

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Finding the Kth Smallest Element in the Union of Two Sorted Arrays
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Overview
In this tutorial, we’ll discuss the problem of finding the kth smallest element in the union of two sorted arrays. We’ll present a naive approach and then improve it.
In the end, we’ll present a comparison between both approaches and when to use them.
Please note that we have a java-based article for this problem. Hence, in this tutorial, we’ll focus more on the theoretical idea and comparison.
2. Defining the Problem
In this problem, we’re given 2 arrays,  of size
of size  , and
, and  of size
of size  . Also, the problem will give us an integer
. Also, the problem will give us an integer  . Both arrays and should be sorted in increasing order.
. Both arrays and should be sorted in increasing order.
In other words:
 for each
for each 
 for each
for each 
We must find the kth smallest element in the sorted union of and . By the sorted union of and , we mean the array  of size
of size  , which contains all the elements of and , sorted in the increasing order as well.
, which contains all the elements of and , sorted in the increasing order as well.
Let’s take the following example to better explain the idea:
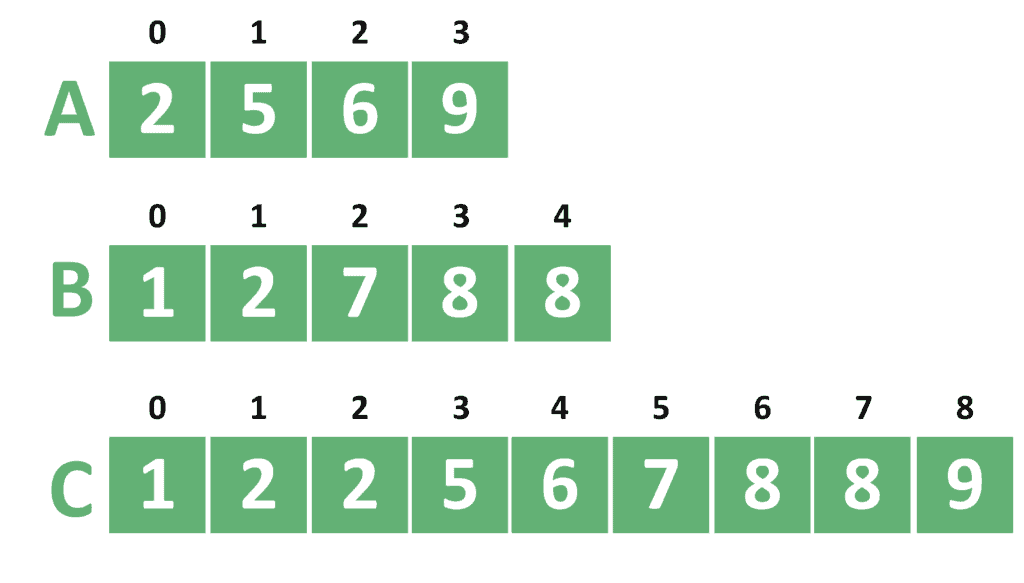
As we can see, both arrays and are sorted initially. Similarly, the array , which is the union of arrays and , is sorted as well. Also, we can see that the array contains all elements from and .
Hence, if was equal to 6, then the answer would be 7. The reason is that 7 is at index 5 in the array (because we start numbering the array from zero).
Another way to look at it is that the number 7 has five numbers smaller than it in both arrays and . Therefore, it’s the sixth smallest value.
3. Naive Approach
First, we’ll explore the naive approach. Let’s take a look at its implementation:
algorithm NaiveApproach(A, B, n, m, k):
// INPUT
// A = The first sorted array
// B = The second sorted array
// n = The size of the first array
// m = The size of the second array
// k = The order of the required element
// OUTPUT
// Returns the kth smallest element in the union of A and B
i <- 0
j <- 0
answer <- 0
while i + j < k:
if i = n:
answer <- B[j]
j <- j + 1
else if j = m:
answer <- A[i]
i <- i + 1
else if B[j] < A[i]:
answer <- B[j]
j <- j + 1
else:
answer <- A[i]
i <- i + 1
return answerIn the beginning, we set two iterators  and
and  that will show us the current index inside the arrays and , respectively.
that will show us the current index inside the arrays and , respectively.
Now, let’s think about how we’d merge arrays and . We’d start from the beginning. Each time, we’d add the smallest value to the resulting array. Also, we’d remove the smallest value from its location. Let’s do something similar in this approach.
