Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: January 11, 2022

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll discuss graph adjacency and incidence. Also, we’ll show how to use them to represent a graph.
In computer science, a graph  is a data structure that consists of a set of vertices
is a data structure that consists of a set of vertices  and edges
and edges  . An edge
. An edge  is a pair of vertices
is a pair of vertices  , where
, where  . For example, the following picture shows a graph with
. For example, the following picture shows a graph with  vertices and
vertices and  edges:
edges:
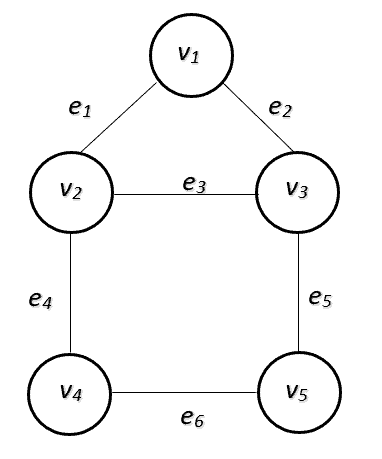
If two vertices in a graph are connected by an edge, we say the vertices are adjacent. In our graph example, vertex  has two adjacent vertices,
has two adjacent vertices,  and
and  . Base on this property, we can use an adjacency matrix or adjacency list to represent a graph.
. Base on this property, we can use an adjacency matrix or adjacency list to represent a graph.
Suppose we have a graph with  vertices, we can use a square
vertices, we can use a square  matrix to represent the adjacency relationships among these vertices. For example, the adjacency matrix of the example graph is:
matrix to represent the adjacency relationships among these vertices. For example, the adjacency matrix of the example graph is:
|
|
|
 |
 |
|
|---|---|---|---|---|---|
|
0 | 1 | 1 | 0 | 0 |
|
1 | 0 | 1 | 1 | 0 |
|
1 | 1 | 0 | 0 | 1 |
|
0 | 1 | 0 | 0 | 1 |
|
0 | 0 | 1 | 1 | 0 |
In this matrix, the number  means the corresponding two vertices are adjacent. Otherwise, the entry value is
means the corresponding two vertices are adjacent. Otherwise, the entry value is  . Since we have
. Since we have  entries, the space complexity of the adjacency matrix is
entries, the space complexity of the adjacency matrix is  .
.
To build the adjacency matrix, we can go through all edges and set 1 to the corresponding vertex-vertex entry. Therefore, the time complexity to build this matrix is  , where
, where  is the number of graph edges.
is the number of graph edges.
We can also use an adjacency list to represent a graph. For example, the adjacency list of the example graph is:
|
, |
|---|---|
|
, , |
|
, , |
|
, |
|
, |
In this table, each row contains a list of vertices that is adjacent to the current vertex  . Each pair represent an edge in the graph. Therefore, the space complexity of the adjacency list is . Similarly, we need time to build the adjacency list.
. Each pair represent an edge in the graph. Therefore, the space complexity of the adjacency list is . Similarly, we need time to build the adjacency list.
For a dense graph, where the number of edges is in the order of , the adjacency matrix and adjacency list have the same time and space complexity. However, if the graph is sparse, we need less space to represent the graph. Therefore, an adjacency list is more space-efficient than an adjacency matrix when we work on sparse graphs.
However, there are some graph operations where the adjacency matrix is more efficient to use. For example, when we want to check if there exists an edge in the graph, we can just look up the adjacency matrix in constant time to get the result. If we use the adjacency list, it will take us  time to check.
time to check.
Another example is to remove an edge from the graph. In the adjacency matrix, we can just set to the corresponding entries in constant time. However, we need time to remove the vertex from the adjacency list.
In a graph , two edges are incident if they share a common vertex. For example, edge  and edge
and edge  are incident as they share the same vertex .
are incident as they share the same vertex .
Also, we can define the incidence over a vertex. A vertex is an incident to an edge if the vertex is one of the two vertices the edge connects. Therefore, an incidence is a pair  where
where  is a vertex and is an edge incident to .
is a vertex and is an edge incident to .
Base on this property, we can use an incidence matrix to represent a graph. For example, the incidence matrix of the example graph is:
 |
 |
 |
 |
 |
 |
|
|---|---|---|---|---|---|---|
|
1 | 1 | 0 | 0 | 0 | 0 |
|
1 | 0 | 1 | 1 | 0 | 0 |
|
0 | 1 | 1 | 0 | 1 | 0 |
|
0 | 0 | 0 | 1 | 0 | 1 |
|
0 | 0 | 0 | 0 | 1 | 1 |
In this matrix, rows represent vertices and columns represent edges. Therefore, the space complexity of the incidence matrix is  . To build the incidence matrix, we can go through all edges and set 1 to the corresponding vertex-edge entry. Therefore, the time complexity to build this matrix is .
. To build the incidence matrix, we can go through all edges and set 1 to the corresponding vertex-edge entry. Therefore, the time complexity to build this matrix is .
The incidence matrix  and adjacency matrix
and adjacency matrix  of a graph have a relationship of
of a graph have a relationship of  , where
, where  is the identity matrix.
is the identity matrix.
The incidence matrix has more space complexity than the other graph representations. We normally use it in theoretic graph areas. e.g., incidence coloring of a graph.
This article provided the definitions of adjacency and incidence in graph theory. Also, we showed different ways to represent a graph using adjacency and incidence.