

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll discuss finding the maximum square size filled with ones in a matrix that contains only zeros and ones.
Firstly, we’ll define the problem. Then we’ll give an example to explain it.
After that, we’ll present four different approaches to solving this problem.
We’re given a binary matrix  of size
of size  (containing
(containing  rows and
rows and  columns). Each cell of the matrix has a value equal to either zero or one. We’re asked to find the maximum side length of a sub-matrix that’s full of ones.
columns). Each cell of the matrix has a value equal to either zero or one. We’re asked to find the maximum side length of a sub-matrix that’s full of ones.
Let’s take a look at the following example for a better understanding:
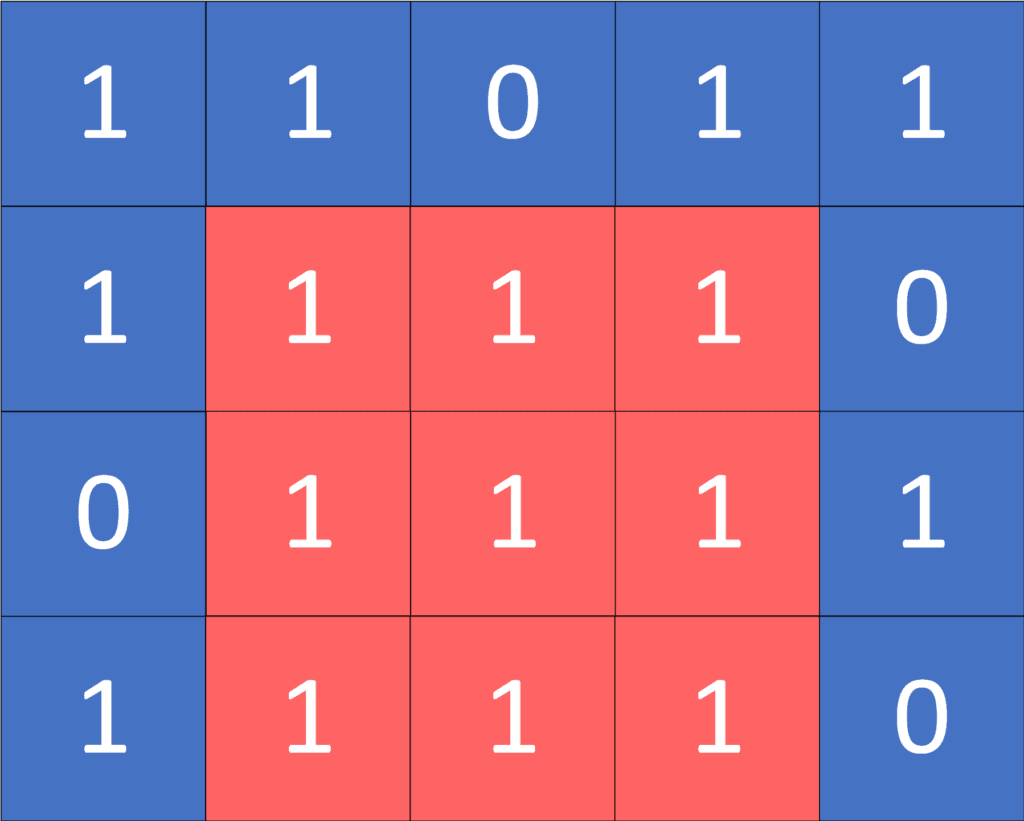
we’ll represent the sub-matrix as two tuples  and
and  , which represent the position of the top-left corner and the bottom-right corner respectively.
, which represent the position of the top-left corner and the bottom-right corner respectively.
As we can see, the sub-matrix  and
and  is the biggest square sub-matrix which is full of ones. It has a size equal to
is the biggest square sub-matrix which is full of ones. It has a size equal to  , so the answer for the given example is
, so the answer for the given example is  , which represents the length of the square’s side.
, which represents the length of the square’s side.
The idea in this approach is to loop over all the cells of the given matrix. For each cell, we fix it as the top-left corner and check every possible square length.
For each length, we get the bottom-right corner by adding the  to the coordinates of the top-left corner
to the coordinates of the top-left corner  , which represents the current fixed cell. To check whether the current square is full of ones, we’ll iterate over all the cells of this sub-matrix and check if they’re equal to one.
, which represents the current fixed cell. To check whether the current square is full of ones, we’ll iterate over all the cells of this sub-matrix and check if they’re equal to one.
In the end, if the current square is valid, we’ll maximize our answer with the current length to get the length of the maximum square full of ones.
