Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: November 4, 2022

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
This tutorial introduces the Direct Linear Transform (DLT), a general approach designed to solve systems of equations of the type:
![\[\lambda\mathbf{x}_k=\mathbf{A} \mathbf{y}_k \text { for } k=1, \ldots, N\]](/wp-content/ql-cache/quicklatex.com-228e93efaf9146dc084054c70f0a5a95_l3.svg "Rendered by QuickLaTeX.com")
This type of equation frequently appears in projective geometry. One very important example is the relation between 3D points in a scene and their projection onto the image plane of a camera. That is why we’re going to use this setting to motivate the usage of DLT.
The most commonly used mathematical model of a camera is the so-called pinhole camera model. Since the idea of a camera is to map between real-world objects and 2d representations the camera model consists of several coordinate systems:
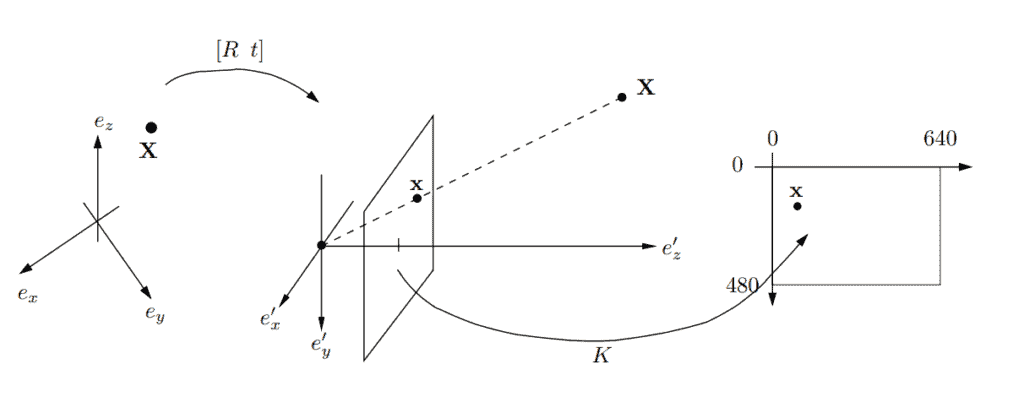
To encode camera position and movement we use the reference coordinate system  (left part of the diagram). In this system, the camera can undergo translation and rotation. The translation is represented as a vector
(left part of the diagram). In this system, the camera can undergo translation and rotation. The translation is represented as a vector  and the rotation is represented as a
and the rotation is represented as a  rotation matrix
rotation matrix  .
.
Usually, all the scene point coordinates are also specified in the global coordinate system and and  are used to relate them to the camera coordinate system as so:
are used to relate them to the camera coordinate system as so:
![\[\left(\begin{array}{l}X_1^{\prime} \\ X_2^{\prime} \\ X_3^{\prime}\end{array}\right)=R\left(\begin{array}{c}X_1 \\ X_2 \\ X_3\end{array}\right)+t .\]](/wp-content/ql-cache/quicklatex.com-43f9928412816950f3d35953c8b935d0_l3.svg "Rendered by QuickLaTeX.com")
Which can be neatly represented in matrix form if we add 1 as an extra dimension.
![\[\left(\begin{array}{l}X_1^{\prime} \\ X_2^{\prime} \\ X_3^{\prime}\end{array}\right)=\left[\begin{array}{ll}R & t\end{array}\right]\left(\begin{array}{c}X_1 \\ X_2 \\ X_3 \\ 1\end{array}\right)\]](/wp-content/ql-cache/quicklatex.com-bae1afef85bc38d069ab97249caf9637_l3.svg "Rendered by QuickLaTeX.com")
The camera coordinate system  (in the middle of the diagram) has an origin
(in the middle of the diagram) has an origin  which represents the camera center, or pinhole. To generate a projection
which represents the camera center, or pinhole. To generate a projection  of a scene point
of a scene point  we form the line between
we form the line between  and
and  and intersect it with the plane
and intersect it with the plane  .
