Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Introduction to the Domain Name System (DNS)
Last updated: March 18, 2024

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
Reliable communication between globally located network devices using IP address namespace is the foundation stone of the Internet. However, it’s more natural for humans to remember stuff by short names than numbers.
Domain Name System (DNS) solves this issue by helping us access the Internet addresses by names such as google.com, instead of an IP address. Through this tutorial, we’ll develop a better understanding of the core concepts and working principles of DNS.
2. DNS Basics
Let’s start with the basics of DNS.
2.1. Lookup Functionality
To be able to access websites on the Internet, the Internet browser needs a lookup system to find IP addresses of the web servers.
First, the browser would send a lookup request for the website’s IP address. In the second step, the lookup system would respond with an answer containing the IP address of the domain. Finally, in the third step, the browser would be able to connect to the website using the IP address:
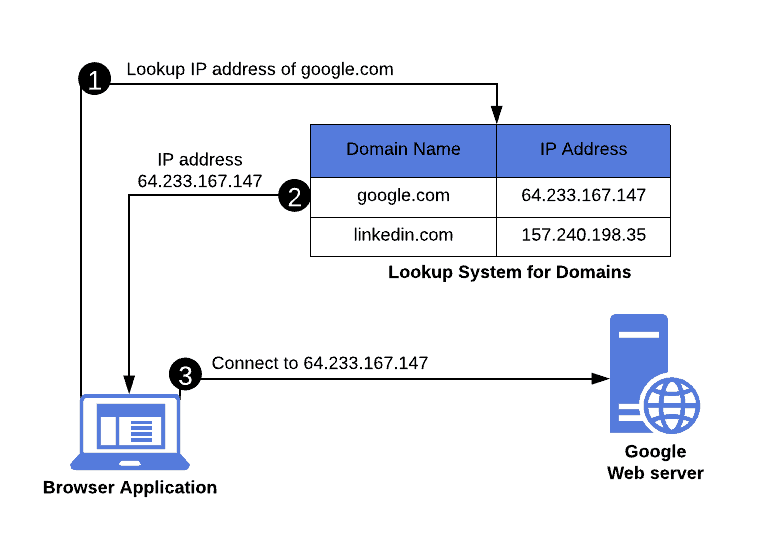
Such a lookup system must be able to store records corresponding to billions of active websites on the Internet. However, it’s not possible for every device on the Internet to store such a massive set of mappings locally.
Moreover, such lookups are critical for the Internet to function efficiently. So, for all the users to access the Internet reliably, DNS is designed as a distributed database system.
2.2. Distributed System
To be highly reliable, we’d want DNS to be highly available, consistent, and tolerant to failures in a network partition. However, as the CAP theorem says, we can’t have all of them at the same time.
So, when a partial network failure occurs, DNS needs to compromise either availability or consistency. Naturally, for the Internet to function all the time, it’s designed to be a highly available system:
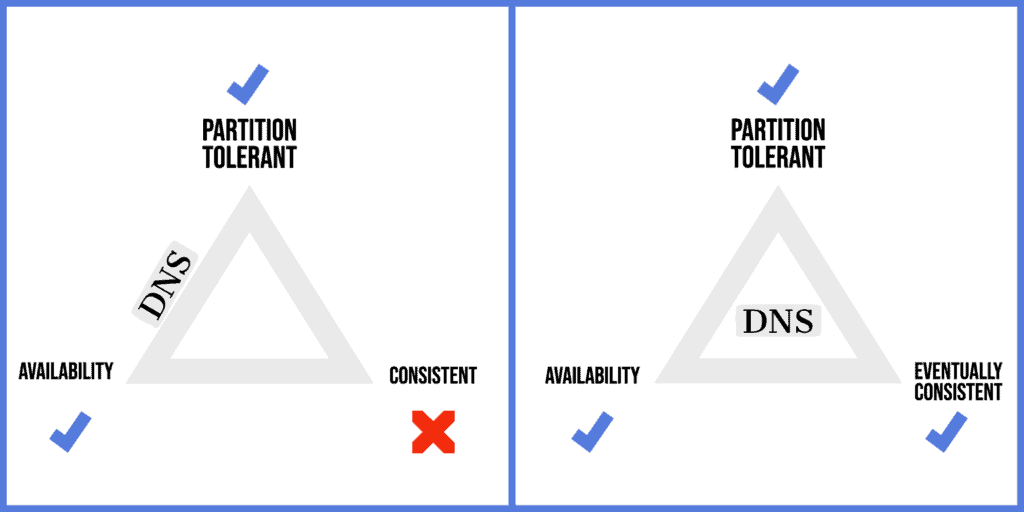
It’s important to note that although DNS prefers availability over consistency, it is an eventually consistent system. So, with time, inconsistency, if any, would go away.
