

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll learn about the different ways to implement write operations in a cache. We’ll consider the benefits of each method and discuss the criteria to evaluate.
But before we do that, let’s refresh some basics about caching.
In general, a cache is a facade component to provide convenient access to some storage. Typically, cache storage is faster and more expensive, thus available in lesser quantities. In some cases, cache storage may be owned by the system we design – unlike source storage.
The purpose of the cache is to improve both latency (time interval to perform a single operation) and throughput (operation processing rates). We can have cache both at the hardware (e.g. CPU cache) and software (e.g. page cache using RAM to cache data from secondary storage, such as SSD) levels.
A cache hit occurs if the requested data is located in cache storage. Otherwise, a cache miss happens.
Eviction is when we remove data from the cache. That could be because the data is unused, bulky, or we simply deem it inefficient to keep storing it. Eviction may happen both for expired and unexpired data.
This is different from invalidation, which refers to the process whereby we declare entries in the cache as invalid, either via direct removal from cache or providing the means to refresh the data from the backing store once requested.
A cache’s write policy is the behavior of a cache while performing a write operation. A cache’s write policy plays a central part in all the variety of different characteristics exposed by the cache. Let’s now take a look at three policies:
Suppose we design our cache to ensure consistency first. That is, we’d want to update our backing store synchronously before sending the response back to the client.
In case the requested entry is not found in the cache, we create an entry in cache storage first:
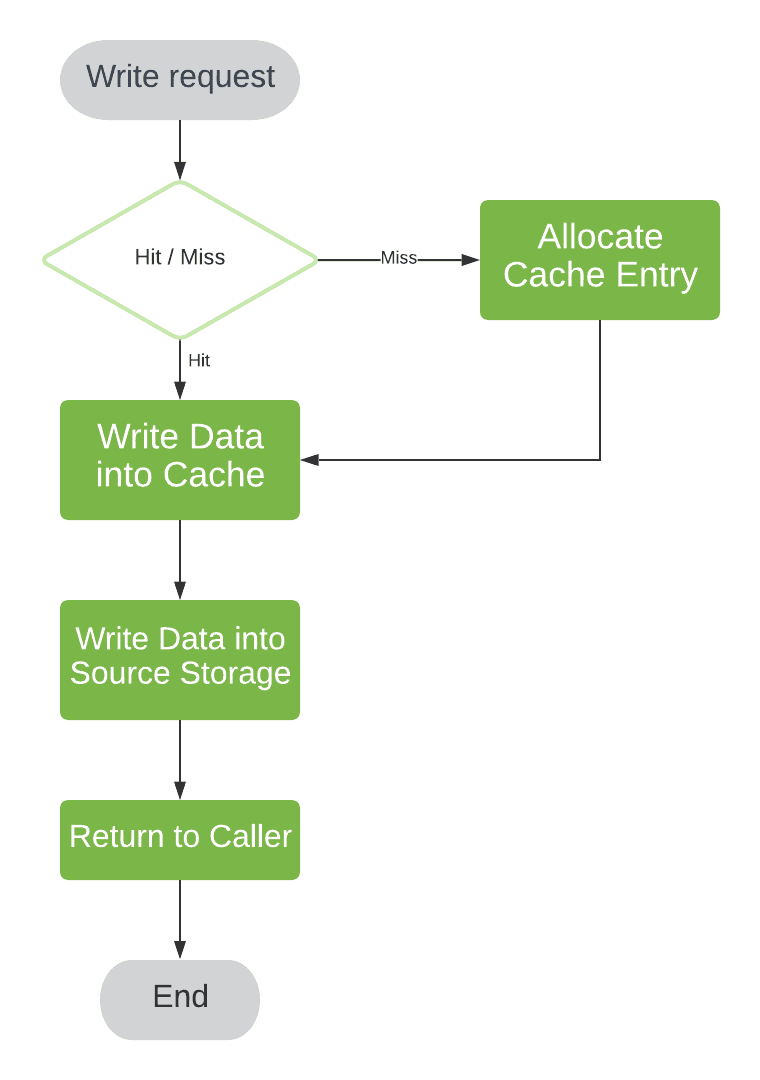
This is the easiest policy to implement and we refer to it write-through.