.
This plane is also called the image plane and the line intersecting it is the viewing ray. One might note that unlike a physical camera the projection plane is in front of the pinhole. This is done for convenience and has the effect that the image will not appear upside down as in the real model.
In the pinhole camera model, the image plane lies in  , meaning that the projections are given in the length of real-world units. But when we are talking about images, we use pixels in a specified dimension. In our example diagram, we ‘re using
, meaning that the projections are given in the length of real-world units. But when we are talking about images, we use pixels in a specified dimension. In our example diagram, we ‘re using  pixels. To convert it we use a mapping (right side of the diagram) from the image plane embedded in to the real image.
pixels. To convert it we use a mapping (right side of the diagram) from the image plane embedded in to the real image.
This pixel mapping is represented by an invertible triangular  matrix
matrix  which contains the inner parameters of the camera, that is, focal length, principal point, aspect ratio, and axis skew.
which contains the inner parameters of the camera, that is, focal length, principal point, aspect ratio, and axis skew.
And finally, we can relate all three parts of the camera model into one equation:
![\[\lambda\left(\begin{array}{l}x_1 \\ x_2 \\ 1\end{array}\right)=K\left [\begin{array}{ll}R & t\end{array}\right]\left(\begin{array}{c}X_1 \\ X_2 \\ X_3 \\ 1\end{array}\right)\]](/wp-content/ql-cache/quicklatex.com-38835700a08abfea3e25e6a16386be32_l3.svg "Rendered by QuickLaTeX.com")
or more succinctly:
![\[\lambda x = PX\]](/wp-content/ql-cache/quicklatex.com-ef88d2a3b7675e18917da081de67081f_l3.svg "Rendered by QuickLaTeX.com")
where P is called the camera matrix.
The above equation now looks like the exact type that DLT can help us find the matrix P if we wanted to.
But why do we need to solve it in the first place? Most of the time we’re interested in finding the  part of the camera matrix
part of the camera matrix  . Because if is known we can see that the camera is calibrated. And with a calibrated camera we can do things like lens distortion correction, measuring an object from a photo, or even estimating 3d coordinates from camera motion.
. Because if is known we can see that the camera is calibrated. And with a calibrated camera we can do things like lens distortion correction, measuring an object from a photo, or even estimating 3d coordinates from camera motion.
To do that we’ll first need at least 6 data points measured by hand, we can then compute the camera matrix P using the DLT method and finally factorize into ![K\left [\begin{array}{ll}R & t\end{array}\right]}](/wp-content/ql-cache/quicklatex.com-4c51ceaf47b0aeea25aa8c7fbe6aa276_l3.svg "Rendered by QuickLaTeX.com") using RQ-factorization.
using RQ-factorization.
The first step of the DLT method formulates a homogeneous linear system of equations and solves it by finding an approximate null space. To do that we first express P in terms of row vectors:
![\[P = \begin{bmatrix} p_1^T \\p_2^T\\p_3^T\end{bmatrix}\]](/wp-content/ql-cache/quicklatex.com-7e801df37616cf6cdfdf9e629bfc8f2e_l3.svg "Rendered by QuickLaTeX.com")
Then we can write the camera equation as:
![\[\mathbf{X}_i^T p_1-\lambda_i x_i=0\]](/wp-content/ql-cache/quicklatex.com-181c7fbcd7509504bff562bcdfba66f4_l3.svg "Rendered by QuickLaTeX.com")
![\[\mathbf{X}_i^T p_2-\lambda_i y_i=0\]](/wp-content/ql-cache/quicklatex.com-c38bec5f45e99378a1813ca500d7a531_l3.svg "Rendered by QuickLaTeX.com")
![\[\mathbf{X}_i^T p_3-\lambda_i=0\]](/wp-content/ql-cache/quicklatex.com-e08e2990edd6fee5c707ec5981c40535_l3.svg "Rendered by QuickLaTeX.com")
which in turn can be put into matrix form as such:
![\[\left[\begin{array}{cccc}\mathbf{X}_i^T & 0 & 0 & -x_i \\ 0 & \mathbf{X}_i^T & 0 & -y_i \\ 0 & 0 & \mathbf{X}_i^T & -1\end{array}\right]\left(\begin{array}{l}p_1 \\ p_2 \\ p_3 \\ \lambda_i\end{array}\right)=\left(\begin{array}{l}0 \\ 0 \\ 0\end{array}\right)\]](/wp-content/ql-cache/quicklatex.com-68d3f202bb7632d324435dbd2886989e_l3.svg "Rendered by QuickLaTeX.com")
Note that since  is a
is a  vector each
vector each  actually represents a
actually represents a  block of zeros, meaning we are multiplying a
block of zeros, meaning we are multiplying a  matrix multiplied with a
matrix multiplied with a  vector.