While continuing to explore further, let’s keep these design decisions in mind. That will help us develop a better understanding of all the associated concepts.
3. Domain Namespace
Domain namespace keeps the domains organized such that they’re easy to access. Moreover, the structure of domain namespace influences the internal structure and specific functionality of each component in DNS. So, let’s go ahead and understand this concept now.
3.1. Hierarchical Structure
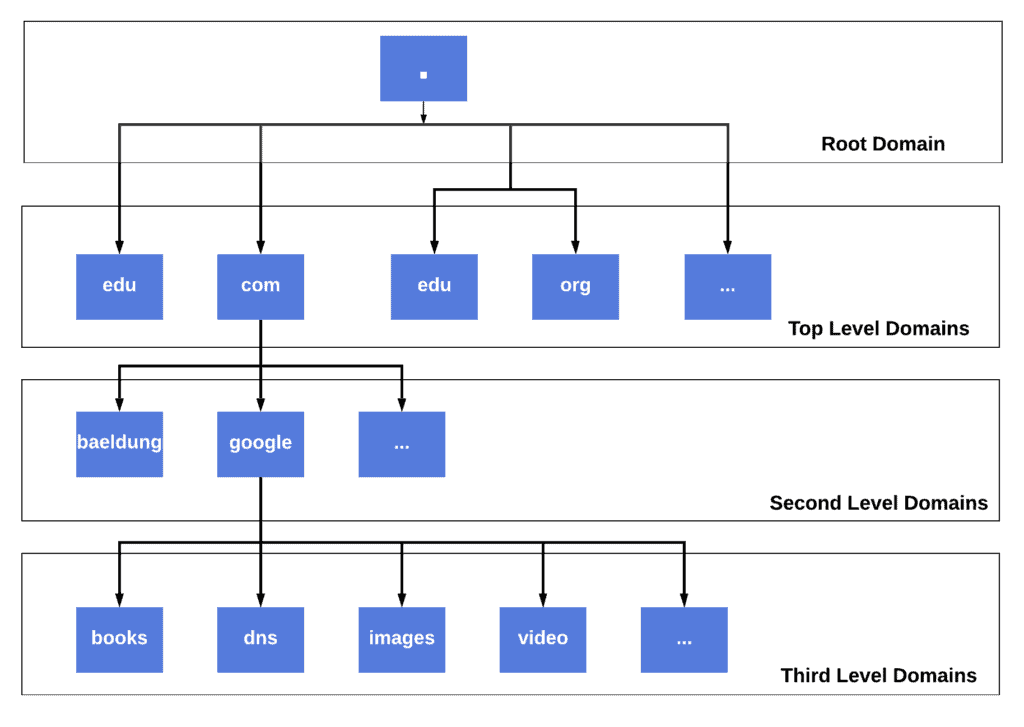
To design DNS as a distributed system that can store billions of domain records, we’d need to find a logical way to distribute the entire domain namespace across multiple nodes. So, instead of having an unordered collection, Internet domain namespace is perceived as a hierarchical tree-like structure where each node is effectively a domain name.
Here, the idea is that a group of domains that share some characteristic, such as affiliation or purpose would belong to the same family:
When we parse domain namespace from top to bottom, the ones sitting at the first level are called the Top Level Domains (TLDs). Broadly speaking, there are two types of TLDs:
- Generic Top-Level Domain (gTLDs) such as com (commercial), edu (educational), and org (non-profits)
- Country Code Top Level Domain (ccTLDs) such as us, uk, and in
Next, directly under a TLD, are the Second-Level Domains that usually indicate the organization to which that domain belongs. Likewise, directly under a Second-Level Domain are the Third-Level Domains that help to further organize internet addresses that belong to the same organization.
As such, except for the root domain, all other domains are also known as subdomains of the parent domain. However, when the context is limited to a particular organization, then third-level domains are, in short, referred to as subdomains.
