

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll delve into the workings of the Interpolation Search algorithm, exploring its principles, advantages, and limitations.
In the vast landscape of computer science and data analysis, quickly locating desired information is vital. Searching algorithms are at the core of various applications, from simple data structures to databases.
A fundamental requirement for searching algorithms is efficiency, especially when dealing with massive datasets where the search time can become a bottleneck. The classical searching methods, such as linear and binary searches, have served well, but they aren’t optimal in all cases:
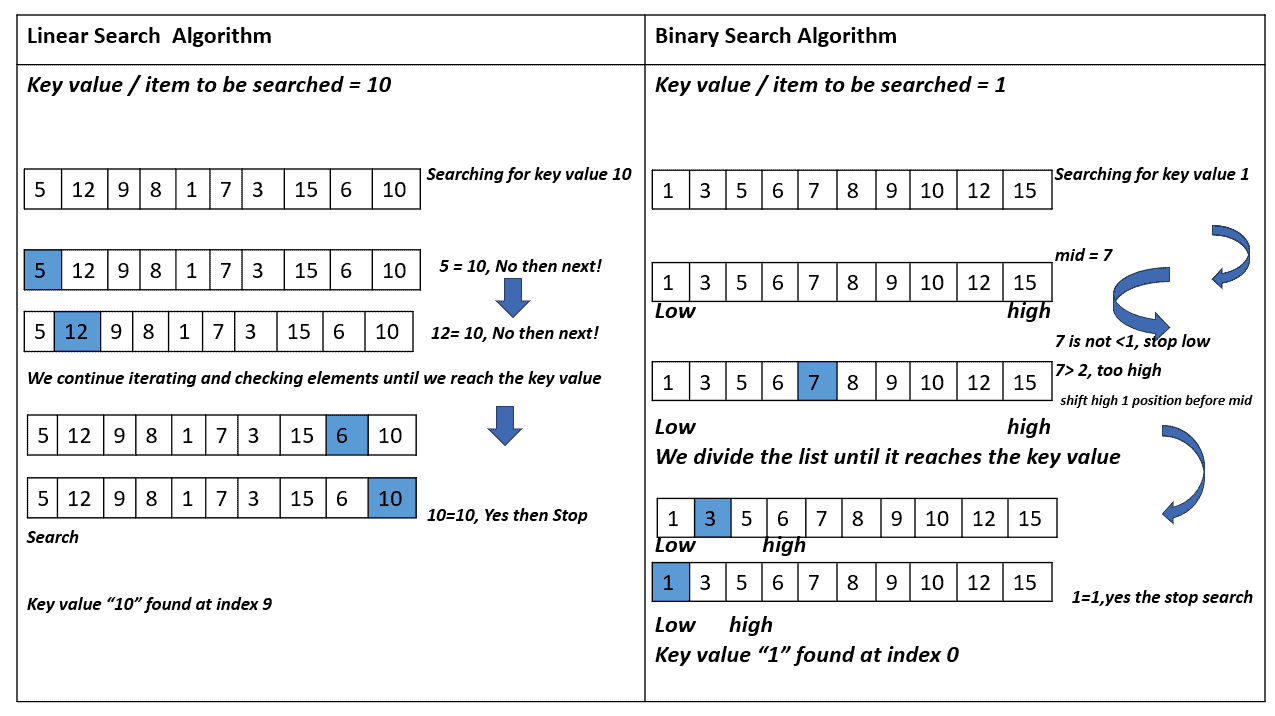
In the case of linear search, we need to iterate through the entire list, checking each element until we reach the target at the end of the array. This is the worst-case scenario for linear search.
Similarly, binary search will continually divide the array in half until it reaches the position of the target. In our example, that’s the first element. However, the target’s actual position could be found faster if binary search adapted to the values in the array.
The Interpolation Search algorithm has been designed to overcome the limitations of traditional search methods and enhance search efficiency for large datasets. It uses mathematical interpolation to estimate the position of the target element, potentially leading to faster search times.
This algorithm combines Binary Search with linear interpolation, making it suitable for sorted arrays and effectively handling non-uniformly distributed values.
It determines the target element’s position based on its value and the extreme values within the currently searched section of the array. Subsequently, this estimated position undergoes further refinement in successive steps until the target is found or considered absent. Compared to Linear Search, Interpolation Search covers more significant portions of the input array with each step.
Here’s the pseudocode:
algorithm InterpolationSearch(arr, target):
// INPUT
// arr = sorted array
// target = target element to find
// OUTPUT
// the index of target in arr, or -1 if target is not in arr
low <- 0
high <- length(arr) - 1
while low <= high and arr[low] <= target <= arr[high]:
if low = high:
if arr[low] = target:
return low
else:
return -1
pos <- low + ceil((target - arr[low]) * (high - low) / (arr[high] - arr[low]))
if pos < low or pos > high:
return -1
if arr[pos] = target:
return pos
else if arr[pos] < target:
low <- pos + 1
else:
high <- pos - 1
return -1The algorithm repeatedly estimates the position of the target element based on its value and the values at the extremes of the search portion of the array. It stops if it finds the element or infers it isn’t in the array.