First, let’s implement the function that will check whether a given square matrix is filled with ones:
algorithm CheckIfSquareIsFullOfOnes(TL, BR):
// INPUT
// TL = the top-left corner of the square (TL.x, TL.y)
// BR = the bottom-right corner of the square (BR.x, BR.y)
// OUTPUT
// true if the square is full of ones, false otherwise
for i <- TL.x to BR.x:
for j <- TL.y to BR.y:
if G[i, j] = 0:
return false
return trueWe iterate over each cell in the sub-matrix. If the value of the current cell is equal to zero, then we return  .
.
Otherwise, if we reach the end and don’t find any zeros, that means the sub-matrix is full of ones. As a result, we return  .
.
Let’s take a look at the implementation of the algorithm:
algorithm BruteForceApproach(N, M):
// INPUT
// N = the number of rows in the matrix
// M = the number of columns in the matrix
// OUTPUT
// The length of the maximum square sub-matrix that is full of ones
answer <- 0
for i <- 1 to N:
for j <- 1 to M:
for len <- 1 to Min(N, M):
if i + len > N or j + len > M:
break
if isFull((i, j), (i + len - 1, j + len - 1)):
answer <- Max(answer, len)
return answerInitially, we declare  , which will store the answer for our problem. Then, we iterate over each cell of the given matrix and fix it as the top-left corner of the square sub-matrix.
, which will store the answer for our problem. Then, we iterate over each cell of the given matrix and fix it as the top-left corner of the square sub-matrix.
Next, we try to check every possible length. If the current length generates a square that doesn’t fit in the matrix, we break out of the loop.
Otherwise, we check if the square sub-matrix that has top-left corner and bottom-right corner  is full of ones. If so, that means there’s a square with a side length equal to
is full of ones. If so, that means there’s a square with a side length equal to  . So, we maximize the answer to equal the maximum value between the previous answer and the current length.
. So, we maximize the answer to equal the maximum value between the previous answer and the current length.
Finally, the will have the length of the maximum square that’s full of ones.
The complexity of this algorithm is  , where is the number of rows, is the number of columns, and
, where is the number of rows, is the number of columns, and  is the maximum possible length of a square side which is in the worst-case equal to
is the maximum possible length of a square side which is in the worst-case equal to  .
.
The reason behind this complexity is that we’ll iterate over each cell once with complexity equal to  . On the other hand, for each cell, we try every possible length with complexity that is equal to
. On the other hand, for each cell, we try every possible length with complexity that is equal to .
.
In addition, for every length, we check if the square is full of ones or not, which has a complexity equal to .
That leaves us with total complexity equal to  .
.
In this approach, we’ll use the same idea as the previous approach. However, we’ll optimize the  function and make it run in
function and make it run in  complexity instead of
complexity instead of  .
.
We’ll use the 2D prefix sum technique, a dynamic programming optimization, to get the sum of sub-matrix in constant time complexity. The main idea in this technique is to create a  matrix which, inside
matrix which, inside ![\boldsymbol{prefix[i][j]}](/wp-content/ql-cache/quicklatex.com-c9dee7ca1d7b704229ef409bf3a91c9d_l3.svg "Rendered by QuickLaTeX.com") , stores the sum of all the elements in the sub-matrix (1, 1), (i, j).
, stores the sum of all the elements in the sub-matrix (1, 1), (i, j).
The formula to build this matrix is:
![\[\boldsymbol{Prefix[i][j] = Matrix[i][j] + Prefix[i][j - 1] + Prefix[i - 1][j] - Prefix[i - 1][j - 1]}\]](/wp-content/ql-cache/quicklatex.com-df84849dfd2b855ffa3486ddeff4ab0d_l3.svg "Rendered by QuickLaTeX.com")
The sum of the sub-matrix (1, 1), (i, j) can be obtained by taking the sum of sub-matrices (1, 1), (i, j – 1) and (1, 1), (i – 1, j). However, in this case, we have added the sum of (1, 1), (i – 1, j – 1) twice. Thus, we delete it from the answer. Also, we didn’t include the current cell (i, j), so we add it to the prefix value.
If we want to get the sum of a specific sub-matrix , , we’ll get the sum at the bottom-right corner ![prefix[x_2][y_2]](/wp-content/ql-cache/quicklatex.com-68243ea6ccdd8098d7c70dcab3943070_l3.svg "Rendered by QuickLaTeX.com") .
.
