

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll learn one of the main aspects of Graph Theory — graph representation. The two main methods to store a graph in memory are adjacency matrix and adjacency list representation. These methods have different time and space complexities.
Thus, to optimize any graph algorithm, we should know which graph representation to choose. The choice depends on the particular graph problem. In this article, we’ll use Big-O notation to describe the time and space complexity of methods that represent a graph.
It’s important to remember that the graph is a set of vertices  that are connected by edges
that are connected by edges  . An edge is a pair of vertices
. An edge is a pair of vertices  , where
, where  . Each edge has its starting and ending vertices. If graph is undirected,
. Each edge has its starting and ending vertices. If graph is undirected,  . But, in directed graph the order of starting and ending vertices matters and
. But, in directed graph the order of starting and ending vertices matters and  .
.
Here is an example of an undirected graph, which we’ll use in further examples:
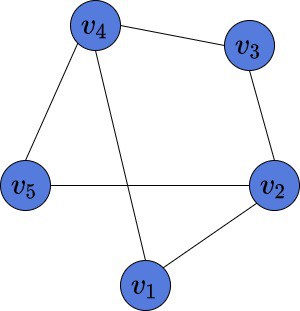
This graph consists of 5 vertices  , which are connected by 6 edges
, which are connected by 6 edges  , and
, and  .
.
Some graphs might have many vertices, but few edges. These ones are called sparse. On the other hand, the ones with many edges are called dense. Our graph is neither sparse nor dense. However, in this article, we’ll see that the graph structure is relevant for choosing the way to represent it in memory.
The first way to represent a graph in a computer’s memory is to build an adjacency matrix. Assume our graph consists of  vertices numbered from
vertices numbered from  to . An adjacency matrix is a binary matrix of size
to . An adjacency matrix is a binary matrix of size  . There are two possible values in each cell of the matrix: 0 and 1. Suppose there exists an edge between vertices
. There are two possible values in each cell of the matrix: 0 and 1. Suppose there exists an edge between vertices  and
and  . It means, that the value in the
. It means, that the value in the  row and
row and  column of such matrix is equal to 1. Importantly, if the graph is undirected then the matrix is symmetric.
column of such matrix is equal to 1. Importantly, if the graph is undirected then the matrix is symmetric.
Here is an example of an adjacency matrix, corresponding to the above graph:
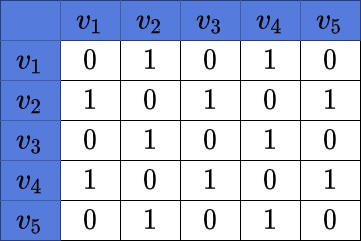
We may notice the symmetry of the matrix. Also, we can see, there are 6 edges in the matrix. It means, there are 12 cells in its adjacency matrix with a value of 1.
Assuming the graph has  vertices, the time complexity to build such a matrix is
vertices, the time complexity to build such a matrix is  . The space complexity is also . Given a graph, to build the adjacency matrix, we need to create a square matrix and fill its values with 0 and 1. It costs us
. The space complexity is also . Given a graph, to build the adjacency matrix, we need to create a square matrix and fill its values with 0 and 1. It costs us  space.
space.
To fill every value of the matrix we need to check if there is an edge between every pair  of vertices. The amount of such pairs of given vertices is
of vertices. The amount of such pairs of given vertices is  . That is why the time complexity of building the matrix is .
. That is why the time complexity of building the matrix is .
The advantage of such representation is that we can check in  time if there exists edge
time if there exists edge  by simply checking the value at
by simply checking the value at  row and
row and  column of our matrix.
column of our matrix.
However, this approach has one big disadvantage. We need space in the only case — if our graph is complete and has all edges. The matrix will be full of ones except the main diagonal, where all the values will be equal to zero. But, the complete graphs rarely happens in real-life problems. So, if the target graph would contain many vertices and few edges, then representing it with the adjacency matrix is inefficient.
The other way to represent a graph in memory is by building the adjacent list. If the graph consists of vertices, then the list  contains elements. Each element
contains elements. Each element  is also a list and contains all the vertices, adjacent to the current vertex . By choosing an adjacency list as a way to store the graph in memory, this may save us space.
is also a list and contains all the vertices, adjacent to the current vertex . By choosing an adjacency list as a way to store the graph in memory, this may save us space.