The efficiency of the Interpolation Search algorithm lies in its mathematical formula, which estimates the position of the target element. Given a sorted sub-array with start and end indices  and
and  , and a target value
, and a target value  , the estimated position
, the estimated position  of is:
of is:
![\[pos = low + \left\lceil \frac{(target - arr[low]) \cdot (high - low)}{arr[high] - arr[low]}) \right\rceil\]](/wp-content/ql-cache/quicklatex.com-9530a8457c2b5f9002c0032f7bcb8579_l3.svg "Rendered by QuickLaTeX.com")
Here,  is our sorted array. We round the index to the nearest lower integer since the fraction might be float, and indices are integers.
is our sorted array. We round the index to the nearest lower integer since the fraction might be float, and indices are integers.
Let’s say we have a sorted array of integers: ![[10, 20, 30, 40, 50, 60, 70, 80, 90, 100]](/wp-content/ql-cache/quicklatex.com-66e1bcab261801b8c823a650ed3fbd0a_l3.svg "Rendered by QuickLaTeX.com") . Our target element is 60, and we want to find its index using Interpolation Search.
. Our target element is 60, and we want to find its index using Interpolation Search.
Initially, we set the search range to  and
and 
Then, we calculate the estimated position using linear interpolation:
![\[low + ((target - arr[low]) (high - low)/ (arr[high] - arr[low])) = 0 + ((60 - 10) (9 - 0)/ (100 - 10)) = 5\]](/wp-content/ql-cache/quicklatex.com-4130758642743052351606cf06c4be73_l3.svg "Rendered by QuickLaTeX.com")
Since ![arr[5]=60](/wp-content/ql-cache/quicklatex.com-ffab14ca34e50224498ec8f41a2af6dc_l3.svg "Rendered by QuickLaTeX.com") , we have found the element and return 5 as its index.
, we have found the element and return 5 as its index.
Understanding the complexity of the Interpolation Search algorithm is crucial to evaluating its efficiency and applicability in various scenarios.
In the best case, the array is uniformly distributed, and the target element is found early. So, Interpolation Search approaches the time complexity of  . This is because the estimated position often leads directly to the target.
. This is because the estimated position often leads directly to the target.
Conversely, in the worst case, the Interpolation Search may behave as Linear Search, mainly when dealing with non-uniformly distributed data. In some non-uniform cases, the time complexity could be  , where
, where  is the size of the input array.
is the size of the input array.
Turning to the average case, the time complexity of Interpolation Search is approximately  for uniformly distributed data, which is an improvement over
for uniformly distributed data, which is an improvement over  of Binary Search.
of Binary Search.
The space complexity is low. It’s since we need to store the input array and have a constant number of auxiliary variables (such as  ).
).
The Interpolation Search algorithm offers several advantages over traditional searching methods,
Interpolation Search exhibits excellent performance for uniformly distributed arrays.
Each step covers larger portions of the array, leading to faster convergence toward the target.
The algorithm’s efficiency becomes more pronounced as the array size increases.
Linear search may become impractical for large datasets, but Interpolation Search can still provide reasonable search times.
If the target element isn’t in the array, Interpolation Search may identify this early and terminate the search sooner.
This search technique efficiently estimates the target’s location by considering array distribution.
It computes proportional intervals, enabling precise targeting in skewed datasets. It’s responsive to irregular data distributions. This adaptability enhances search efficiency across varying array structures, making interpolation search a versatile choice for non-uniform datasets.
Despite its efficiency, Interpolation Search has some limitations we need to consider.
The array values should be uniformly distributed for the algorithm to perform optimally.
It still works in non-uniform cases, but its efficiency may decline depending on the distribution. That’s because estimating the target’s position can become less precise due to uneven value distribution, potentially requiring more interpolation steps. Its complexity approaches for some non-uniform distributions.
The Interpolation Search algorithm requires a sorted array to operate correctly.
If the array isn’t sorted, it must be sorted first, adding an initial overhead.
In this article, we explored the interpolation search algorithm. The Interpolation Search algorithm offers a compelling alternative to traditional searching techniques such as Binary Search and Linear Search.
By estimating the probable position of the target element within the sorted array, Interpolation Search offers a more efficient approach for large datasets. Despite its limitations, the algorithm has found significant applications in various real-world scenarios, especially when speed and precision are crucial.
While it excels in uniformly distributed datasets due to its accurate position estimation, its performance can be less reliable in non-uniform cases, contingent on the data distribution.