be regular languages, then
is a regular language and be regular languages, then  is a regular language
is a regular language be a regular language, then
be a regular language, then  is a regular language
is a regular languageRegular expressions are a compact and convenient way to define regular languages. They use a set of special characters and operators to represent different types of strings and sets of strings.
Let’s consider the language defined by all strings that consist of an even number of 0’s. One way to define this language is by using a regular expression, as follows:

In this expression, the Kleene star operation “ “ matches any number of 1’s, while the inner expression “
“ matches any number of 1’s, while the inner expression “ ” ensures the occurrence of an even number of 0’s and any number of 1’s. . The outer Kleene star operation ensures that the inner expression is repeated any number of times.
” ensures the occurrence of an even number of 0’s and any number of 1’s. . The outer Kleene star operation ensures that the inner expression is repeated any number of times.
A regular language can be recognized by a finite automata, which is a simple machine model consisting of states, transitions, and an initial and final state. Conversely, every regular language can be expressed using finite automata.
In the example we considered in section 3.2, an equivalent nondeterministic finite automaton (NFA) is shown next using a finite automata diagram (also known as a state diagram):
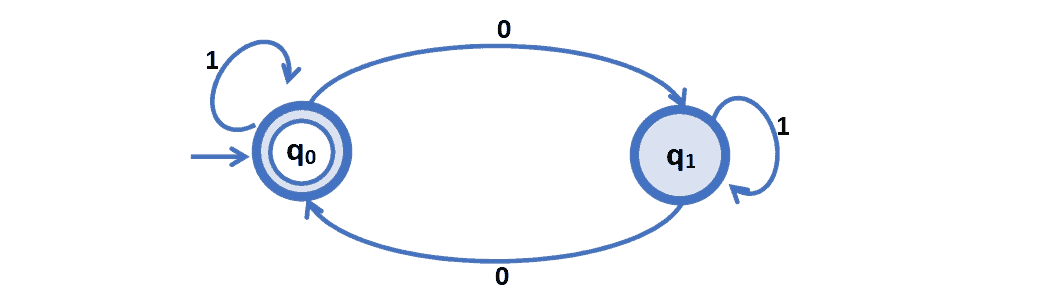
The NFA will only accept strings that end in the state  , corresponding to an even number of 0’s in the string.
, corresponding to an even number of 0’s in the string.
There are several methods to determine whether a language is regular or not.
The pumping lemma puts forward that for a regular language , there exists a constant “pump length” such that any string in the language can be decomposed into three parts and these parts can be repeated any number of times (by “pumping” the middle part) while still being in the language.
This can be stated mathematically as follows:
Let be a regular language, and  be the constant “pump length” specified by the pumping lemma. Then, for any string
be the constant “pump length” specified by the pumping lemma. Then, for any string  in such that
in such that  , it can be decomposed into three parts:
, it can be decomposed into three parts:

where the following conditions must hold:


 is in
is in The Myhill-Nerode theorem states that a language is regular if and only if the number of states in its minimal DFA (deterministic finite automata) is equal to that of its equivalent minimal NFA. If a language can be shown to have an infinite number of inequivalent strings, then it is not regular.
If a language can be shown to have an infinite number of inequivalent strings, then it is not regular.
The theorem is based on the concept of “inequivalent strings,” which are strings that are distinguishable by the minimal DFA. The theorem states that if there are an infinite number of inequivalent strings in a language, then that language is not regular.
Mathematically, let be a language and a set of states in a DFA. Then the Myhill-Nerode theorem is stated as:
is regular if and only if there exists a DFA such that  and
and  , where
, where  is the number of inequivalent strings in with respect to the DFA.
is the number of inequivalent strings in with respect to the DFA.
The closure property ensures that all regular languages result in a regular language when subjected to operations such as union, concatenation, and Kleene star. This implies that if a language is not closed under these operations, it is not regular.
If a language can be proven to be equivalent to a CFL, it is not regular. This is because CFLs are more powerful than regular languages and can describe a wider range of language structures.
There are many ways regular languages are used in computer science and related fields. A few examples include:
Limitations of regular languages include:
Regular languages are a fundamental class of formal languages, but they are not powerful enough to describe many of the languages that arise in practice. They are useful for simple pattern matching and lexical analysis, but more complex languages require more powerful models
In this article, we discussed regular languages – a class of formal languages that finite automata can recognize. We also discussed regular languages’ characteristics, practical applications, and limitations.
Regular languages form a foundation for understanding the theory of computation and the design of compilers and other software tools. However, regular languages are a limited class of formal languages. They are less powerful than other classes, such as context-free languages and context-sensitive languages.