For instance, in the Depth-First Search algorithm, there is no need to store the adjacency matrix. At each algorithm step, we need to know all the vertices adjacent to the current one. This what the adjacency lists can provide us easily. We may also use the adjacency matrix in this algorithm, but there is no need to do it. Instead, we are saving space by choosing the adjacency list.
This is the adjacency list of the graph above:
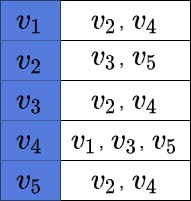
We may notice, that this graph representation contains only the information about the edges, which are present in the graph.
If  is the number of edges in a graph, then the time complexity of building such a list is
is the number of edges in a graph, then the time complexity of building such a list is  . The space complexity is
. The space complexity is  . But, in the worst case of a complete graph, which contains
. But, in the worst case of a complete graph, which contains  edges, the time and space complexities reduce to .
edges, the time and space complexities reduce to .
As it was mentioned, complete graphs are rarely meet. Thus, this representation is more efficient if space matters. Moreover, we may notice, that the amount of edges doesn’t play any role in the space complexity of the adjacency matrix, which is fixed. But, the fewer edges we have in our graph the less space it takes to build an adjacency list.
However, there is a major disadvantage of representing the graph with the adjacency list. The access time to check whether edge is present is constant in adjacency matrix, but is linear in adjacency list. In a complete graph with vertices, for every vertex the element of would contain  element, as every vertex is connected with every other vertex in such a graph.
element, as every vertex is connected with every other vertex in such a graph.
Therefore, the time complexity checking the presence of an edge in the adjacency list is  . Let’s assume that an algorithm often requires checking the presence of an arbitrary edge in a graph. Also, time matters to us. Here, using an adjacency list would be inefficient.
. Let’s assume that an algorithm often requires checking the presence of an arbitrary edge in a graph. Also, time matters to us. Here, using an adjacency list would be inefficient.
Let’s now see the worst-case complexity of removing a vertex and an edge.
Let’s suppose we want to remove  .
.
If we use the adjacency matrix, we’ll have to set all the entries in the  -th row and the -th column to zero. Doing so will delete all the edges incident to , effectively removing from the graph. In total, we’ll iterate over
-th row and the -th column to zero. Doing so will delete all the edges incident to , effectively removing from the graph. In total, we’ll iterate over  cells, so the time complexity will be .
cells, so the time complexity will be .
On the other hand, removing a vertex from an adjacency list will cost more. To remove all the outgoing edges, we set to NULL the pointer to the ‘s list,  . However, to delete all the occurrences of from other nodes’ lists, we have to iterate over all the other lists. In the worst case, each node will be connected to all the other vertices, so we’ll traverse
. However, to delete all the occurrences of from other nodes’ lists, we have to iterate over all the other lists. In the worst case, each node will be connected to all the other vertices, so we’ll traverse  list elements. Therefore, removing a vertex from the list representation of a graph is an operation.
list elements. Therefore, removing a vertex from the list representation of a graph is an operation.
To remove an edge  from an adjacency matrix
from an adjacency matrix  , we set
, we set ![M[i,j]](/wp-content/ql-cache/quicklatex.com-5bc505cefd9ed268c701ba4e8cf8b736_l3.svg "Rendered by QuickLaTeX.com") to zero. If the graph is symmetric, we do the same with
to zero. If the graph is symmetric, we do the same with ![M[j, i]](/wp-content/ql-cache/quicklatex.com-182c716f618abf8a316433b1a907570b_l3.svg "Rendered by QuickLaTeX.com") . Accessing a cell in the matrix is an operation, so the complexity is in the best-case, average-case, and worst-case scenarios.
. Accessing a cell in the matrix is an operation, so the complexity is in the best-case, average-case, and worst-case scenarios.
If we store the graph as an adjacency list, the complexity of deleting an edge is . That’s because, in the worst case, we traverse the whole list to remove  from it. If the graph is symmetric, we do the same with
from it. If the graph is symmetric, we do the same with  , removing from it. In total, we iterate over no more than elements, so the complexity is
, removing from it. In total, we iterate over no more than elements, so the complexity is  .
.
In this tutorial, we’ve discussed the two main methods of graph representation. We’ve learned about the time and space complexities of both methods. Moreover, we’ve shown the advantages and disadvantages of both methods.
The choice of the graph representation depends on the given graph and given problem. In some problems space matters, however, in others not. These assumptions help to choose the proper variant of graph representation for particular problems.