Then, we’ll subtract ![prefix[x_2][y_1 - 1]](/wp-content/ql-cache/quicklatex.com-7c6064dc428725714cde331c55e0f688_l3.svg "Rendered by QuickLaTeX.com") which corresponds to the sum of the sub-matrix
which corresponds to the sum of the sub-matrix  ,
,  . Also, we’ll subtract
. Also, we’ll subtract ![prefix[x_1 - 1][y_2]](/wp-content/ql-cache/quicklatex.com-ccfff183be86ec82dddc48f88f962825_l3.svg "Rendered by QuickLaTeX.com") which represents the sum of the sub-matrix ,
which represents the sum of the sub-matrix ,  .
.
Finally, we add ![prefix[x_1 - 1][y_1 - 1]](/wp-content/ql-cache/quicklatex.com-7a62a5f1ab316a29714c35eacfe7e391_l3.svg "Rendered by QuickLaTeX.com") which is the sum of the sub-matrix ,
which is the sum of the sub-matrix ,  because we deleted this sub-matrix twice when we removed the previous two sub-matrices.
because we deleted this sub-matrix twice when we removed the previous two sub-matrices.
Let’s take the following example:
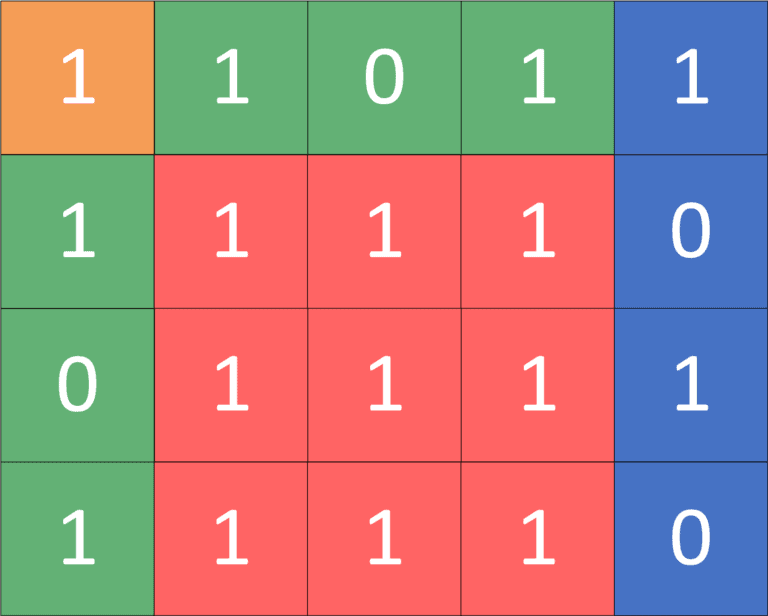
The sum of the sub-matrix (2, 2), (4, 4) can be calculated by taking the following 2D prefix values:
![\[sum = prefix[4][4] - prefix[4][1] - prefix[1][4] + prefix[1][1]\]](/wp-content/ql-cache/quicklatex.com-891e0b4f44c98a68fe962f9aefd1717f_l3.svg "Rendered by QuickLaTeX.com")
Let’s take a look at the enhanced implementation of the function:
algorithm CheckIfSquareIsFullOfOnes(TL, BR):
// INPUT
// TL = the top-left corner of the square (TL.x, TL.y)
// BR = the bottom-right corner of the square (BR.x, BR.y)
// OUTPUT
// true if the square is full of ones, false otherwise
area <- (BR.x - TL.x + 1) * (BR.y - TL.y + 1)
sum <- prefix[BR.x, BR.y]
sum <- sum - prefix[BR.x, TL.y - 1]
sum <- sum - prefix[TL.x - 1, BR.y]
sum <- sum + prefix[TL.x - 1, TL.y - 1]
if sum = area:
return true
else:
return falseThe function will take the top-left and the bottom-right corners as parameters. Next, we’ll calculate the area of the sub-matrix, which represents the number of cells in the sub-matrix.
After that, we’ll use the 2D prefix sum technique to get the sum of the elements in the sub-matrix, which represents the number of ones in the sub-matrix.
Finally, if the value of  is equal to the value of
is equal to the value of  (number of ones equal to the number of cells), that means the given sub-matrix is full of ones. Otherwise, it’s not.
(number of ones equal to the number of cells), that means the given sub-matrix is full of ones. Otherwise, it’s not.
The complexity of this algorithm is  , where is the number of rows, is the number of columns, and is the maximum possible length of a square side which is in the worst-case equal to .
, where is the number of rows, is the number of columns, and is the maximum possible length of a square side which is in the worst-case equal to .
The reason behind this complexity is the same as the previous approach, but instead of checking if a sub-matrix is full of one in complexity, we did it in constant time .
In addition, before starting our algorithm, we’ll calculate the values of  array, but this will have a complexity equal to
array, but this will have a complexity equal to  , which is less than the complexity of the algorithm itself.
