Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 26, 2025

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
One of the most common problems in multithreaded applications is the problem of race conditions.
In this tutorial, we’ll learn what race conditions are, the ways to detect them, and the approaches to handle them.
By definition, a race condition is a condition of a program where its behavior depends on relative timing or interleaving of multiple threads or processes. One or more possible outcomes may be undesirable, resulting in a bug. We refer to this kind of behavior as nondeterministic.
Thread-safe is the term we use to describe a program, code, or data structure free of race conditions when accessed by multiple threads.
Let’s consider a simple function for performing a funds transfer between two bank accounts:
algorithm Transfer(amount, accountSource, accountTarget):
// INPUT
// amount = Amount to be transferred
// accountSource = Source account for the transfer
// accountTarget = Target account for the transfer
// OUTPUT
// Transfers the specified amount from the source to the target account if possible
if accountSource.balance < amount:
return
accountTarget.balance <- accountTarget.balance + amount
accountSource.balance <- accountSource.balance - amountIn this implementation, we thought thru the possibility to attempt to withdraw funds that are not available at the source account. Thus, we have a check for the amount available, and we expect the account balance would never go below zero. Let’s say we have accounts A and B, each having a balance of 500, and we perform two attempts to transfer 300 from A to B:
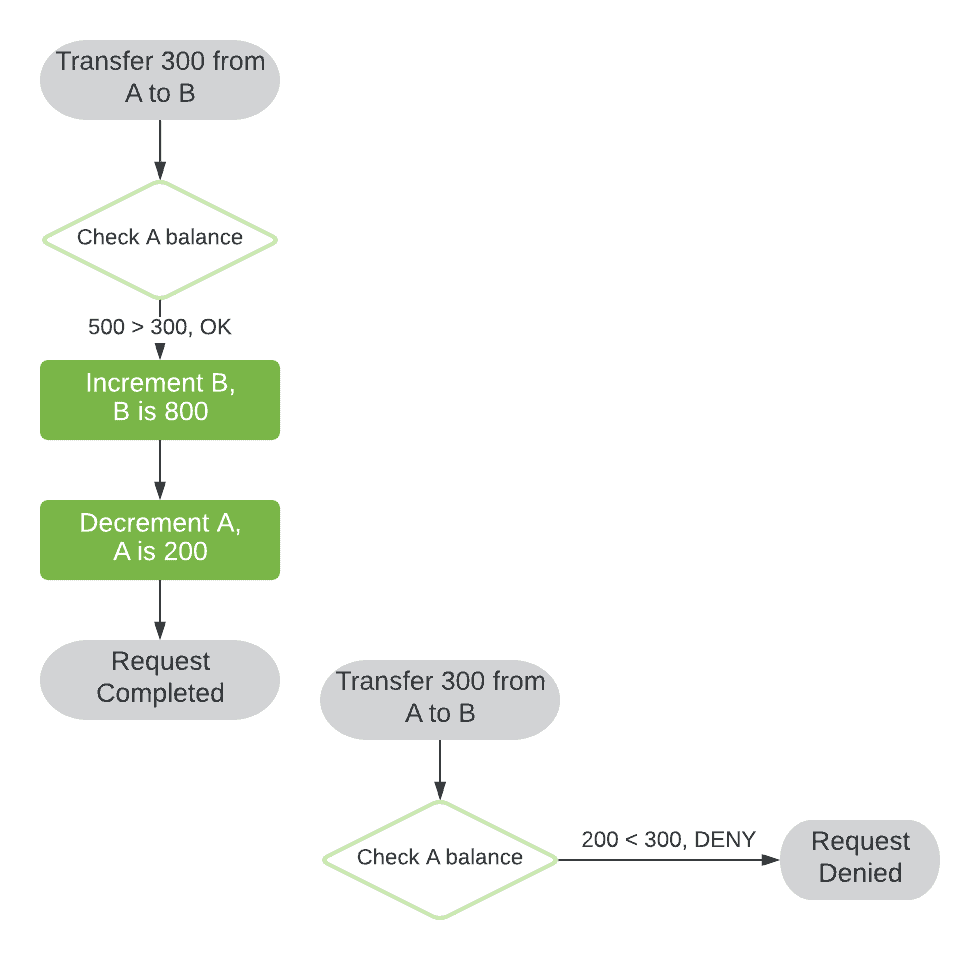
However, if these two attempts are kicked off simultaneously, in different processes or threads, we may observe some undesired behavior:
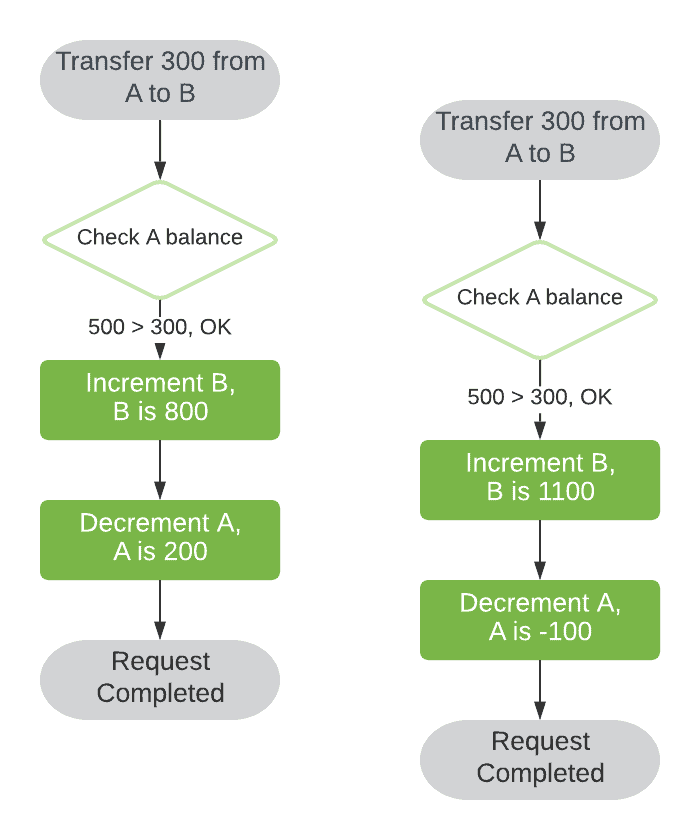
Given unpredictable thread scheduling, the order of specific steps is arbitrary. We’ve encountered a race condition due to the interleaving of our execution flows.