Now, write-through provides the best outcome in case we expect written data to be accessed soon. Depending on our cache usage pattern, this might be not true.
If we do not expect a read operation shortly after, the cache would become polluted with the entries we’re not using. To avoid cache pollution, we may bypass cache entry allocation in case of a cache miss:
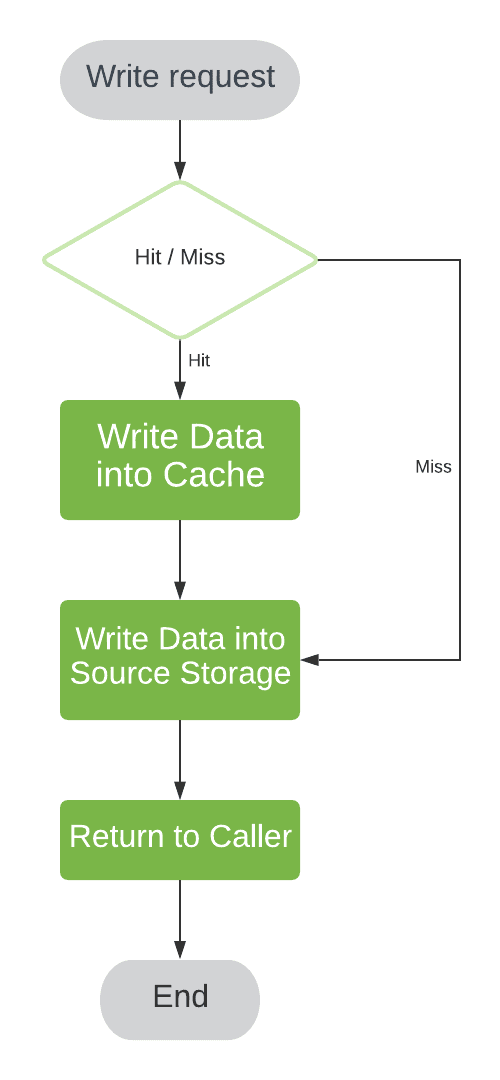
We refer to this policy as “write-through with no-write allocation” or write-around.
Yet another variation on write-through cache is write-invalidate policy. In this mode, along with the write operations going directly to the backing store, cache data entry undergoes invalidation in case of a cache hit.
While write-through provides us the best consistency, it does not help us with write operation latency – the cache returns a response to the client only after the backing store is updated.
We may take advantage of our fast cache storage to streamline this as well. To do this, we would have to return the response before updating the backing store. In this case, the backing store update happens asynchronously in a separate sequence.
We can kick off such a sequence in several ways – right before the response return, periodically, or integrated into cache eviction based on cache entry dirty state. For CPU caches, we use a dirty bit as a state indicator. In software caches, asynchronous kick-off before response return is generally preferable.
