

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
The Log-Structured File System (LFS) was developed to deal with some limitations in traditional file systems. In LFS, data is organized in a similar structure to a log. In short, each operation on a file results in a new record attached to the end of the log.
As a file system that works on specific issues, its practical implementation is more common in contexts such as distributed storage systems or some implementations of research file systems.
In this tutorial, we’ll study the Log-Structured File System proposed by Rosenblum and Ousterhout. First, let’s explore how the system organizes the data on the disk. Next, let’s comprehend the mechanisms employed to optimize the use of disk space. Finally, learn how the system recovers from failures.
The main idea behind LFS is to improve disc writing performance. To do this, it uses the write buffer technique. It keeps track of file updates in memory. When the buffer is sufficient, all changes are sequentially written to the disc in a free space. This way, the system performs only one write operation.
As with Unix FFS, each file has an inode data structure. Each inode contains the metadata of the reference file, such as type, owner, and so on, as well as the address of the file on the disc.
In addition, each inode has a unique identifier number. The inode map references this exclusive number to locate the associated metadata.
Because LFS writes sequentially, it keeps the inodes together with their data blocks (or segments). In other words, the system writes them sequentially to the disc along with the file data:
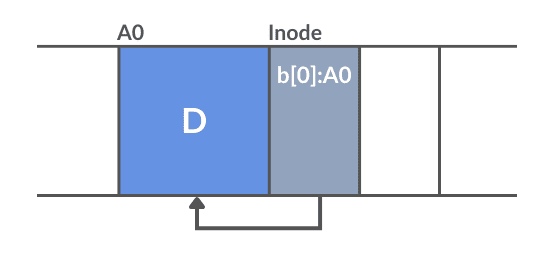
The image above displays the inode and data block after writing to the disk. Note that the data blocks are larger than the inodes. By default, each block is 4KB, while an inode is approximately 128 bytes.
As the inodes are dispersed throughout the disc, a strategy for locating them is needed. To achieve this, we utilize the inode map. This map stores each inode’s current location, making the reading process easier. The system updates the inode map each time it writes an inode to the disc with its new location information.
A buffer in memory stores the active parts of the inode map. The other parts are divided into blocks and stored on the disc, together with where new information is being recorded.
So that the map’s location doesn’t affect performance, there’s a fixed location on the disk where the search for a file begins, called the checkpoint region. This is the location where the system stores pointers to the most recently recorded segments. These pointers allow quick access without going through the entire log, and it’s always kept in the same position on the disk.
As this checkpoint is stored on the disk, the system automatically refreshes it regularly, with a default update frequency of every 30 seconds.
An extremely important part of the LFS is the segments. These are units for reading, writing, and maintaining data.
The system divides each segment into blocks of a fixed size. In short, when the file system needs to write new data, it appends it to the end of the log in a new segment. The system writes the segment sequentially to disk upon reaching the buffer size limit.
Let’s look at a simple example of how LFS stores information. In the figure below, we have two small sets of updates. In practice, however, these sets are larger:
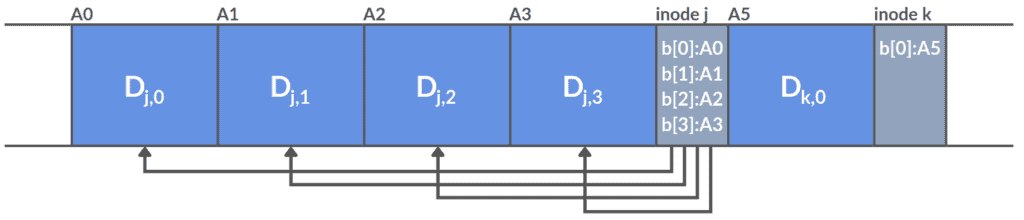
The LFS writes four blocks to the  file in the first update. The second update adds one block to the
file in the first update. The second update adds one block to the  file. The LFS then puts these seven updates into a small segment and then sends the entire segment to disk simultaneously.
file. The LFS then puts these seven updates into a small segment and then sends the entire segment to disk simultaneously.
The default segment size in LFS optimizes the efficient use of disk bandwidth, regardless of the order in which operations access it. In addition, this approach ensures that the time required to transfer a read or write of a complete segment is greater than the cost of a search to the beginning of the segment.
This choice is crucial for reducing the dispersed movement of the read/write head on the disk. Since access to complete segments enables sequential reads, significantly optimizing system performance.
As LFS performs sequential writes, these spaces on the disk must be available for the write operations to occur. In addition, LFS doesn’t recycle file positions on the disk to write new versions. In other words, it always writes the latest version of a file to new locations.
As a result, old and no longer used versions of files will still take up space on the disk. To achieve this, a segment cleaning mechanism checks which segments are still active and cleans those that can be.
In short, this mechanism periodically reads the old segments and identifies which blocks are active. It then compresses and reallocates only the active blocks into new segments elsewhere on the disk. This way, it reduces the space used on the disk and frees up the region of that segment for new writes.
To identify active blocks, segments have a structure in the header called the segment summary block. This stores information such as its inode number and which block of the file it belongs to.
The LFS considers the block to be active if the information stored in this block, in the inode, and the inode map is linked. Otherwise, the system considers the block unused and can clean it up.
To optimize this process a little, LFS stores a version number for each file in the inode map. Together with the inode number, they form a unique identification (UID), which the segment summary blocks stores. So, if the block’s UID matches the UID stored by the inode map, the system keeps it active and doesn’t discard it. This format eliminates the need to query the inode.
To recover from a system crash, LFS employs two strategies: checkpoints, which define consistent states of the file system, and roll-forward, which is used to recover information saved since the last checkpoint.
The checkpoint is a point where all the file system structures are complete and consistent. It stores information such as the addresses of the blocks in the inode map, the most recent pointers to the inode map, and the start and end timestamps of the update.
By guarantee, a two-stage process is carried out. First, it writes all changes to the log. Next, it writes a checkpoint region to a fixed position on the disk. For consistency reasons, LFS keeps two of these regions on disk and updates them alternately.
This information is used during restart by the LFS to load its data structures into memory. To perform this task, the LFS considers the most recent and consistent region (comparing the start and end timestamps).
To execute roll-forward, LFS reads the sequential log to recover recent data, updates inodes in the map read from the checkpoint, and adjusts segment utilization. It uses directory operation logs to maintain consistency, which guarantees operations such as create or rename.
Following this process, the system writes a new checkpoint region, except for the unfinished creation of new files. With this, LFS ensures system restoration after crashes, integrating changes and maintaining consistency between inodes and segments.
In this article, we study the first Log-Structured File System (LFS). We’ve seen the techniques it uses to optimize disk recording.
Briefly, utilizing write buffers, inodes, inode maps, and well-defined segments, LFS optimizes sequential operations. The segmentation cleaning mechanism manages disk space, reducing the conflict of obsolete file versions. In case of system crashes, the dual-pronged approach of checkpoints and roll-forward ensures recovery.