To avoid race conditions, any operation on a shared resource – that is, on a resource that can be shared between threads – must be executed atomically. One way to achieve atomicity is by using critical sections — mutually exclusive parts of the program. Another approach is to use atomic operations to take advantage of the hardware’s ability to ensure indivisibility.
In our bank funds transfer example, we’ve observed the pattern check-then-act.
This is the most common type of race condition. It’s defined by a program flow where a potentially stale observation is used to decide what to do next. We refer to the bugs produced by this condition as Time-of-check to time-of-use or TOCTOU bugs.
TOCTOU races are often found to be the reason for security vulnerabilities on various platforms, specifically around file systems access. Attackers exploit these vulnerabilities to get privilege escalation or to perform a denial-of-service attack.
Lazy initialization is yet another example of a check-then-act pattern.
While the check-then-act type of race condition is indeed the most common type we may encounter in multi-threaded applications, there’s another, easier-to-grasp type.
Consider the following pseudocode, which uses the regular increment operation:
algorithm GenerateId():
// INPUT
// counter = Global counter
// OUTPUT
// Returns a unique identifier incrementing a global counter
return counter++In most languages, the regular increment operator represents three sequential operations — read, modify, and write.
Since we haven’t indicated any atomic guarantee for this execution, if more than one execution is started, we may get the very same operation interleaving we’ve seen before:
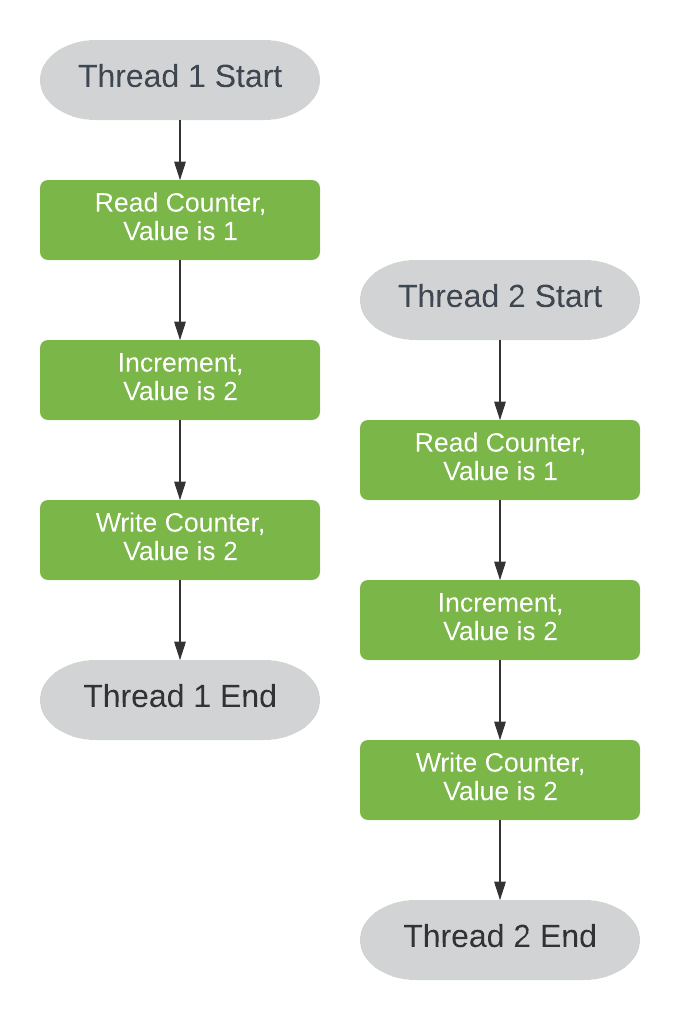
This type of condition is closely related to the data race. We’ll discuss this subtle difference below, but let’s talk about the practical aspects first.