vector.
If we stack all the projection equations of all the measured data points in one matrix, we get a system of the form:
![\[\begin{bmatrix} \mathbf{X}_1^T & 0 & 0 & -x_1 & 0 & 0 & \cdots\\ 0 & \mathbf{X}_1^T & 0 & -y_1 & 0 & 0 & \cdots\\ 0 & 0 & \mathbf{X}_1^T & -1& 0 & 0 & \cdots\\ \mathbf{X}_2^T & 0 & 0 & 0 & -x_2 & 0 & \cdots\\ 0 & \mathbf{X}_2^T & 0 & 0 & -y_2 & 0 & \cdots\\ 0 & 0 & \mathbf{X}_2^T & 0& -1 & 0 & \cdots\\ \mathbf{X}_3^T & 0 & 0 & 0 & 0 & -x_3 & \cdots\\ 0 & \mathbf{X}_3^T & 0 & 0 & 0 & -y_3 & \cdots\\ 0 & 0 & \mathbf{X}_3^T & 0 & 0 & -1 & \cdots\\ \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \ddots \end{bmatrix} \left(\begin{array}{l}p_1 \\ p_2 \\ p_3 \\ \lambda_1\\\lambda_2\\\lambda_3\\\vdots\end{array}\right) = \left(\begin{array}{l}0 \\ 0 \\ 0 \\ 0 \\0 \\ 0 \\0 \\ 0 \\0 \\ \vdots\end{array}\right)\]](/wp-content/ql-cache/quicklatex.com-56cfae66fb80abefe40be3e05caab2ee_l3.svg "Rendered by QuickLaTeX.com")
![\[\bigbreak\]](/wp-content/ql-cache/quicklatex.com-72541e0cad1eb447ffb3f54f2d247220_l3.svg "Rendered by QuickLaTeX.com")
![\[Mv=0\]](/wp-content/ql-cache/quicklatex.com-843d16d4812405027e71968480d41a36_l3.svg "Rendered by QuickLaTeX.com")
After rearranging the equations, we just need to find a non-zero vector in the null space of  to solve the system. In most cases, however, there will not be an exact solution due to noise while measuring. Therefore, it is more convenient to search for a solution that minimizes the total error essentially solving a least square problem instead.
to solve the system. In most cases, however, there will not be an exact solution due to noise while measuring. Therefore, it is more convenient to search for a solution that minimizes the total error essentially solving a least square problem instead.
One way of solving it is to use Singular Value Decomposition (or SVD). After decomposing the big matrix we can take the right singular vector corresponding to the smallest singular value and we have found the camera matrix . We can then factorize into using the QR-factorization method, as mentioned before.
In this article, we looked into the pinhole camera model and motivated the usage of the Discrete Linear transformation (DLT) by trying to find the intrinsic parameters of a given camera model. Using this setting as an example we looked into the methodology behind the approach and how it works.