

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll discuss the differences between the two types of parsers that have seen wide adoption in industry and academia – LL parsers and LR parsers. We’ll contrast them using grammar theory for a deeper understanding.
Both kinds of parsers fit into the syntax analysis phase of the compilation process. A compiler processes source code through a number of layers of abstraction, each with different inputs and outputs. The final output at the end of this pipeline is well-optimized machine code, targeted towards the architecture of the machine on which the compiler executed. As such, a parser must be both efficient in terms of runtime and powerful enough to handle the grammar in which the original source code was written.
In the classical formulation below, the lexical analyzer outputs a stream of tokens, and the syntax analyzer, of which the parser is a key component, generates a parse tree. How the parser is implemented, how the parse tree is constructed and the kind of grammars it can handle characterizes the fundamental differences between LL and LR:

LL parsing adheres to the top-down paradigm. In other words, the parse tree is constructed starting from the root, and each node is constructed in a pre-order pattern. It can be seen as the problem of finding a suitable leftmost derivation for the input string. For example, if our production rules are  and our desired string of terminal symbols is
and our desired string of terminal symbols is  , then one possible leftmost derivation is
, then one possible leftmost derivation is  .
.
At each step of a top-down parse, the parser determines the production rule to be applied for a given non-terminal grammar symbol  . Once a production rule is chosen, it then matches terminal symbols in the body of the production rule with the input string. A grammar is then designated as
. Once a production rule is chosen, it then matches terminal symbols in the body of the production rule with the input string. A grammar is then designated as  if the correct production rule can be chosen by looking
if the correct production rule can be chosen by looking  symbols ahead in the input. A typical value of is
symbols ahead in the input. A typical value of is  .
.
In contrast, LR parsing adheres to the bottom-up paradigm. The parse tree for an input string is constructed starting from the leaves and parsing continues upwards till it reaches the root. The goal is to reduce the input string to the start symbol  of the grammar or to construct a rightmost derivation in reverse.
of the grammar or to construct a rightmost derivation in reverse.
The parsing process consists of a series of shift and reduce-actions until we approach the start symbol. At each step, the specific substring matching the production rule body is replaced by the corresponding non-terminal symbol. Such a substring is called a handle. For e.g., given a set of production rules  which represents a simple mathematical expression and the input string
which represents a simple mathematical expression and the input string  , we’d move in reverse –
, we’d move in reverse –  . Note that
. Note that  is the start symbol in this case. Similar to the designation, we denote a grammar as
is the start symbol in this case. Similar to the designation, we denote a grammar as  if we can read the input by symbols ahead.
if we can read the input by symbols ahead.
There are certain rules for grammar to be designated as  or
or  . There cannot be any conflicts during the parsing process, because this would mean that the grammar is not suitable for the given parser. One example is that of a shift-reduce conflict in parsers, where at some step, the parser cannot decisively choose between a shift and a reduce-action.
. There cannot be any conflicts during the parsing process, because this would mean that the grammar is not suitable for the given parser. One example is that of a shift-reduce conflict in parsers, where at some step, the parser cannot decisively choose between a shift and a reduce-action.
A grammar is  if and only if whenever a production rule
if and only if whenever a production rule  exists, where
exists, where  and
and  are non-terminal symbols, the following holds -:
are non-terminal symbols, the following holds -:
 do and derive strings beginning with . derives the null symbol, then cannot derive any string beginning with a terminal in the
do and derive strings beginning with . derives the null symbol, then cannot derive any string beginning with a terminal in the  set of
set of  .
.The first two conditions can be summarized as  . The last condition can be summarized as
. The last condition can be summarized as  , where
, where  and are defined in the usual way. Correspondingly, these rules can be generalized for grammars with any positive integer .
and are defined in the usual way. Correspondingly, these rules can be generalized for grammars with any positive integer .
In contrast, there is a variety of parsers and corresponding grammars under the umbrella. The power of a parser is defined according to how large the subset of accepted grammar is. Among parsers, the  parser is at the bottom of this power scale.
parser is at the bottom of this power scale.