3.2. Fully Qualified Domain Name (FQDN)
From any node within the domain namespace, if we traverse up till the root node, then we get its absolute path:
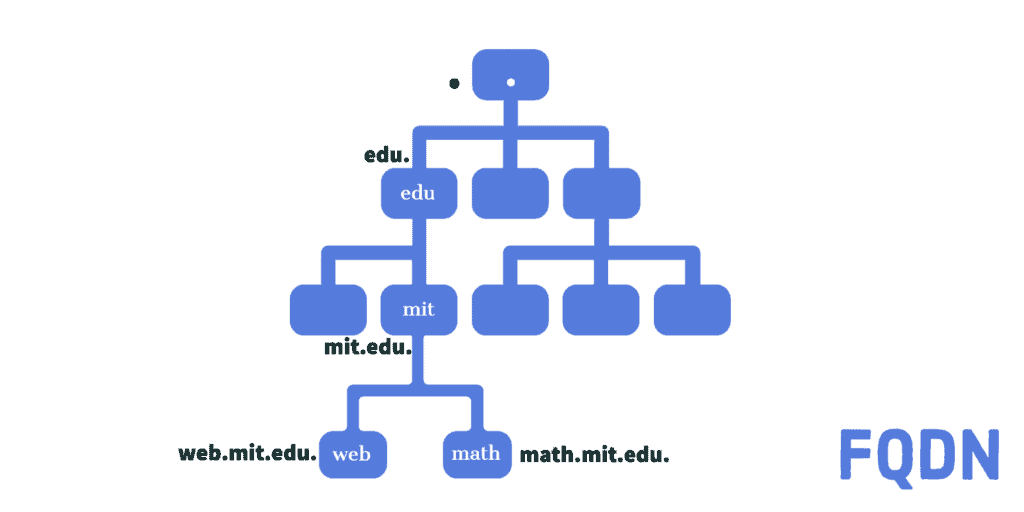
Unlike the concept of subdomains, which is relative to the parent domain, the absolute path is unambiguous. So, when we write down this path separated by a dot, we get its Fully Qualified Domain Name (FQDN) that can be used by DNS internally.
When it comes to naming conventions for a valid domain, there are a few guidelines:
- We can only use numbers (0-9), letters (a-z, A-Z), or hyphens (–)
- We can’t start a domain name with a hyphen
- FQDN can’t be longer than 255 characters, with each individual part not exceeding 63 characters
With these restrictions in place, it gets easier to parse an FQDN and extract the individual strings such as TLD, or the principle domain.
3.3. Zones
Looking at domain namespace tree, we can think of any non-leaf node to represent a family of domain addresses that have the same right side in their FQDNs. On top of that, a zone is a group of domain addresses within domain namespace that is administered by the same Domain Name Server.
Let’s imagine that the information related to google.com, docs.google.com, and sheets.google.com is maintained by a single DNS server, while dns.google.com is administered by a different DNS server:
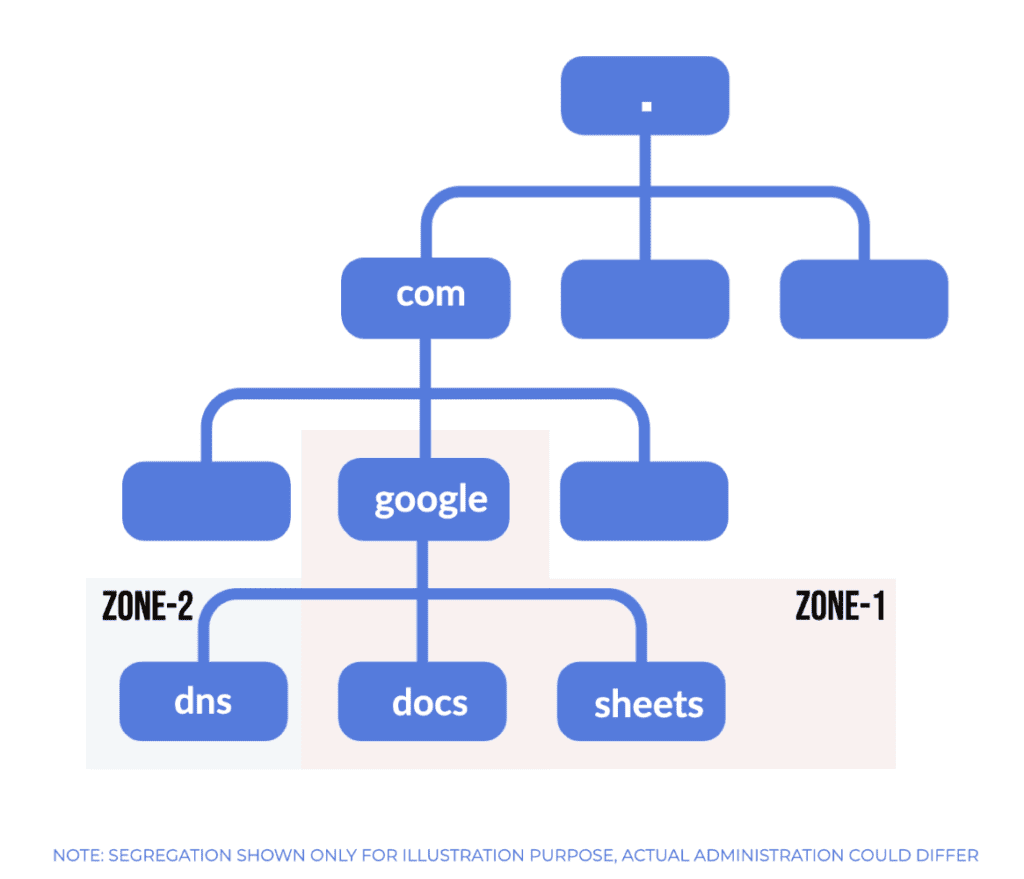
So, we can see two DNS zones here, namely ZONE-1 and ZONE-2. Among these, ZONE-2 is scoped to a subdomain (dns.google.com) of the domain, google.com, and such zones are popularly known as subordinate zones.