In each step, we set the answer to the smaller value between ![A[i]](/wp-content/ql-cache/quicklatex.com-42484bff0529bb02d3d57d306e1b611b_l3.svg "Rendered by QuickLaTeX.com") and
and ![B[j]](/wp-content/ql-cache/quicklatex.com-69dc117c3f8d86b2a58de95f872e1522_l3.svg "Rendered by QuickLaTeX.com") . In addition, we transfer the iterator who has this smaller value one step forward.
. In addition, we transfer the iterator who has this smaller value one step forward.
Also, we pay attention to the case when either or becomes out of the range of their respective arrays. In this case, we move the other iterator. Once we finish walking through values, we break the while loop.
In the end, we return the stored answer.
The complexity of the naive approach is  , where is the required index. Therefore, in the worst case, the complexity is
, where is the required index. Therefore, in the worst case, the complexity is  , where is the size of the first array and is the size of the second one.
, where is the size of the first array and is the size of the second one.
4. Binary Search Approach
Let’s try to improve our naive approach.
4.1. General Idea
As we know, the binary search is a searching algorithm that finds the target value within a sorted range. In each step, we divide the range in half.
Next, we check the value in the middle of the range. Based on the result, we either choose the left or the right half of the range to continue our search in. We’ll use something similar here.
In the naive approach, we found the answer by taking elements from and elements from . Based on the same idea, we’ll perform a binary search to find the number of taken elements from the first array .
In each step, we can calculate the number of taken elements from the second array which is  . After that, we can check whether this combination of and is valid or not. Based on the result, we can choose to take either more or fewer elements from .
. After that, we can check whether this combination of and is valid or not. Based on the result, we can choose to take either more or fewer elements from .
4.2. Implementation
Take a look at the binary search approach:
algorithm BinarySearchApproach(A, B, n, m, k):
// INPUT
// A = The first sorted array
// B = The second sorted array
// n = The size of the first array
// m = The size of the second array
// k = The order of the required element
// OUTPUT
// Returns the kth smallest element in the union of A and B
bestI <- 0
L <- max(0, k - m)
R <- n
while L <= R:
mid <- (L + R) / 2
i <- mid
j <- k - i
if j = 0 or A[i - 1] > B[j - 1]:
R <- mid - 1
bestI <- mid
else:
L <- mid + 1
i <- bestI
j <- k - i
if i != 0:
return min(B[j], A[i - 1])
else:
return B[j - 1]
First of all, we’ll choose the range we should search in. Clearly, the right side should equal to  .
.
However, when choosing the left side, the size of the array must be taken into account. Therefore, the left side shouldn’t be less than  , nor less than zero.
, nor less than zero.
Now, we can use the binary search algorithm to find the smallest , such that the biggest value in range ![[0..i]](/wp-content/ql-cache/quicklatex.com-c7ff26c3afbff324f5821772ab10896d_l3.svg "Rendered by QuickLaTeX.com") from is bigger than the biggest value in range
from is bigger than the biggest value in range ![[0..k-i]](/wp-content/ql-cache/quicklatex.com-0066a450269301a983fcd7e2ad1486c7_l3.svg "Rendered by QuickLaTeX.com") from . As we can see, we’re taking elements from and
from . As we can see, we’re taking elements from and  elements from . Therefore, in total, we take elements.
elements from . Therefore, in total, we take elements.
In each step, we compare the two values we have. If we choose not to take any elements from , or the value of ![A[i-1]](/wp-content/ql-cache/quicklatex.com-4edb29d9a23d7e505ed667a819723ca2_l3.svg "Rendered by QuickLaTeX.com") is larger than
is larger than ![B[j-1]](/wp-content/ql-cache/quicklatex.com-d0392f66432b60adac6e9b0d8c6a46f2_l3.svg "Rendered by QuickLaTeX.com") , then we know we reached a valid value of and store it. We should also try to find a smaller value of . Therefore, we make the searching range equal to the left one.
, then we know we reached a valid value of and store it. We should also try to find a smaller value of . Therefore, we make the searching range equal to the left one.
Otherwise, it means we should move forward. In this case, we make the searching range equal to the right one.
In the end, we have two cases. Either equals zero, which means we shouldn’t take any elements from . As a result, the answer will equal to .