LR parsers make use of the  state automaton, and we’ll consider item-sets within a state when defining the rules for a grammar to be accepted. For e.g., a grammar is if it is accepted by the parser, which happens under the following conditions -:
state automaton, and we’ll consider item-sets within a state when defining the rules for a grammar to be accepted. For e.g., a grammar is if it is accepted by the parser, which happens under the following conditions -:
 (
( terminal) in those sets, there is no complete item
terminal) in those sets, there is no complete item  in the set, where
in the set, where  . This means that no shift-reduce conflict can exist.
. This means that no shift-reduce conflict can exist. and
and  ,
,  . This means that no reduce-reduce conflict can exist.
. This means that no reduce-reduce conflict can exist.Note that a complete item is one in which the dot is at the end of the production rule, and it refers to the case where the parser can only perform a reduce-action using that production rule.
Higher-powered parsers such as the canonical  and
and  have similar rules for the grammars they accept. Note that grammars are a subset of grammars, so parsers possess less power than parsers:
have similar rules for the grammars they accept. Note that grammars are a subset of grammars, so parsers possess less power than parsers:
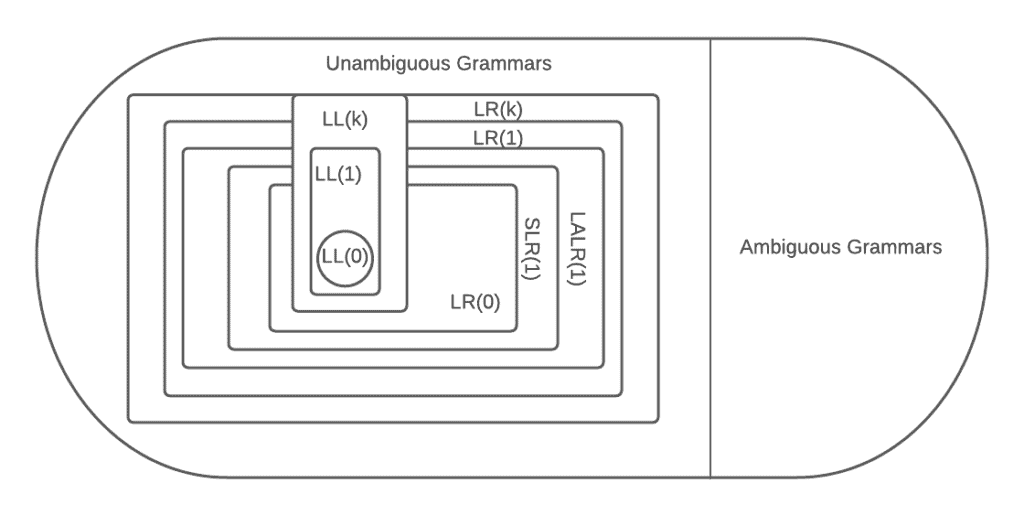
LL parsers such as the table-driven predictive parser cannot process strings from grammars that possess left-recursive production rules. Intuitively, this is because they may end up in an infinite loop while trying to process the leftmost derivation. In our earlier example of such a derivation, the rule  cannot be allowed in the grammar for this reason. However, parsers do not have this weakness and can process input strings from grammars that have left-recursive rules.
cannot be allowed in the grammar for this reason. However, parsers do not have this weakness and can process input strings from grammars that have left-recursive rules.
Note that among the popular top-down parsers, the recursive-descent parser is able to process strings from grammars outside the set, but the execution is not guaranteed to terminate if the grammar is not . In fact, even if it does terminate, it may take exponential time in the worst case. This is in contrast to the table-driven predictive parser, which cannot process strings from grammars outside the set at all. Thus they are both considered primarily parsers.
Both LL and LR parsers have trouble processing strings from ambiguous grammars. Ambiguity inserts conflicts in the parsing process, and so, the set of ambiguous grammars is generally considered separate from the set of / grammars. But while no parser can process ambiguity, there is a type of parser that can process a subset of grammars known as operator grammars. This parser is suitably called an operator-precedence parser.
Ambiguity as in the traditional sense – which rule to apply next – is allowed in the operator grammar. This is because production rules are framed in a way that assigns relative precedence. The operator-precedence parser exploits these precedence rules during execution to quell ambiguity.
In summary, we’ve covered at length some of the differences between and parsers. We delved into grammar theory for a deeper and more fundamental understanding. In the process, we discussed several kinds of parsers.