

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this tutorial, we’ll learn about data pipelines – such systems enable data delivery from one data source to a destination.
Most modern applications handle transactions of data that are continuously recorded into their system. However, there’s a need to streamline the data transportation process for further insights and analysis. For example, businesses need a reliable implementation that transports large volumes of data for business intelligence or other use cases.
We’ll cover all components that comprise a data pipeline architecture, as well as some common processing mechanisms. Finally, we’ll mention real-world use cases commonly known in the industry.
2. Data Pipelines
A data pipeline refers to a process in which data has an origin or source, and it’s transferred to a destination where it can be interpreted differently. It’s also called a system that transfers data from a source to a target system. Nonetheless, a data pipeline processes data with the purpose of transforming it into meaningful information and storing it for further insights.
Companies and organizations handle large datasets for business intelligence purposes. They ingest or generate data to drive revenue, analyze customers, or identify patterns. However, one of many complexities of managing big data is dealing with raw, unstructured information. In other words, making sense of large volumes of data is hard, especially when the data is not filtered or formatted for a specific analysis. Data pipelines, however, provide the end-to-end process from consuming raw data, preparing it for analysis, to loading it into a specialized data storage.
Overall, most systems are designed to understand a specific data format. Yet, the origin of this data is not necessarily structured according to the systems capable of running business analysis. Therefore, we implement data pipelines to assist with delivering analysis-ready data to the appropriate destinations:
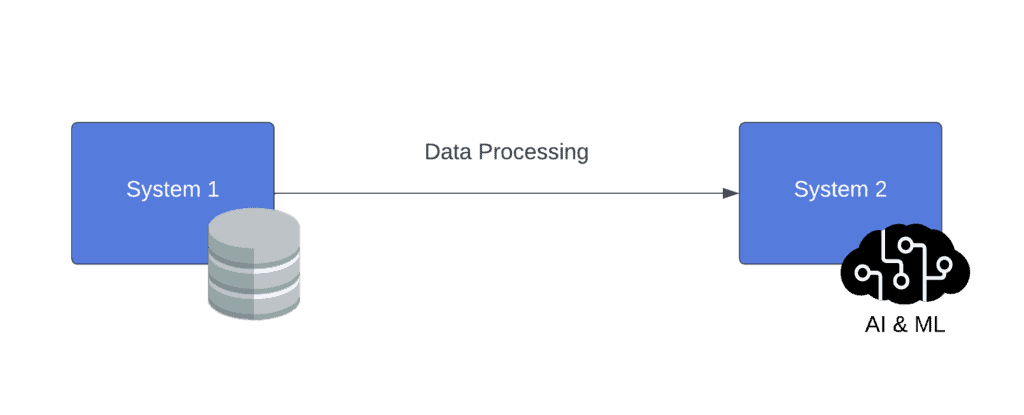
Next, we’ll define the components of a data pipeline and explain their purposes in the process.
3. Origin
The origin is the source component of a data pipeline. That is, a data storage system such as a database or another application producing real-time data. This component could serve other applications with the necessary information and be incorporated into our pipeline. However, devices or other applications may generate tabular data or streaming data that may need to be aggregated before telling a meaningful story.
Typically, the origin component is any device, storage, or service that provides data upon request or streams it. For example, an API endpoint with the only purpose of serving data or an SQL database storing records are both origin components. Moreover, the origin determines the next layer of the pipeline. For instance, an IoT pipeline having a sensor publishing data points to an MQTT message broker will need a subscriber service to handle the stream of data. On the other hand, a data digestion layer can extract data periodically from a relational database with less complexity.
A data pipeline can comprise multiple data sources. In that case, the goal is to consolidate the data from disparate sources into a central hub. Not surprisingly, the origin component may not be as different as the destination. For example, data lakes and data warehouses are database systems that can be used on both ends of the pipeline.
4. Destination
Data pipelines take data to a final component, which is the destination or target system. The purpose of the destination is to present the data in the correct scheme for other tools to consume. In the same way, that data pipelines have a destination, data also have a final state in which different applications expect this information to be. Therefore, a data storage system makes up for a good target system where to hold this data. Interestingly, the target system may well be another database, just like the origin.
The target system expects the data to be in the correct schema and ready for analysis. Because this component is the last endpoint in the pipeline, it’s highly dependent on the use case. For example, combining and refining data and then preserving it in a relational system of records would make a data warehouse a suitable destination for this case. Alternatively, services hosting machine learning models, business intelligence platforms and data visualization tools are important applications to feed data into.
The destination of a data pipeline holds the final state of the data after going through every component in the process. Data might have been adjusted, filtered and aggregated. Nonetheless, the target system, such as a reporting platform, represents the business use case for which the data pipeline was built initially.
5. Processing
When transporting data from the source to a target system, data pipelines process the data before delivering it. This step allows the destination to receive the data in the expected format. Moreover, there are multiple implementations of how to perform the processing of data:
5.1. ETL
ETL is a common pipeline architecture that stands for extract, transform, and load. Each layer or component in the pipeline is in charge of performing a specific operation on the data. As its name implies, the sequence of operations is to extract the data first, transform it into a desired format, and load it to a storage system:
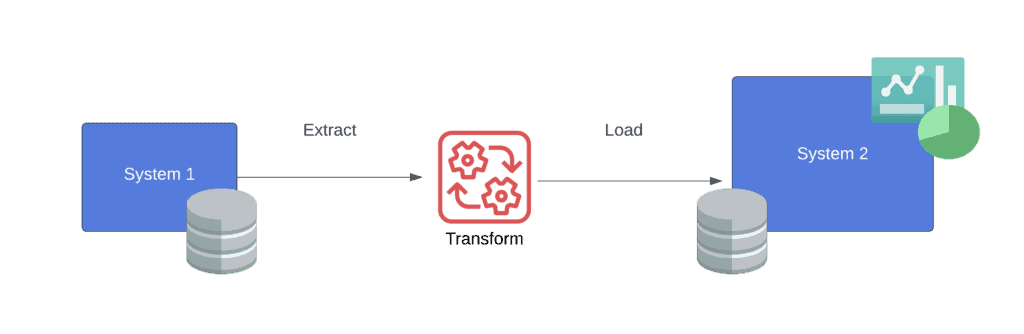
This architecture is popular for data migrations as well as joining data from multiple sources. Besides, it’s associated with structured and relational data, hence storing information in a data warehouse. For this reason, a more modern approach, ELT, was invented to deal with data more flexibly.
5.2. ELT
ELT stands for extract, load, and transform, and it has become a common approach for organizations to streamline their data processes. Mainly for two reasons: First, large organizations are migrating their workflows to the cloud, along with the need to store large volumes of data in multiple formats. Second, the need to process data rapidly for business insights has grown immensely, resulting in seeking more effective data integration processes:
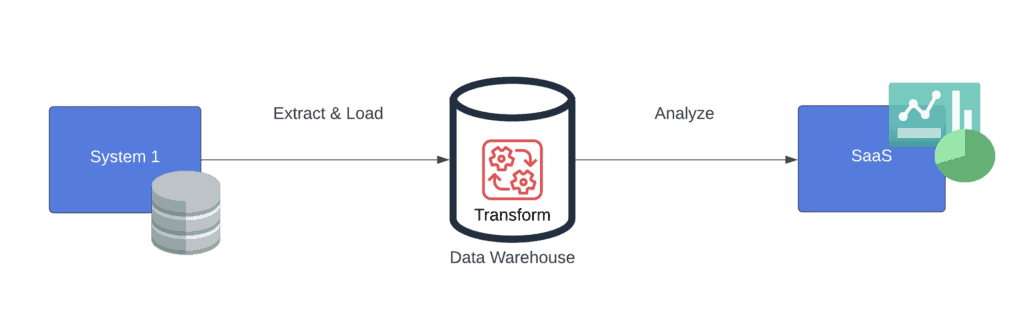
With an ELT approach, the transformation occurs at the data store. This means that ELT leverages the technological advancements of cloud storage systems. These storage services were designed to handle large volumes of data with better processing power and efficient queries on Big Data.
5.3. Batch Processing
A batch processing pipeline consumes a fixed set of data on a scheduled basis and loads it into a data store. In other words, these pipelines run batch jobs periodically to move data blocks. Therefore, we implement batch processing pipelines for workflows that are not time-sensitive, possibly joining multiple data sources:

Furthermore, batch pipelines run in the background without any commitment to generate a response. We refer to this as offline systems. In other words, they simply collect data at specific intervals and generate an output without user engagement. We measure the performance of a batch job by calculating the throughput – the time it takes to process an input dataset.
5.4. Real-Time (Streaming) Processing
Real-time systems take in streams – unbounded data delivered over time – and process them as they happen. Data streams can take various forms, including, but not limited to, messages, audio, video, and network traffic. Today, many software systems deal with this data to produce an output with the lowest possible latency:

Unlike batch jobs, components in a streaming pipeline are notified of data events instead of polling data from a datastore, allowing systems to respond quickly if necessary. In response to every event, metrics and real-time analytics can be aggregated for business insights. Also, live events or media files are common use cases for streaming data.
6. Use Cases
6.1. Real-Time Processing Pipelines at Hewlett Packard Enterprise
Hewlett Packard Enterprise has more than 20 billion sensors all over the world to manage data center infrastructure for its customers. Their InfoSight product is a PaaS providing almost real-time analytics and performance. For this, Hewlett Packard Enterprise built a robust architecture to leverage a stream processing pipeline that moves petabytes of data, keeps the system available, and has low latency despite the large volumes of data and transformation they perform.
6.2. ETL Pipelines at iHeartRadio
iHeartRadio is a global streaming service for music, podcasts, and radio. Despite being a streaming service, the company also runs data flows internally, moving data from source to destination – a typical ETL approach. Nonetheless, not all dataflows fit the ETL paradigm; some combine the ETL process along with ELT. They created a hybrid version they named ETLT, which runs transformations on top of already processed data. With this example, iHeartRadio shows how companies adjust their data transportation according to their needs.
7. Conclusion
In this article, we learned about Data Pipelines – a technique to transport data from a source to a destination. We covered the most fundamental architecture, which includes three components: a source, a processing component, and a destination. Further, we explained how the implementation can vary according to the data type and use case.
We learned how data pipelines serve as a means to transform data into an analysis-ready state for business insights. Additionally, we mentioned two real-world examples of large companies leveraging data pipelines to enhance the workflows involving large volumes of data.