On the other hand, if we should take some elements from , then the kth smallest value is either or . The reason is that we know that is bigger than all elements in the range ![B[0..j-1]](/wp-content/ql-cache/quicklatex.com-d37047f86e8cc3deee44ee3b1c9fd248_l3.svg "Rendered by QuickLaTeX.com") .
.
Therefore, the answer is either itself, or , whichever is the smallest.
The complexity of the binary search approach is  , where is the size of the first array.
, where is the size of the first array.
4.3. Example
Let’s take the same example in section 2, where we had two arrays and , and was 6. Take a look at the first step in that example:
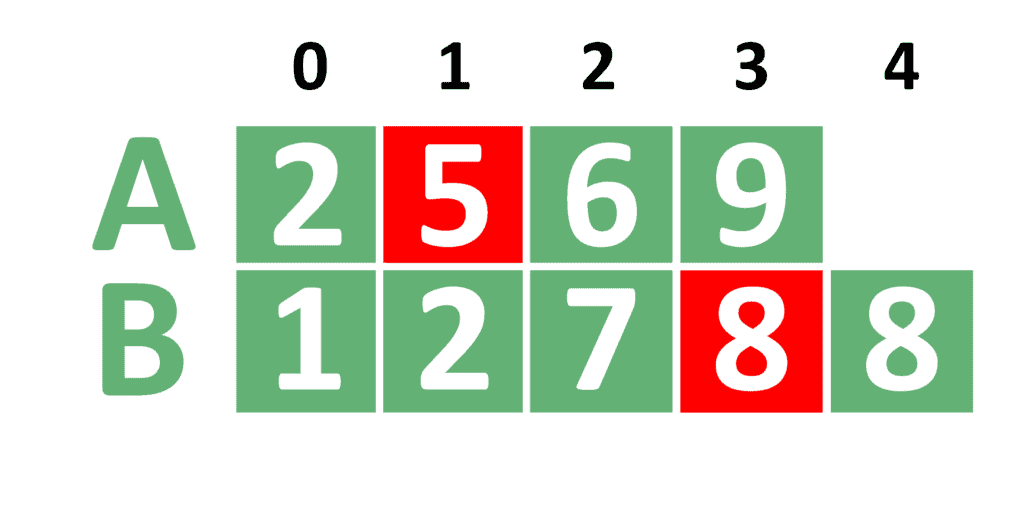
In the beginning, the searching range is ![[0, 4]](/wp-content/ql-cache/quicklatex.com-8fd299814e4f95f4b16515153d0e48c9_l3.svg "Rendered by QuickLaTeX.com") . Hence,
. Hence,  equals 2. Therefore, equals 2 and equals 4.
equals 2. Therefore, equals 2 and equals 4.
We compare the values of and . Since is not greater than , we try to search on the right range of the array , without updating the value of  .
.
Note that, and represent the number of elements to take from each array. Since indexes start from zero, we compare with . Also, note that the cells in red denote the values that are being compared in each step.
Let’s move to the next step:
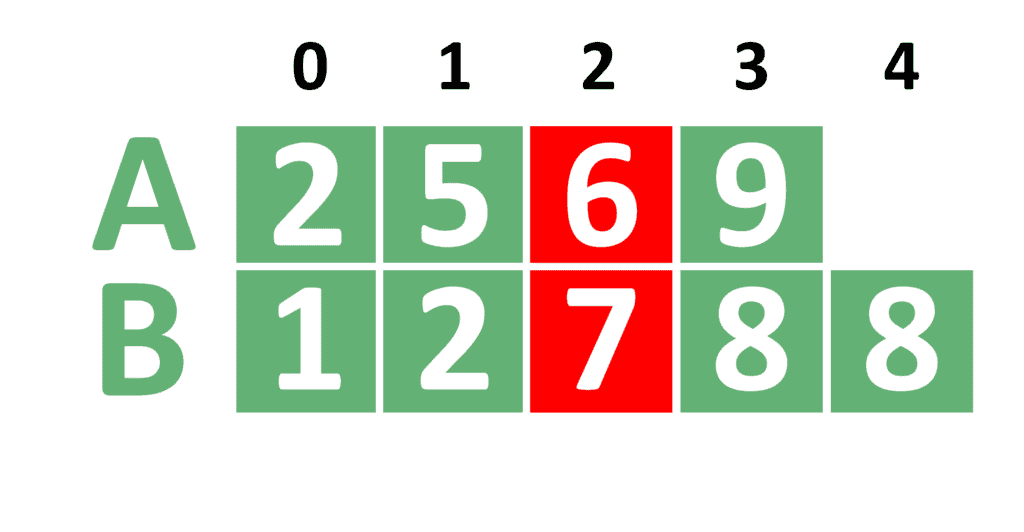
In the next step, the searching range becomes ![[3, 4]](/wp-content/ql-cache/quicklatex.com-4d9485055382aea003d4da7748694484_l3.svg "Rendered by QuickLaTeX.com") . From that we conclude that equals 3, equals 3 and equals 3.
