

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll study the off-by-one error (OBOE). This type of error is very common while iterating over a range of items.
We make this logical error when we either exceed the boundary by one or leave out the element before the boundary.
An off-by-one error is a type of error that is related to the start and end values of a contiguous range of memory.
In a typical scenario, we use a continuous block with  memory units to store elements, each taking one unit. Let’s say we iterate over this block times to read all the elements. But, if we access this block for either
memory units to store elements, each taking one unit. Let’s say we iterate over this block times to read all the elements. But, if we access this block for either  or
or  times, we have OBOE:
times, we have OBOE:
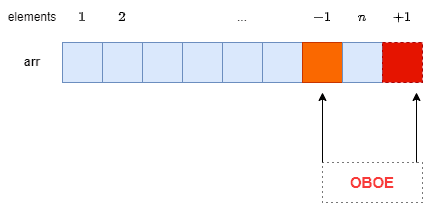
Let’s go through different cases where OBOE can occur.
In this scenario, we make this error when following a different index scheme than the underlying programming environment.
Let’s say the indices in the programming language start from 0. So, for an  -element structure, the last index is
-element structure, the last index is  . However, if we access it with an index ranging from 1 to , we get an OBOE.
. However, if we access it with an index ranging from 1 to , we get an OBOE.
We’ll use an example to clarify. Let’s say we have a 5-element array  . Now, we iterate over it using indices 1 through 5. Here, we will get two errors, one of which is OBOE.
. Now, we iterate over it using indices 1 through 5. Here, we will get two errors, one of which is OBOE.
The first error will be that we will expect ![arr[1]](/wp-content/ql-cache/quicklatex.com-24a5eed41c009964e45895dc93c8264f_l3.svg "Rendered by QuickLaTeX.com") to return 2, whereas we’ll get 4. The same goes for
to return 2, whereas we’ll get 4. The same goes for ![arr[2], arr[3]](/wp-content/ql-cache/quicklatex.com-d2b07f353716572a0c4cbd7150d8e072_l3.svg "Rendered by QuickLaTeX.com") and
and ![arr[4]](/wp-content/ql-cache/quicklatex.com-6900f29b1ff107193bd702125bfcc4fb_l3.svg "Rendered by QuickLaTeX.com") . This is a logical error and is usually hard to catch.
. This is a logical error and is usually hard to catch.
The other error is a run-time OBOE that we get when trying to access the element ![arr[5]](/wp-content/ql-cache/quicklatex.com-0c810e93c46eb6d3848902e25a8ea2e4_l3.svg "Rendered by QuickLaTeX.com") . It’s outside the memory range allocated to
. It’s outside the memory range allocated to  , and hence the operating system will raise a memory error.
, and hence the operating system will raise a memory error.
We can easily debug it by printing the current index in each iteration of the loop together with the upper and lower bounds of our memory structure. That way, we can check these two values to see which one is causing OBOE.
This is very common when we don’t set the loop condition(s) properly.
Let’s say we have an array and want to access ![arr[m], arr[m+1],\ldots, arr[m+n]](/wp-content/ql-cache/quicklatex.com-1bc31321af3f6188f45e079f244cd7b1_l3.svg "Rendered by QuickLaTeX.com") . Further, the programming environment uses
. Further, the programming environment uses  -based indexation. We’ll get an OBOE if we use
-based indexation. We’ll get an OBOE if we use  as the last index to check:
as the last index to check:
algorithm retrieveArrayElementsOBOE(arr, N, m, n):
// INPUT
// arr = an array of numbers
// m = start index
// n = the number of elements to process
// OUTPUT
// Processes elements from index m to m + n - 1 in arr
tmp <- 0 // set tmp to 0
index <- 0 // set index to 0
for index <- m to m + n:
// access each element
tmp <- arr[index]
// Use tmp for further processing
Instead, we should use  :
:
algorithm retrieveArrayElementsWithoutOBOE(arr, N, m, n):
// INPUT
// arr = an array of numbers
// m = start index
// n = the number of elements to process
// OUTPUT
// Processes elements from index m to m + n in arr
tmp <- 0 // set tmp to 0
index <- 0 // set index to 0
for index <- m to m + n + 1:
// access each element
tmp <- arr[index]
// Use tmp for further processing
That way, we don’t miss the last element of the sub-array, ![arr[m+n]](/wp-content/ql-cache/quicklatex.com-b74cd12e042f4b7450b472c35b7f003d_l3.svg "Rendered by QuickLaTeX.com") .
.
OBOE has huge security implications when it overruns the memory range in our programs.
Let’s assume we allocate a block of bytes on the heap. Then, we store a structure  in it. Now, we try to update by setting it to another structure
in it. Now, we try to update by setting it to another structure  of size
of size  bytes. Here, we’ll corrupt a byte of the structure next to provided that the programming language compiler (interpreter) doesn’t catch this error. In most cases, we’ll get a memory segmentation fault when this memory happens to belong to some other process.
bytes. Here, we’ll corrupt a byte of the structure next to provided that the programming language compiler (interpreter) doesn’t catch this error. In most cases, we’ll get a memory segmentation fault when this memory happens to belong to some other process.
Furthermore, on systems with little-endian architectures, this can overwrite the least significant byte of a memory structure. With this done, a hacker can place the starting address of a trojan or virus at this location. As a result, they can corrupt our system.
We can solve this problem by calculating the size of the new structure before the update operation. If the size of is the same as that of , then only we update . Otherwise, we raise a size mismatch exception.
We can solve the off-by-one error in three ways.
The first is to dry-run every suspicious loop on paper before executing the code on a computer. That way, we can avoid any misjudgment about the index ranges.
The second way is to always specify the range of any contiguous structure as a half-open interval. For example, to select all the elements of an array, we use the range  . It tells us to include but not . Adopting a convention and sticking to it will greatly reduce the chance of getting an OBOE.
. It tells us to include but not . Adopting a convention and sticking to it will greatly reduce the chance of getting an OBOE.
The third way is to include all boundary cases in our unit test cases. This way, we can check the code for all ranges. A unit test is an automated test script that we use to ensure that a stand-alone section of our code (we call it a unit) behaves as per its design and specification.
In this article, we explained the concept of the off-by-one error. It’s a logical error we make when we process one element more or less than we intended to.
This error is hard to catch. Thus, we need to be careful when specifying looping conditions.