Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
File Structures
Last updated: May 30, 2023

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Overview
In this tutorial, we’re going to look at the basic file structures. Firstly, we’ll briefly explain basic concepts and then give information about the most common file structures.
2. Introduction
Although disks are slow, they provide enormous capacity at less cost than memory. They also keep the information stored on them even if they are turned off. The main driving force behind file structure design comes from a disk’s slow access time and its enormous, and nonvolatile capacity.
Before we’ll get into details, let’s look at the main difference between data structures and file structures. While data structures deal with data in main memory, file structures deal with data in secondary storage devices such as hard disks. Both involve representation of data and the operation of accessing data. That’s why these two concepts can be confused with each other in the literature. However, we can say that developments in memory access technologies directly affect the researchers working on the file structures.
3. File Structures
A file structure is a combination of representations for data in files. It is also a collection of operations for accessing the data. It enables applications to read, write, and modify data. File structures may also help to find the data that matches certain criteria. An improvement in file structure has a great role in making applications hundreds of times faster.
The main goal of developing file structures is to minimize the number of trips to the disk in order to get desired information. It ideally corresponds to getting what we need in one disk access or getting it with as little disk access as possible.
A good file structure should:
- Fast access to a great capacity
- Reduce the number of disk accesses
- Manage growth by splitting these collections.
It is relatively easy to develop file structure designs that meet these goals when the files never change. However, as files change, grow, or shrink, designing file structures that can have these qualities is more difficult.
3.1. A Short History of File Structures
Since most files were on tape in the 1950s, access was sequential, and the cost of access grew in direct proportion to the size of the file. As files grew and as storage devices such as disk drives became available, indexes were added to files. These indexes allowed to keep a list of keys and pointers in a smaller file that could be searched more quickly. However, these indexes had some of the same sequential behavior and they became difficult to manage.
In the early 1960s, the idea of applying tree structures emerged. Since trees can grow very unevenly as users add and delete records, this results in long searches.
3.2. AVL Trees
Researchers continued to develop the tree structures and came up with an elegant, self-balancing binary search tree, called AVL tree, for data in memory. Researchers working on the file systems began to work look for ways to apply AVL trees to files.
3.3. B-Trees and B+ Trees
After ten years of design work, they came up with the idea of the B-tree. While B-tree provided excellent performance, it has one drawback: it couldn’t access a file sequentially with efficiency. Fortunately, they got rid of this issue by using a linked list structure. And they called this new structure B+ tree.
Let’s look at the figures below to see the main difference between B-tree and B+ tree:
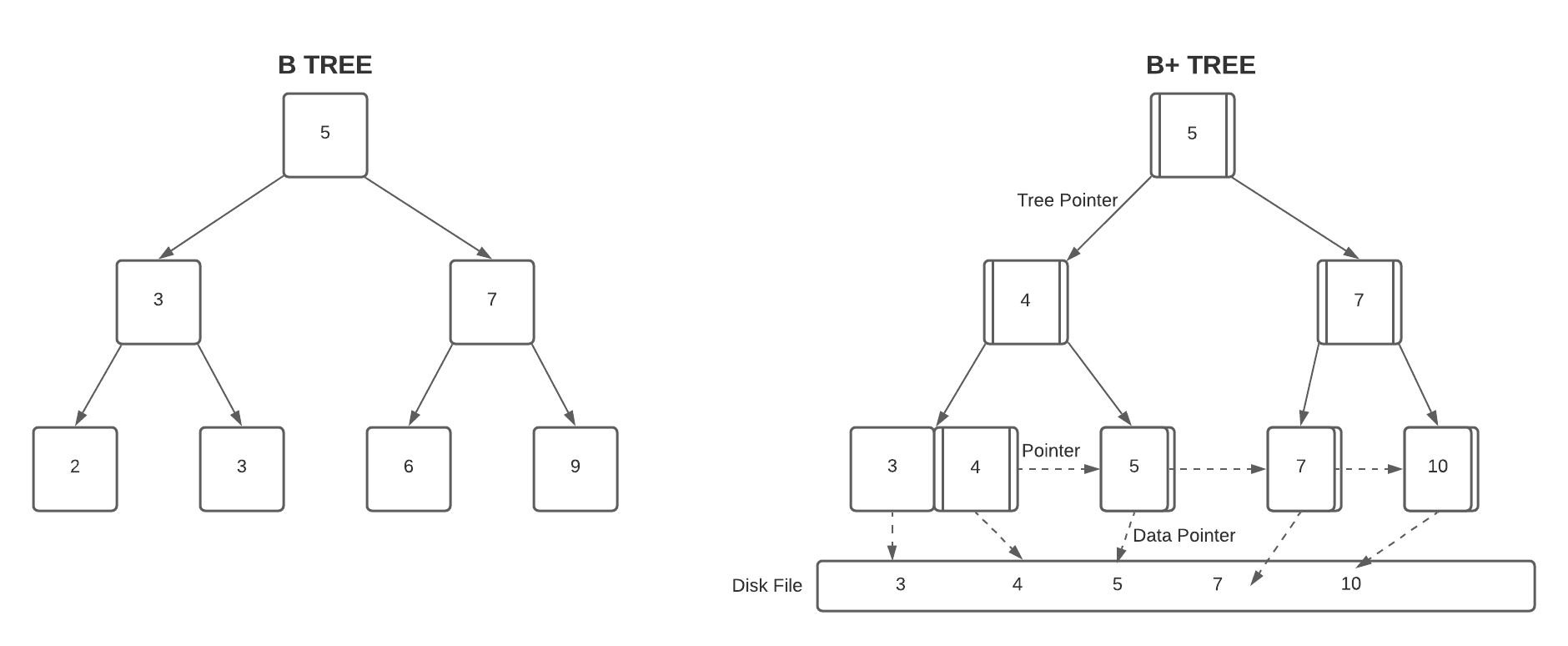
Over the years, B-Trees and B+ trees became a standard for many file systems, since they guarantee access time that grows in proportion to  , where
, where  is the number of entries in the file and
is the number of entries in the file and  is the number of entries indexed in a single block of the B-tree structure. In practice, we can find one file among millions of others with only three or four trips to the disk.