. From that we conclude that equals 3, equals 3 and equals 3.
We notice that is still not greater than . Thus, we continue searching on the right range of the array , without updating the value of .
This leads us to the last step:
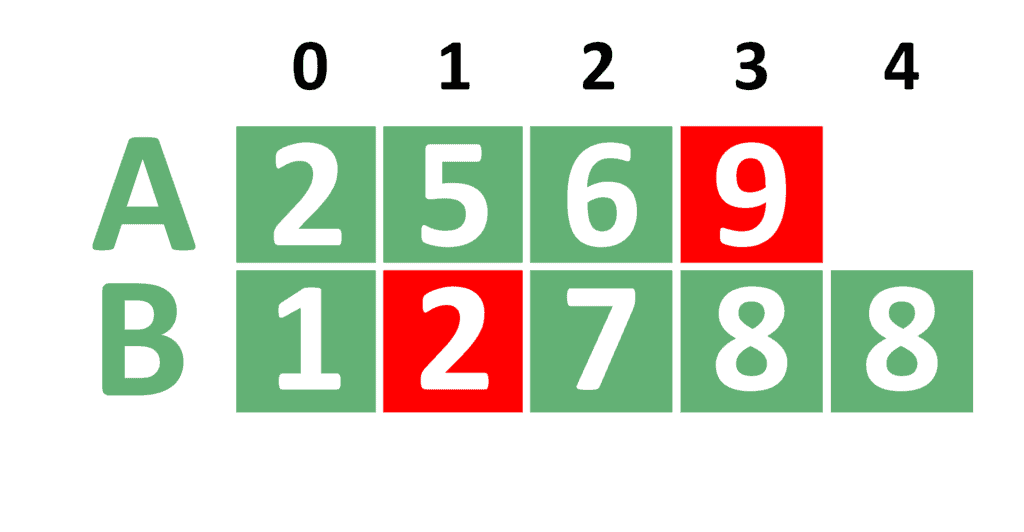
Finally, the searching range is now ![[4, 4]](/wp-content/ql-cache/quicklatex.com-c9834bc8c38a509ecd8432962592e0b9_l3.svg "Rendered by QuickLaTeX.com") . This means that equals 4, equals 4 and equals 2. In this case, we notice that is actually greater than . As a result, we update the value of .
. This means that equals 4, equals 4 and equals 2. In this case, we notice that is actually greater than . As a result, we update the value of .
The searching range becomes ![[4, 3]](/wp-content/ql-cache/quicklatex.com-7977a019696c70732fb8188fccf16369_l3.svg "Rendered by QuickLaTeX.com") , which is invalid. Therefore, the algorithm doesn’t make any more steps.
, which is invalid. Therefore, the algorithm doesn’t make any more steps.
Now that the binary search operation is finished, the answer is the minimum between and . In this case, ![A[3]](/wp-content/ql-cache/quicklatex.com-9d02c98bf9801af671ede0f218984266_l3.svg "Rendered by QuickLaTeX.com") is 9 and
is 9 and ![B[2]](/wp-content/ql-cache/quicklatex.com-adb62cffc990ee6495939fb97307921f_l3.svg "Rendered by QuickLaTeX.com") is 7. Hence, the algorithm returns 7 as the answer to the problem.
is 7. Hence, the algorithm returns 7 as the answer to the problem.
5. Comparison
When considering simplicity, the naive approach is both simpler to implement, and easier to understand. But, when considering the time complexity, the binary search approach generally has a lower complexity.
However, in the special case that is smaller than  , using the naive approach should give us a better complexity.
, using the naive approach should give us a better complexity.
6. Conclusion
In this tutorial, we explained the problem of calculating the Kth smallest element in the union of two sorted arrays. Firstly, we presented the naive approach.
Secondly, we discussed the theoretical idea and the implementation of the binary search approach.
Finally, we presented a summary comparison between both approaches and showed when to use each one.