

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll discuss how to merge two sorted arrays into a single sorted array and focus on the theoretical idea and provide the solutions in pseudocode form, rather than focusing on a specific programming language.
First, we’ll define the problem and provide an example that explains the meaning of merging two sorted arrays.
Second, we’ll discuss two approaches to solving the problem.
Finally, we’ll compare the provided approaches and discuss the case in which both of them have the same complexity.
The problem gives us two arrays,  of size
of size  , and
, and  of size
of size  . Both arrays are sorted in the increasing order of their values.
. Both arrays are sorted in the increasing order of their values.
In other words:
![\[\boldsymbol{A[i] \leq A[i + 1] ; i \in [0, n - 2]}\]](/wp-content/ql-cache/quicklatex.com-e1d85b0eaf7a6e2132a723283c7e3519_l3.svg "Rendered by QuickLaTeX.com")
![\[\boldsymbol{B[j] \leq B[j + 1] ; j \in [0, m - 2]}\]](/wp-content/ql-cache/quicklatex.com-54686261b5fccb9dc622162beb057fc8_l3.svg "Rendered by QuickLaTeX.com")
After that, the problem asks us to calculate the resulting array  of size
of size  that contains all the elements from
that contains all the elements from  and
and  . Note that, the resulting array
. Note that, the resulting array  must be sorted as well. In other words:
must be sorted as well. In other words:
![\[\boldsymbol{R[id] \leq R[id + 1] ; id \in [0, n + m - 2]}\]](/wp-content/ql-cache/quicklatex.com-2c2f450344d44a5f1df5a46f47765541_l3.svg "Rendered by QuickLaTeX.com")
To understand the idea in a better way, let’s take the following example:
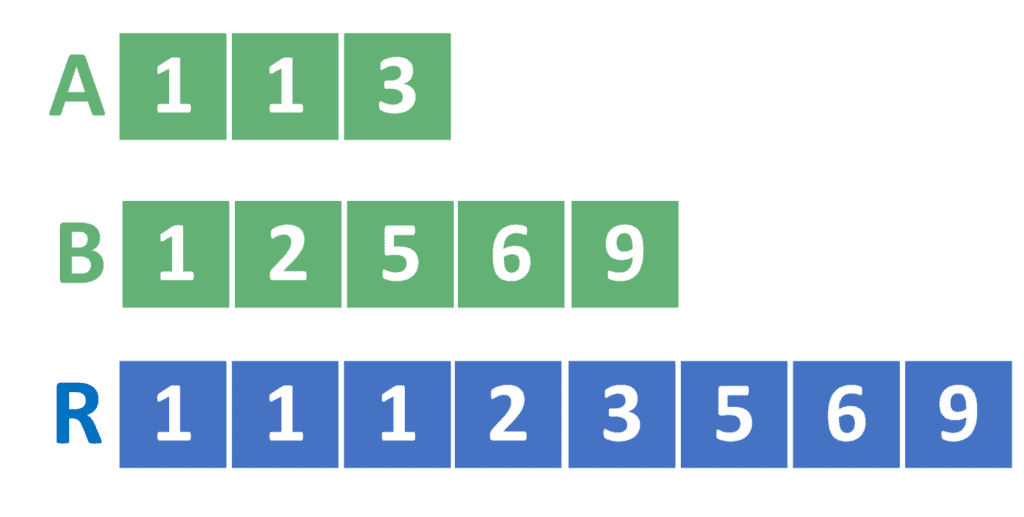
From the example, we can see that the array has  elements, while the array has
elements, while the array has  elements. Therefore, the resulting array has
elements. Therefore, the resulting array has  elements.
elements.
Also, the resulting array contains all the elements from and . For example, the array contains the value  twice. On the other hand, contains the value once. Hence, the array contains the value three times.
twice. On the other hand, contains the value once. Hence, the array contains the value three times.
Also, the resulting array contains all the elements sorted in the ascending order, similarly to the arrays and .
Now that we reached a good understanding of the problem, let’s dive into the solutions.
Let’s discuss the naive approach firstly. After that, we can see how to improve it.
In the naive approach, we simply add all the elements from arrays and to . Then, we sort before returning it.
Take a look at its implementation:
algorithm naiveMerge(A, B):
// INPUT
// A = The first array
// B = The second array
// n = the size of A
// m = the size of B
// OUTPUT
// Returns the merged array of A and B
R <- empty array of size n + m
id <- 0
for i <- 0 to n - 1:
R[id] <- A[i]
id <- id + 1
for j <- 0 to m - 1:
R[id] <- B[j]
id <- id + 1
sort(R)
return RIn the beginning, we’ll declare the resulting array of size  . This array will hold the resulting answer to the problem. Also, we’ll initialize
. This array will hold the resulting answer to the problem. Also, we’ll initialize  with zero that will point to the index on which to add the next element inside .
with zero that will point to the index on which to add the next element inside .