4. DNS Client-Server Architecture
At a high level of abstraction, DNS is built upon a client-server architecture model:
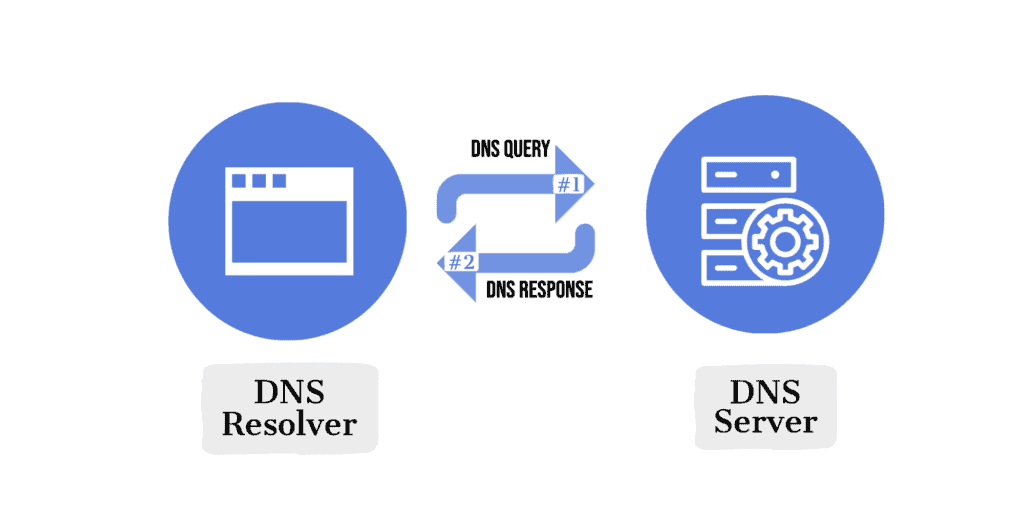
As happens in a client-server model, a domain name resolution request is initiated by a DNS client, which is popularly known as DNS resolver. In return, the distributed network of DNS responds to the client.
However, as DNS is essentially a hierarchical distributed system, the exact flow is not as simple as it looks here.
One thing that’s important to understand is that as the data is spread across several servers, the first server that gets the query might not be able to answer the query by itself. So, it might seek answers from another DNS server, and while doing that, it takes the role of a DNS resolver.
5. Name Servers (NS)
Name Servers are the core functional components of DNS as they store the relevant information needed for translation of domain names to IP addresses and vice versa. Besides, depending on the type of information they store, they can be classified into different types. Let’s learn more about them.
5.1. Authoritative Name Servers
From an administrative point of view, an authoritative name server is configured by an administrator to hold the authoritative source of data for a zone. So, to answer DNS queries for domains in that zone, all other name servers would need to directly or indirectly consult this name server at some point in time.
Like Domain Namespace, authoritative name servers follow a hierarchical order, with authoritative name servers for the root zone sitting at the top of the tree. Generally speaking, the term zone is often dropped, so DNS servers for the root zone are often called root servers, DNS servers for a TLD zone are TLD servers, and so on.
5.2. Caching Name Servers
Although the domain information is mutable, nevertheless, in most cases, a lot of this information, such as IP address, doesn’t change for a considerable time. So, caching is a convenient choice that can help in reducing the number of DNS queries coming to an authoritative name server.
