

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
Networked communications are complex, and keeping the quality of connections is challenging for network operators and administrators. To do that, network operators execute several monitoring processes to analyze the results and find the proper actions to improve the network. In this context, several metrics are measured, such as throughput, packet loss, jitter, and round trip time.
In this tutorial, we’ll particularly study the Round Trip Time (RTT). Initially, we’ll have a brief review on what is propagation time. Thus, we’ll in-depth understand the concept of round trip time, understanding how it works, and which events can typically vary its value. So, we’ll check some strategies to reduce the RTT. Finally, we’ll understand the similarities and differences between RTT and ping results.
2. Propagation Time
One of the most relevant components of RTT is propagation time. In networking, propagation time means the total length of time that a signal takes to be sent from the source to the destination. We can also call the propagation time of one-way delay or latency.
A characteristic of propagation time is that there is no guarantee different sending processes of the same packet from the same source to the same destination present the same propagation time.
The following figure depicts the central notion of propagation time:
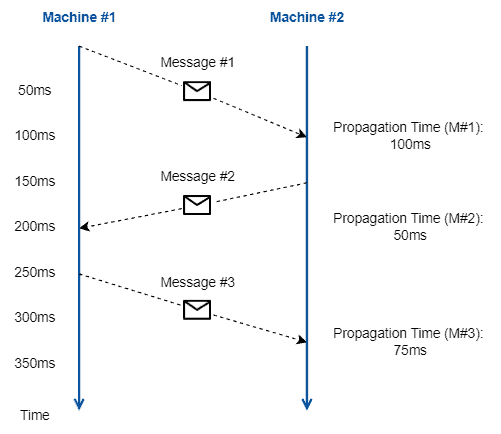
It is relevant to highlight the propagation time from the first machine to the second machine and the propagation time from the second machine to the first one, which can differ.
3. Round Trip Time
The RTT is the time between sending a message from a source to a destination (start) and receiving the acknowledgment from the destination at the source point (end). We can also see RTT referred to as Round Trip Delay (RTD).
Sometimes, the acknowledgment is sent from the destination to the source almost immediately after the latter receives a message. Thus, the processing time at the destination point is negligible. In this way, the RTT consists of the propagation time from the source to the destination ($PT_m$) plus the propagation time from the destination to the source ($PT_a$).
A common misconception is assuming that the RTT is two times the propagation time from a source to a destination. However, the response message (acknowledgment) can have a different propagation time to arrive at the source point. It may occur due to a bottleneck in the network or different routes taken, for example.
Finally, another relevant characteristic of RTT is measuring it in the highest network layer possible. Thus, if we use protocols such as HTTPS, we may have some extra time to decrypt the message before sending the acknowledgment message. This additional time composes the RTT.
The following figure illustrates the measured times composing the RTT:
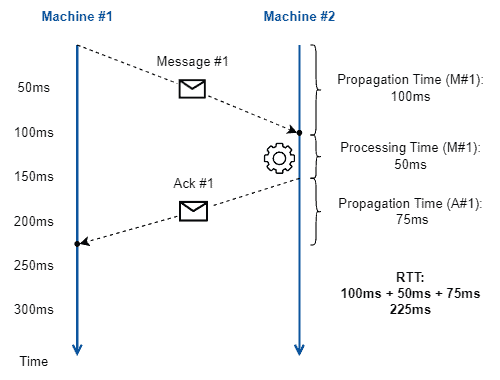
It is important to note that we measure RTT from the perspective of the message source (sender). Thus, RTT is pretty useful for getting some insights about, for example, the quality of service and experience of users of network-provided applications.
3.1. Managing the Round Trip Time
Several factors vary the RTT taking into account a particular source. Among the most prominent of them, we can cite the following ones:
- Existence of Network Bottlenecks: an overloaded network increases the RTT since it may incur some extra queueing, processing, and transmission times for packets being processed and forwarded by network functions
- Physical Distance Between Source and Destination: large physical distances between a source and destination result, at least, in more cables (or other transmission mediums) on which a message goes thorough. But it can also result in more hops and extra network function processing
- Transmission Technologies Employed: data transmission over optical fiber has different characteristics than doing that through copper cables, which, in turn, differs from a wireless medium. The transmission technology employed may directly impact the RTT
Some techniques can reduce the RTT when requesting and retrieving a network-provided resource. Let’s see some of them:
- Track the connections: constantly monitoring the RTT of connections is essential to understand how to improve it. According to the obtained results, we can optimize the networking routes and simplify the exchanged data and the operations done in the system
- Refactor the system: reducing the number of unique hostnames may save time with DNS operations; moreover, keeping the system updated and free from broken lists or pages helps to not waste time
- Bring resources near users: providing resources through CDN is a great option to reduce the propagation delay and, consequently, the RTT; for web pages, enabling browser caching can also be efficient for that
Minimizing the global RTT of a system is a difficult task. Different users have different experiences in retrieving data or executing operations due to their geographical positions and the conditions of the networking routes employed. So, system administrators should make it the most efficient possible in opening connections and responding to requests and, if possible, make resources available near end-user-dense regions.
4. RTT vs. Ping
Ping stands for Packet Internet-Network Groper and is a simple network software tool. This tool employs the Internet Control Message Protocol (ICMP), sending echo requests from a source point and waiting for echo replies from the destination system.
In this way, Ping can check the destination system reachability, provide packet loss statistics, report some errors, and calculate the minimum, average, and maximum RTT.
So, the question is: can we use ping to calculate RTT for any system?
The answer to the previous question is no. As previously stated, ping works with ICMP (which is a network layer protocol). But, RTT always is measured in the highest layer that a system operates on. So, we can not use ping to precisely measure the RTT of an HTTPS system, for example.
However, although not a synonym in every scenario, ping provides a pretty good estimation of RTT and can be generically used to measure it when high precision on the results is not a strict requirement.
5. Conclusion
In this article, we explored the Round Trip Time. First, we reviewed the concept of propagation time, which is crucial to understand RTT. Thus, we specifically investigated RTT by presenting its fundamentals, the most common factors that impact its value, and techniques to reduce the average RTT for accessing particular network-provided resources and systems. Finally, we show the similarities and differences between ping-based time measurements and RTT.
We can conclude that RTT is a pretty relevant metric for network monitoring. RTT provides valuable insights into the quality of service and experience, thus working as a significant piece of information for improving network-provided resources and systems.