After that, we iterate over all the values inside and add them to the resulting array . Also, we perform the same operation for all the values inside .
Finally, we sort the array and return it as the resulting answer.
The complexity of the naive approach is  , where is the number of elements inside the first array and is the number of elements inside the second one.
, where is the number of elements inside the first array and is the number of elements inside the second one.
The reason for the complexity is that we can perform the sorting operation in  .
.
Let’s improve the naive approach.
Suppose we want to find out the first element that should be added to the resulting array . It must be the smallest element inside and .
However, since both arrays and are sorted, then the smallest element of each of them is at the beginning. Therefore, we’ll add this value to .
Now, let’s imagine that we removed this smallest value from its array, and think about the problem again. We’ll need to find the new smallest element and add it to as well.
As a result, we can find a general approach to solve this problem. We start by defining two pointers  and
and  . Initially, will point to the first element in , and will point to the first element in . In each step, we’ll add the smallest value to and move the corresponding pointer one step forward.
. Initially, will point to the first element in , and will point to the first element in . In each step, we’ll add the smallest value to and move the corresponding pointer one step forward.
Note that, since we always add the smallest value to , the resulting array will be sorted in the end.
Since the idea is clear now, we can jump to the implementation of this approach.
Take a look at the implementation of the two-pointers approach:
algorithm twoPointersMerge(A, B):
// INPUT
// A = The first array
// B = The second array
// n = the size of A
// m = the size of B
// OUTPUT
// Returns the merged array of A and B
i <- 0
j <- 0
R <- empty array of size n + m
for id <- 0 to n + m - 1:
if j >= m:
R[id] <- A[i]
i <- i + 1
else if i >= n:
R[id] <- B[j]
j <- j + 1
else if A[i] <= B[j]:
R[id] <- A[i]
i <- i + 1
else:
R[id] <- B[j]
j <- j + 1
return RFirst of all, we’ll initialize two variables and with zero. These variables will serve as the needed two pointers. Therefore, will point to the current index inside , and will point to the current index inside .
Also, we’ll declare the array that will hold the resulting answer. Note that the array must be of size  .
.
Next, we’ll iterate over all the indexes inside the resulting array . For each index, we’ll store the minimum value among ![A[i]](/wp-content/ql-cache/quicklatex.com-42484bff0529bb02d3d57d306e1b611b_l3.svg "Rendered by QuickLaTeX.com") and
and ![B[j]](/wp-content/ql-cache/quicklatex.com-69dc117c3f8d86b2a58de95f872e1522_l3.svg "Rendered by QuickLaTeX.com") and move the corresponding pointer.
and move the corresponding pointer.
Nevertheless, we mustn’t forget about the case when either or reaches the end of their arrays. In this case, we must store the value from the other array and move its pointer.
Finally, we return the resulting array .
The complexity of the two-pointers approach is  , where is the number of elements inside the first array and is the number of elements inside the second one.
, where is the number of elements inside the first array and is the number of elements inside the second one.
In the general case, the two-pointers approach has the lowest time complexity. However, there’s one case where the naive approach can be implemented with a complexity equal to the one of the two-pointers approach.
If all the elements inside and are relatively small, then we can sort the resulting array using the counting sort technique. In this case, the counting sort has a complexity of  , where is the number of elements inside the array, and
, where is the number of elements inside the array, and  is the maximum number inside it.
is the maximum number inside it.
Therefore, the complexity of the naive approach becomes  , where is the number of elements inside the first array, is the number of elements inside the second array, and is the maximum value inside both arrays.
, where is the number of elements inside the first array, is the number of elements inside the second array, and is the maximum value inside both arrays.
As a result, if  , then the complexity of the naive approach becomes
, then the complexity of the naive approach becomes  .
.
Note that this complexity is similar to the complexity of the two-pointers approach. We can’t obtain a better complexity because the resulting array has a size of . Hence, in the best case, we still need to iterate over its elements and fill them one by one without performing any more operations.
In this tutorial, we discussed the problem of merging two sorted arrays into a resulting sorted array.
In the beginning, we discussed the problem with an example.
After that, we provided two approaches to solve the problem. The first approach was the naive one, while the second one was the two-pointers approach.
Finally, we presented a comparison between both approaches and provided the case in which both the naive and the two-pointers approaches reach the same complexity.