Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Differences Between Disaster Recovery and Backup
Last updated: March 11, 2023

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Overview
In this tutorial, we’ll learn about disaster recovery and backup. Before specifically talking about backups and disaster recovery, it is relevant to highlight that they are solutions that work together to guarantee business continuity.
2. What Is a Backup?
Backup refers to manually or automatically making a copy of data (i.e., creating an image of a Linux system).
Backups can save businesses from catastrophic data loss because of data corruption, a permanent hard drive failure, and a system crash. In addition, the accumulated backed-up data is an archive. Archives are essential in tax reporting and audits.
3. What Is Disaster Recovery?
Disasters can be natural or man-made. Natural disasters include tornados, flooding, fires, power outage, and hardware failures (i.e., a broken network adapter). Man-made disasters include application bugs, accidental data deletion, and hazardous material spills.
Disaster recovery refers to the process of bringing back up the application, data, and resources after a disaster.
Disaster recovery processes include a failover to another node or another storage device. The application remains running on the standby node until the production node is functional again. The application accesses the data from the standby storage device until the production storage device is functional again.
4. Differences Between Disaster Recovery and Backup
In this section, we’ll see the differences between disaster recovery and backup.
4.1. Solution Goal
The goals of taking a backup and running a disaster recovery solution are nearly identical. They both aim to protect a business from failure.
Backups aim to restore data (data includes small and big applications, development data, and production database) in cases in which it’s accidentally deleted, lost, encrypted due to a ransomware attack, or damaged. System snapshots are crucial in the event of system corruption.
On the other hand, disaster recovery solutions aim to keep the business application highly available by eliminating single points of failure (SPOF) (such as node failures, network device failures, and storage device failures). SPOFs occur from disasters (see above). An alternative would be to restore from a backup or a system snapshot instead of failing over to another node, network device, or storage device, but that will take time. When there is a running production application, a business wants minimal downtime.
The figure below shows a backup configuration:
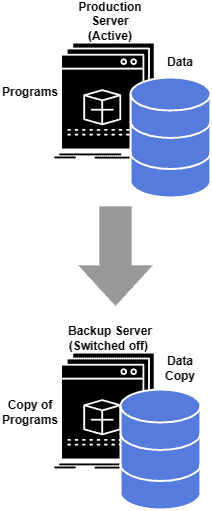
4.2. Data Replication
System engineers take backups at a point in time (for example, every hour or once per month). Whereas, in disaster recovery, the solution replicates the application state and storage data from the production site to the standby site constantly. The data in the standby site is consistent with the data in the production site.
For instance, Metro Mirror is a solution that keeps data consistent between the two storage units. The disaster recovery solution below uses Metro Mirror:
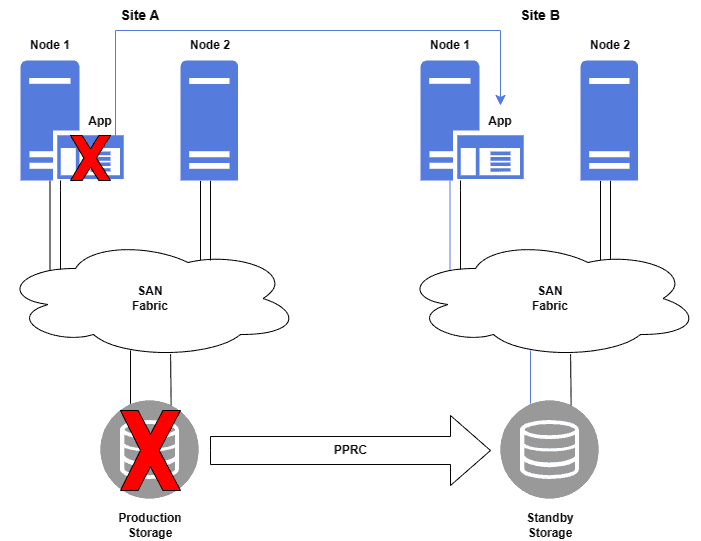
4.3. Automation
Both processes of backup and restoration (of a backup) are almost always manual. Whereas in a disaster recovery solution, the failover processes are automatic.
4.4. Implementation Time and Costs
The time taken by an engineer to plan and implement a disaster recovery solution is more than the time taken to perform a backup or a restore. The engineer has to brainstorm all the SPOFs in the production environment, figure out how to eliminate all SPOFs, and then actually set up the proposed SPOF solutions.
For a backup, the costs include the storage device and maintenance. The costs of a disaster recovery solution are much higher. A disaster recovery solution requires an additional node, an additional storage device, and even additional sites. Moreover, the engineering staff costs to design an optimal working solution.
5. Conclusion
In this article, we gave definitions of backup and disaster recovery and then discussed the differences between the two solutions.