is the number of entries indexed in a single block of the B-tree structure. In practice, we can find one file among millions of others with only three or four trips to the disk.
3.4. Hashing
Accessing the data with only three or four trips to the disk is really efficient. However, there can be more efficient to get what we want with a single request right. Hashing is a way to access the data with one request. When files do not change size over time, hashing works well. But in the opposite situation, hashing doesn’t work well with dynamic files. Researchers solve this issue with the use of dynamic hashing that can retrieve information with one access no matter how big the file.
Let’s look at how hashing mechanism works:
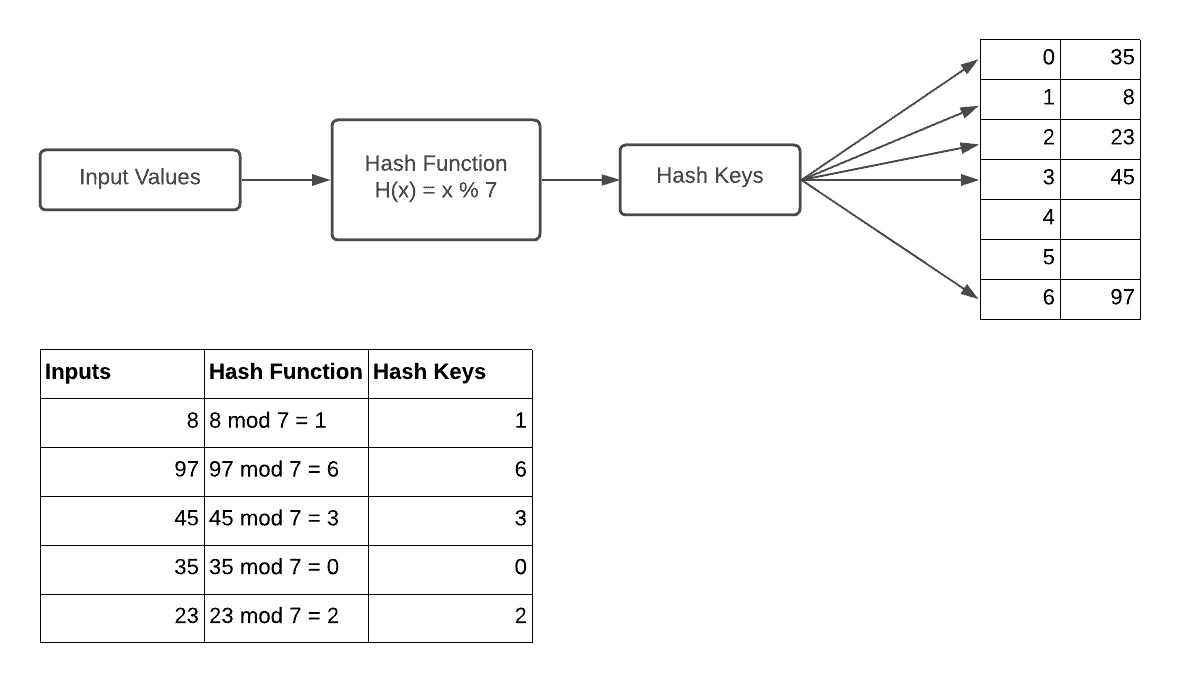
As we’ve seen figure above, hashing is a process that converts any input into a fixed size using an algorithm. The main idea of hashing is to use a hashing function that transforms a given input into a smaller number. It uses this smaller number as an index in a table called a hash table.
4. Conclusion
In this article, we’ve shared brief information about file structures and cleared the ambiguity between the data structures and file structures.
Also, we’ve shortly given information about common file structures such as AVL trees, B and B+ trees, and, hashing.