On the one hand, caching improves the performance of DNS, and most internet-facing applications benefit from this. While, on the other hand, it also introduces a possibility of inconsistency in the system wherein an authoritative name server changed some information. However, the caching name servers are still answering using the cached results.
To some extent, the problem of inconsistency is solved by a mechanism of expiring the cached results based on a TTL (time to live) value configured for that record by the authoritative name server. As a result, DNS is not a strongly consistent system, but it still provides eventual consistency.
6. DNS Resolutions
So far, so good! Now, we have a fair understanding of the core components of a DNS system. So, as a next step, let’s see how these components collaborate to answer the DNS queries.
6.1. Recursive and Non-recursive Query
To answer translation queries, DNS leverages the hierarchical organization of the domain namespace and the authoritative name servers.
While making a DNS query, the client has the flexibility of choosing between a recursive or non-recursive query. For the former, it expects the server to give it a definite answer for the query. However, for the latter, it expects either a definite answer or a referral nameserver that might hold the answer:
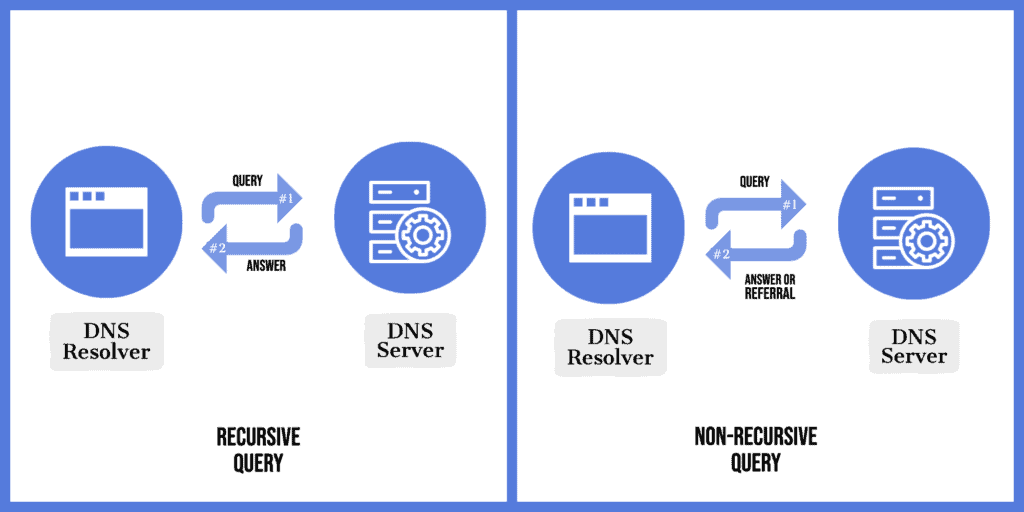
To serve a request, DNS resolver parses the FQDN from the right to left and isolates its individual parts. Then, it’d invoke several non-recursive queries starting with the root server. In response, either it’d have an answer or a referral nameserver that it should query next.
Finally, the last response goes back to the client. In this entire chain of events, we must note that usually, resolvers have hard-coded addresses for the root servers, and this helps them to reach the root node of the server tree. After that, referrals serve the purpose of tree traversal.
6.2. Forwarder and Recursor
While DNS resolvers can decide whether they want to initiate a recursive or a non-recursive query, there’s similar flexibility with DNS servers:
- Forwarder server can forward a DNS query to another DNS server
- Recursor server would resolve a DNS query all by itself
We must note that resolution for any DNS query would begin with one or more DNS Forwarders and end at a DNS Recursor.
Naturally, serving recursive queries involves more work by a server than serving non-recursive queries. So, if we have to set up a recursive server, then we must take this into account. However, for most general purposes, we can use public DNS resolvers offered by Internet giants such as Google or Cloudflare.
7. DNS Resource Records
So far, we restricted our discussion to the translation of domain names to IP addresses. However, DNS is capable of storing several other kinds of resource records for the Internet domains:
- A record maps to the IPv4 address
- AAAA record maps to the IPv6 address
- CNAME record works as an alias and maps to the canonical domain name
- MX record maps to the mail server that can send or receive emails on behalf of a domain
- NS record maps to the authoritative name server for a zone
We must note that these are just the most commonly used records. For that matter, if we take the use case of microservice-based distributed systems, then SRV records play a crucial role in service discovery as they can map an IP address and a port to a service name.
8. Conclusion
In this tutorial, we learned about a variety of topics such as domain namespace, name servers, and the architecture behind DNS. We dived into each topic, to understand the process of DNS query resolution clearly.