We call this type of policy write-back or write-behind:
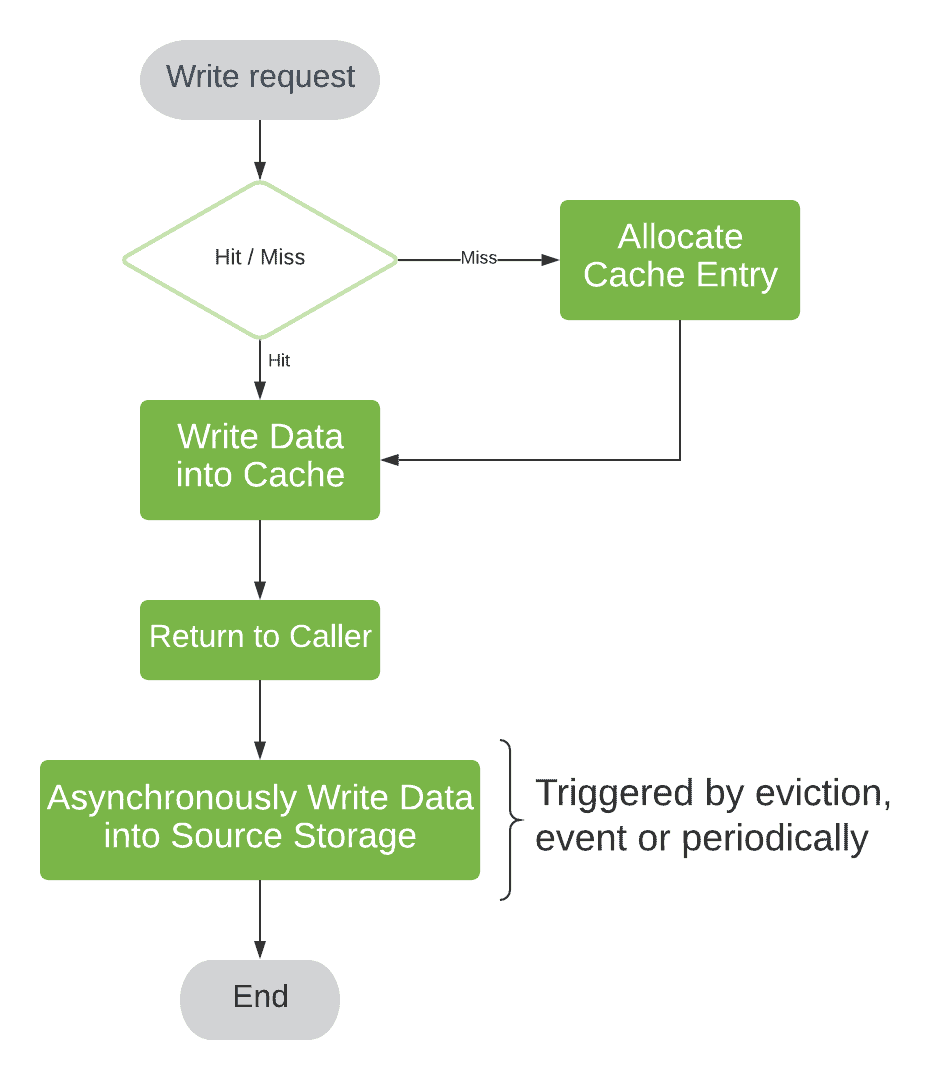
The asynchronous update brings us better responsiveness as well as the chance to improve throughput, for example, using source storage update batching.
Besides write-back having more difficult implementation, it’s possible to encounter consistency issues. Having cache in volatile memory, power outage before write-back is complete would result in data loss.
More subtle issues also emerge in write-back implementations. Consider when we access source storage not only via our cache instance but using some other means as well – either by another cache instance(s) or a direct write operation. The data which is not written to the backing store yet may reach the store only after the direct write operation is completed.
To ensure this does not happen, we must preserve operation order at some level. We call this technique transaction serialization.
Considering both the set of techniques to address this kind of problem and the concept itself we use the term cache coherence.
The same way we modified write-through policy to bypass the cache for cache misses, we may tune the write-back policy. This type of choice is known as write allocation:
Applying no-fetch-on-write to write-back may prove to be challenging depending on the sequence trigger to update the backing store. As a result, fetch-on-write is usually paired with write-back while no-fetch-on-write is applied more often to write-through.
No matter if we design our cache from scratch or intend to use one of the many available, we have to understand what kind of policy fits our needs best. In case we want to achieve maximum consistency, we are better off with write-through.
If we need to provide high performance for write operations, we may look into the write-back policy. As consistency issues may arise for write-back policies we may want to address those as well.
Furthermore, our cache access patterns in terms of read/write frequency and data locality may affect our policy choice and write allocation decision.
In this article, we’ve seen the various write policies used in caches.
We discussed the challenges this decision presents and the pros and cons of some known techniques.
Finally, we saw that there’s no universal answer to the kind of policy we should apply everywhere. Our specific choice depends on requirements focus, access patterns, and available resources.