

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll present the Jump Search algorithm.
In a classical search problem, we have a value  and a sorted array
and a sorted array  with
with  elements. Our task is to find the index
elements. Our task is to find the index  of in .
of in .
If is a linked list, it doesn’t have indices. Instead, each element is a  pair, so we’re looking for the item whose key is . We’ll denote the th element of the list as
pair, so we’re looking for the item whose key is . We’ll denote the th element of the list as ![x[i]](/wp-content/ql-cache/quicklatex.com-9d0d86868fc69016d5aa6ff64058ae13_l3.svg "Rendered by QuickLaTeX.com") just as we do with arrays.
just as we do with arrays.
However, if is an array, we can access any element in an  time (assuming that fits into the main memory). In contrast, if
time (assuming that fits into the main memory). In contrast, if  is a list, we need to follow
is a list, we need to follow  pointers to reach
pointers to reach ![\boldsymbol{x[i]}](/wp-content/ql-cache/quicklatex.com-e871bc383f3f87bc4d50c5ee20db6d8f_l3.svg "Rendered by QuickLaTeX.com") , so the complexity of access is
, so the complexity of access is  . In the worst case, we want to reach the end of the list, so we traverse all the elements to get to it, which takes
. In the worst case, we want to reach the end of the list, so we traverse all the elements to get to it, which takes  time.
time.
That’s why an array search algorithm such as Binary Search isn’t suitable for singly-linked lists. It checks the elements of back and forth, but going back isn’t an operation when is a list, and checking ![x[j]](/wp-content/ql-cache/quicklatex.com-28ba9658ecf906b3c7270d0544dca898_l3.svg "Rendered by QuickLaTeX.com") after (
after ( ) takes more than a constant time.
) takes more than a constant time.
Jump Search is a list search algorithm but can handle arrays equally well. It assumes that its input is a sorted linked list. That means that each element’s key should be  than the next one’s.
than the next one’s.
The algorithm partitions into the sub-lists of the same size, ![x[1:m], x[m+1:2m]](/wp-content/ql-cache/quicklatex.com-73e2e5fd498ca86510bd6c2d37652181_l3.svg "Rendered by QuickLaTeX.com") ,
, ![x[2m+1:3m]](/wp-content/ql-cache/quicklatex.com-b9d868bbcc9674d837cf7141cabd4a59_l3.svg "Rendered by QuickLaTeX.com") ,
,  ,
, ![x[(\lfloor n / m \rfloor - 1) m : n]](/wp-content/ql-cache/quicklatex.com-8c7e88ca7625ec696b19dc35f7289123_l3.svg "Rendered by QuickLaTeX.com") and checks them iteratively until locating the one whose boundaries contain :
and checks them iteratively until locating the one whose boundaries contain :
![\[x[j \cdot m + 1] \leq z \leq x[(j+1)m]\]](/wp-content/ql-cache/quicklatex.com-d1602aea7c6fc1932f7998560685f353_l3.svg "Rendered by QuickLaTeX.com")
Once the sub-list is found, the algorithm checks its elements one by one until finding or reaching the last one in the sub-list if isn’t there.
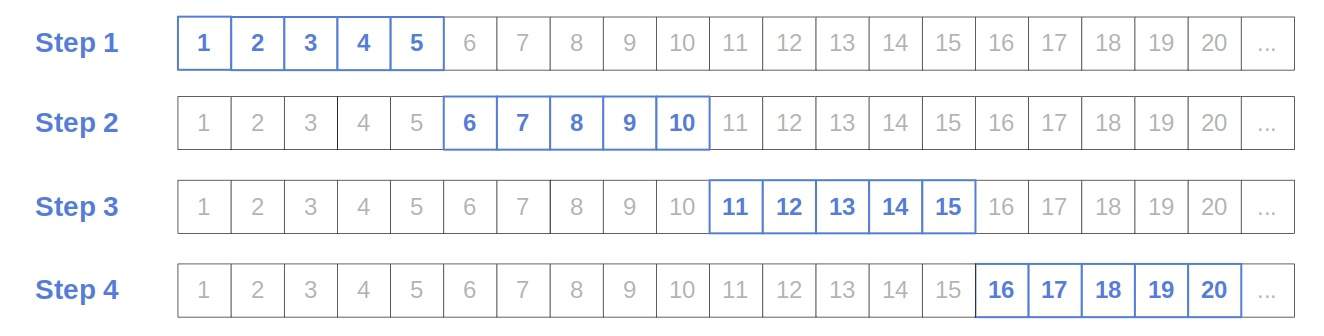
The name comes from the jumps of size  between the steps. For instance, this is how the algorithm runs when
between the steps. For instance, this is how the algorithm runs when  :
:
Here’s the pseudocode:
algorithm JumpSearch(x, z, m):
// INPUT
// x = a sorted list with n (key, item) pairs
// z = the key to find in x
// m = the jump size
// OUTPUT
// If z is in x, returns the item of x whose key is z. Otherwise, returns "failure".
left <- x.head
right <- follow m pointers from left to reach the mth element
while right != NULL and not (left.key <= z < right.key):
left <- right.next
right <- follow m pointers starting from right
if right = NULL:
return "failure"
else:
while left != right.next and left.key != z:
left <- left.next
if left = right.next:
return "failure"
else:
return left.itemWe can set to any value we like, but the algorithm’s complexity depends on our choice of .
Let’s say that our list has elements. In the worst case, we check all the  sub-lists’ boundaries and compare all the elements in the last sub-list to . So, we perform
sub-lists’ boundaries and compare all the elements in the last sub-list to . So, we perform  comparisons.
comparisons.
The minimum of  is
is  when
when  . So, if we set
. So, if we set  to
to  , Jump Search will run in
, Jump Search will run in  time with respect to the number of comparisons.
time with respect to the number of comparisons.
However, to reach the new sub-list’s end, we need to follow pointers from the previous step’s  . As a result, we traverse all nodes in the worst case. So, the algorithm has an worst-case time complexity if we consider node traversals. However, if a comparison is more complex than following a pointer, we can say that the complexity is
. As a result, we traverse all nodes in the worst case. So, the algorithm has an worst-case time complexity if we consider node traversals. However, if a comparison is more complex than following a pointer, we can say that the complexity is  .
.
As we said before, Jump Search can handle arrays too. We prefer it over logarithmic Binary Search when going back (e.g., from testing if ![\boldsymbol{x[n/2]=z}](/wp-content/ql-cache/quicklatex.com-ecb127a9dc8b26cc34f3342f68f7a698_l3.svg "Rendered by QuickLaTeX.com") to checking whether
to checking whether ![\boldsymbol{x[n/4]=z}](/wp-content/ql-cache/quicklatex.com-0b6e7e0ef8287ca019a0f13eb3791246_l3.svg "Rendered by QuickLaTeX.com") ) is expensive or impossible.
) is expensive or impossible.
That can happen when is so large that it can’t fit into the working memory or is a stream of data we’re downloading from an external source. In the former case, requesting ![x[j/2]](/wp-content/ql-cache/quicklatex.com-1cfa5d26cfbd75bb31fd88e4c81d3fd5_l3.svg "Rendered by QuickLaTeX.com") after might require loading new blocks from the disk into RAM. In the latter case, downloading individual elements is expensive since we get them over a network, so going back and forth like in Binary Search would be slow.
after might require loading new blocks from the disk into RAM. In the latter case, downloading individual elements is expensive since we get them over a network, so going back and forth like in Binary Search would be slow.
In this article, we presented the Jump Search algorithm. We use it to search singly-linked lists in time, but it can also search arrays.