A race condition is usually difficult to reproduce, debug, and eliminate. We describe the bugs introduced by race conditions as heisenbugs.
Since race conditions are tied to application semantics, there’s no general way to detect them. Multi-threaded unit tests with a focus on test result stability will help but are unlikely to provide a 100% guarantee.
Fortunately, there are several techniques to avoid or eliminate race conditions. Knowing these techniques, we may want to ensure their usage in code reviews.
There’re two kinds of approaches to fight race conditions:
As we need a shared state for a race condition to appear, eliminating a shared state is the best way to solve any issues.
Immutable objects, whose state cannot be changed after construction, are inherently thread-safe. Using immutable objects as much as possible is always advisable.
Thread-local variables, localized in such a way that each thread has its private copy, are also thread-safe since they are local to each thread.
For check-then-act race conditions, one general technique is to use exception handling instead of checking. In this approach, the failure of an assumption to hold is detected at use time, raising an exception. As the familiar saying goes, it’s easier to ask for forgiveness than permission.
More radical treatment is using a concurrency model prohibiting shared state altogether, such as actor-based concurrency.
Synchronization primitives, such as critical sections, are used to ensure that a specific part of the program can’t be executed by more than one thread at the same time. A lock is a synchronization mechanism to enforce critical section behavior at the thread level. A mutex is the same abstraction existing across multiple system processes.
While synchronization is the most powerful way to get rid of the race condition, it comes at a price. Locks bring us a performance hit due to their overhead. They also may be tricky to handle. Locks do not compose, meaning it requires extra effort to preserve correctness when combining lock-based modules into a larger lock-based program. Finally, locks may introduce deadlocks.
Atomic operation implies its execution as a single unit of work. Specific guarantee depends on the language in use, but the main idea is that the implementation relies on hardware’s ability to prevent interrupts until the execution is over.
We may use atomic operations to implement higher-level lock-free abstractions. Software Transaction Memory – yet another concurrency model – leverages the concept to enable database-like transactions on the operations in memory.
At the application level, using concurrent data structures and language-provided atomic packages may prove to be instrumental.
While the global counter increment example described above is the classic demonstration for a race condition, it also represents another concept. The race condition in the aforementioned example is caused by accessing – including writing – the same memory location by parallel instructions without any atomicity contract.
We refer to this occurrence as a data race. A data race occurs when two threads access the same variable concurrently, and at least one of the accesses is a write. The data race concept is more specific to memory access in a particular concurrency model and, thus, varies across platforms.
In most cases, a data race creates a race condition exactly like in our counter increment example. Nevertheless, it’s possible to have race conditions without a data race, and, depending on the specific platform definition, it’s possible to have a data race that does not create undesirable outcomes. In general, the data race is not a subset of race conditions.
In our bank funds transfer example, we focused on the check-then-act sequence and didn’t pay attention to balance increment/decrement operations’ atomicity. Indeed, a naive implementation of the bank funds transfer has data races as well.
Those can be resolved by ensuring atomicity on increment/decrement operations (for example, by using locks), same as with the counter increment example. By protecting every operation, we would get rid of the data race, but the race condition would still be present unless we put the entire implementation into a critical section.
Unlike race conditions, a data race on a particular platform has a strict definition that is not dependent on program semantics. This provides the ability to detect data races automatically.
Many tools exist for this purpose, including RV-Predict, ThreadSanitizer, and Intel Inspector.
In this article, we’ve discussed the race condition that appears in multi-threaded applications.
We learned about the check-then-act pattern and data races.
Finally, we considered some methods to avoid and eliminate race conditions to ensure the correctness of our programs.