, which is less than the complexity of the algorithm itself.
In this approach, we’ll use the binary search algorithm to find the maximum valid length in  .
.
The reason why binary search works here is that, while we iterate over the top-left corner, if there’s a square full of ones of size , that means all the squares of sizes ![[1, 2, 3, ..., L]](/wp-content/ql-cache/quicklatex.com-542faa8bd15073d123483d4dc31a0cfa_l3.svg "Rendered by QuickLaTeX.com") are also filled with ones. The reason is that the square of size is a sub-matrix of the square of size
are also filled with ones. The reason is that the square of size is a sub-matrix of the square of size  .
.
On the other hand, if there’s a square that isn’t filled with ones of size , that means all the squares of size ![[L, L + 1, ....]](/wp-content/ql-cache/quicklatex.com-8d52b683a19043a9ea5d1bdb30a965c8_l3.svg "Rendered by QuickLaTeX.com") are also not filled with ones.
are also not filled with ones.
Let’s take a look at the implementation:
algorithm BinarySearchApproach(N, M):
// INPUT
// N = the number of rows in the matrix
// M = the number of columns in the matrix
// OUTPUT
// The length of the maximum square that is full of ones
answer <- 0
for i <- 1 to N:
for j <- 1 to M:
low <- 1
high <- Min(N - i, M - j)
while low <= high:
len <- (low + high) / 2
if isFull((i, j), (i + len - 1, j + len - 1)):
answer <- Max(answer, len)
low <- len + 1
else:
high <- len - 1
return answerInitially, we declare , which will store the answer for our problem. Then, we iterate over each cell of the given matrix and fix it as the top-left corner of the square sub-matrix.
Next, we’ll find the maximum valid length using binary search. During the binary search algorithm, if the current length is valid (gives us a square full of ones), then we’ll try to maximize the and look for a bigger length. Otherwise, the current length is not valid, and we’ll try to find a smaller length that gives us a square full of ones.
Finally, the will have the length of the maximum square that’s full of ones.
The complexity of this algorithm is  , where is the number of rows, is the number of columns, and is the maximum possible length of a square side which is in the worst-case equal to .
, where is the number of rows, is the number of columns, and is the maximum possible length of a square side which is in the worst-case equal to .
The reason behind this complexity is the same as the previous approach, where we enhanced the function. Still, instead of looping over all the possible lengths, we found the perfect length using binary search technique in complexity  , instead of .
, instead of .
The main idea here is that there’s no need to repeat the search for a perfect length over and over again for each cell.
Instead, when we find a valid length  , we don’t have to check lengths
, we don’t have to check lengths ![\boldsymbol{[1, 2, 3, .., L]}](/wp-content/ql-cache/quicklatex.com-d995e0e9b4dd8f347c4fa9106038bfda_l3.svg "Rendered by QuickLaTeX.com") again since we already have a square full of ones of length . Now, we’ll just be looking for a bigger square full of ones.
again since we already have a square full of ones of length . Now, we’ll just be looking for a bigger square full of ones.
Let’s take a look at the implementation:
algorithm BinarySearchApproach(N, M):
// INPUT
// N = the number of rows in the matrix
// M = the number of columns in the matrix
// OUTPUT
// len = the maximum side length of a sub-matrix full of ones
len <- 0
for i <- 1 to N:
for j <- 1 to M:
while (i + len <= N) and (j + len <= M)
and isFull((i, j), (i + len, j + len)):
len <- len + 1
return lenInitially, we declare , which will represent the maximum length we have at this moment. Also, it’ll be the answer to our problem.
Then, we iterate over each cell of the given matrix and fix it as the top-left corner of the square sub-matrix. Next, as long as we have a square full of ones of the current length, and we didn’t exceed the boundaries of the matrix, we increase the to find a bigger square.
Finally, the value will have the length of the maximum square that’s full of ones.
The complexity of this algorithm is  , where is the number of rows, is the number of columns, and is the maximum possible length of a square side which is in the worst-case equal to .
, where is the number of rows, is the number of columns, and is the maximum possible length of a square side which is in the worst-case equal to .
The reason behind this complexity is that we iterate over each cell once in the complexity of .
In addition, we don’t reduce the value of . Instead, to find the perfect length, we iterate over each length at most once since when we find a valid length , we don’t recheck all the previous lengths.
In this article, we presented the problem of finding the maximum square that’s full of ones.
First, we provided an example to explain the problem. Then, we gave four different approaches to solving it.
Finally, we walked through their implementations, with each approach having a better time complexity than the previous one.