Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: February 28, 2025

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
We can find AI-related topics in the news almost every week. It’s not only the popularity, but the number of technologies that can be used that’s increasing. Currently, we can choose from a wide range of frameworks, libraries, and platforms for deployment and testing. With all of these options, sometimes choosing the right fit for our needs can be hard.
If we had to hard-code every neural network, its gradient computation, and the structure of each layer, it would be inefficient and time-consuming. Instead of coding mathematical equations and fixing small bugs, we can use well-established tools to ensure our model has higher accuracy, as well as the desired output. In this tutorial, we’ll describe some AI Engines and specify their differences. We’ll also discuss the required level of expertise for each one, so we have the knowledge to select the correct tool for our next project.
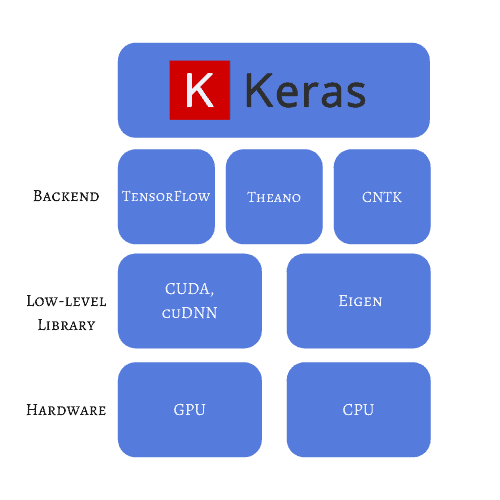
This library presents itself as “designed for human beings, not machines,” and provides a high level of abstraction. It was designed on top of TensorFlow 2. Its main goal is to provide the fastest implementation because it reduces the user’s load, at least in the most common scenarios and cases. It can also be used as a wrapper for other backend frameworks, such as Theano and CNTK.
The flexibility of this library gives it a powerful range of applications in the real world. For example, we can implement a 3D image classification from CT scans with a relatively small code. Big companies, such as Youtube and NASA, use Keras at some point in their workflows given the scalability and efficiency that can be achieved if using low-level operations in GPU or TPU.
Keras also has pre-processing functionalities for images, time-series, and text data. In addition, it has built-in small datasets already vectorized and ready to be used to test simple code examples.
Keras is a good choice for developers with Python experience and little knowledge in the ML field. We’re able to easily see how to structure, train, and refine a neural network architecture with real datasets and real-world problems:
Open Neural Network is an open-source library for machine learning written in C++. We should consider using it when the project we’re working on has a strict high-performance requirement.
We can use this library in several scenarios:
The library presents itself as a software solution for advanced analytics. It has five main classes available for us to build and test our model: data set, neural network, training strategy, model selection, and testing analysis. We can easily find tutorials to get started with each of these classes.
This library is recommended for developers familiar with C++ code and basic knowledge of ML.
Considering that Java is still one of the most used programming languages in the world, it makes sense to have a library written in Java.
Deep Learning for Java is an open-source, distributed deep-learning library for the JVM. Under the hood, computations are performed in C, C++, and Cuda. This, along with the fact that distributed computing frameworks such as Apache Spark and Hadoop can be used, gives us accelerated training both in CPUs and GPUs.
The API gives us the ability to build a deep neural network as flexible as we need. We can use convolutional nets, recurrent nets, and variational autoencoders, among others, to structure each layer. This library also provides us with tools to test and optimize transfer learning, load a previously trained model, freeze some layers, and fine-tune all the parameters in a model.
One of the greatest advantages of DL4J is the visualization UI interface, which we can use with Spark to verify in real-time the progress of training in a web browser.
We’ll find a detailed explanation for each API function, tutorials for beginners, and visualization examples on the documentation page.
Amazon ML claims to be the broadest set of machine learning services. We can use Amazon ML to build, train, and deploy machine learning models. We can also add AI functionalities with absolutely zero theoretical knowledge of how neural networks behave.
Although this tool is not open-source, we do have limited access to its functionalities. It offers a wide range of possibilities, including fraud prevention, business forecasting, and image analysis.
Using a platform with such a high level of abstraction, where we’re not responsible for developing actual code, brings one disadvantage. We need to use an API to use the functionalities, but it’s not possible to define some specific parameters or learning strategies, such as a new machine-learning algorithm or loss function.
If we want to use a drag-and-drop interface with an end-to-end platform, we can use Azure ML. At this point, it’s clear that one of the biggest challenges when building a model is to define which features are relevant, and how the data should be represented.
This platform comes with an automated machine learning strategy in which feature engineering is already implemented together with algorithm selection and hyperparameter tuning. All of these resources, combined with the built-in DevOps, make it possible to have fast prototyping and deployment.
We can also work in a lower level of abstraction, with more flexibility to our projects, by integrating with open-source frameworks such as ONNX, TensorFlow, and Pytorch, as well as using IDE’s Jupyter Notebooks. In addition, we can set our tools in Python or R to work with Azure ML Studio.
Similar to Amazon ML, this service limits the number of resources we can use in its free version.
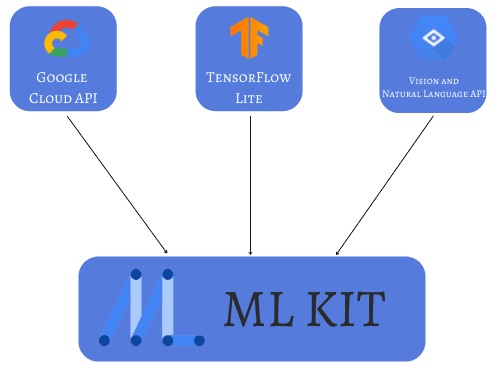
Google developed the ML Kit to provide us with tools to easily integrate neural networks into Android and IOS applications. This kit is like a mobile SDK for developers with different experience levels in Machine Learning. For instance, we can implement a face detection app with just a few lines of code. If we need to, we can also use low-level APIs to customize the neural network’s architecture.
Importantly, if we use cloud-based APIs, we can also use Google Cloud’s powerful and reliable machine learning technology. Furthermore, we can develop offline, on-device apps to work without an internet connection, as the whole software will use the device’s memory and processor.
There are two main APIs. Vision API is for image labeling, text recognition, object detection, and other vision-related applications. Natural Language API is for translation and reply suggestions.
As we would be developing mobile applications, it’s not necessary to be an expert in neural networks, though it is required to have some knowledge in this area.
In this article, we learned that our previous experience and preferred programming language greatly influence our choice of ML technology. This, along with our desired flexibility in the process of developing a model, allows us to choose correctly.
If our background doesn’t include any of the languages mentioned, we can also use high-level tools that can be integrated into our software without dealing with code specificity.
Finally, knowing the basics of Artificial Intelligence will expand our range of frameworks and tools, as we’ll know how to adjust the hyperparameters to obtain faster, but still accurate training.