Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 20, 2023

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll discuss some ambiguous concepts, namely cache miss, TLB (Translation Lookaside Buffer) miss, and page fault. To understand these concepts, we must first figure out how they work together like a symphony. Then we’ll get into more details about each component, and why we need them in the first place.
Let’s start by looking at the definitions before trying to understand how they work together.
The cache is like RAM, but it’s close to the CPU. Instead of going all the way through the RAM to access the necessary data, the CPU can get the data from the cache faster. However, if the data doesn’t exist in the cache, there will be a cache miss.
We can think of TLB as a memory cache. It reduces the time taken to access a memory location. We also call it to address translation cache, since it stores the recent translations of virtual memory to physical memory.
The virtual memory system in an operating system uses it as a data structure. It stores the mapping between virtual memory and physical memory. The memory management unit handles this specific translation.
The page table has a flag for each item that indicates if the related page is physical memory or not. The page table entry includes the physical memory address where the page is stored if it’s in the physical memory. However, if the hardware makes a reference to a page, and the page table entry for the page indicates that it’s not in the physical memory, page fault occurs. This invokes the operating system’s paging supervisor component.
Without memory hierarchy, it would be almost impossible for programmers to have unlimited amounts of fast memory. According to the principle of locality, most programs don’t access all code or data uniformly. As a result of this principle, combined with the smaller hardware is faster perspective, memory hierarchies vary in speed, cost and size. We can see the different levels of memory hierarchies in the figure below:
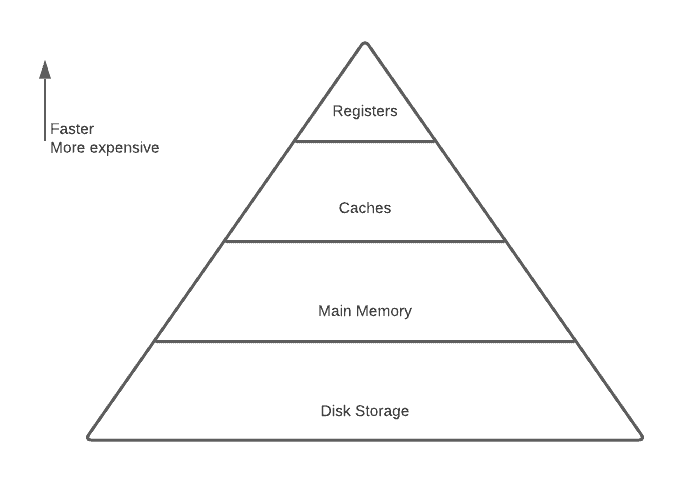
The goal is to provide a memory system with a lower cost, faster access, and larger area. This leads to different solutions at different levels. Caches improve the performance of CPUs; instead of going all the way to the memory, the CPU can directly access the caches. Furthermore, virtual memory makes physical memory infinite to programmers. By using virtual addressing, physical memory plays the role of cache for disks.
When we need a cache for virtual addressing, TLB comes into the stage and acts as a cache for virtual memory. It’s a kind of special cache for recently used translation of addresses. The operating system handles TLB misses as exceptions. It has a simple replacement strategy since TLB misses happen frequently.
When we look at the overall view, we can see that the caching mechanism has a crucial role in the memory hierarchy. It doesn’t only affect the performance on the hardware level, the mechanism itself leads to solving other issues in other abstraction levels as well.
Before getting into too many details about cache, virtual memory, physical memory, TLB, and how they all work together, let’s look at the overall picture in the figure below. We’ve simplified the below diagram so as not to consider the distinction of first-level and second-level cashes because it’s already confusing where all the bits go:
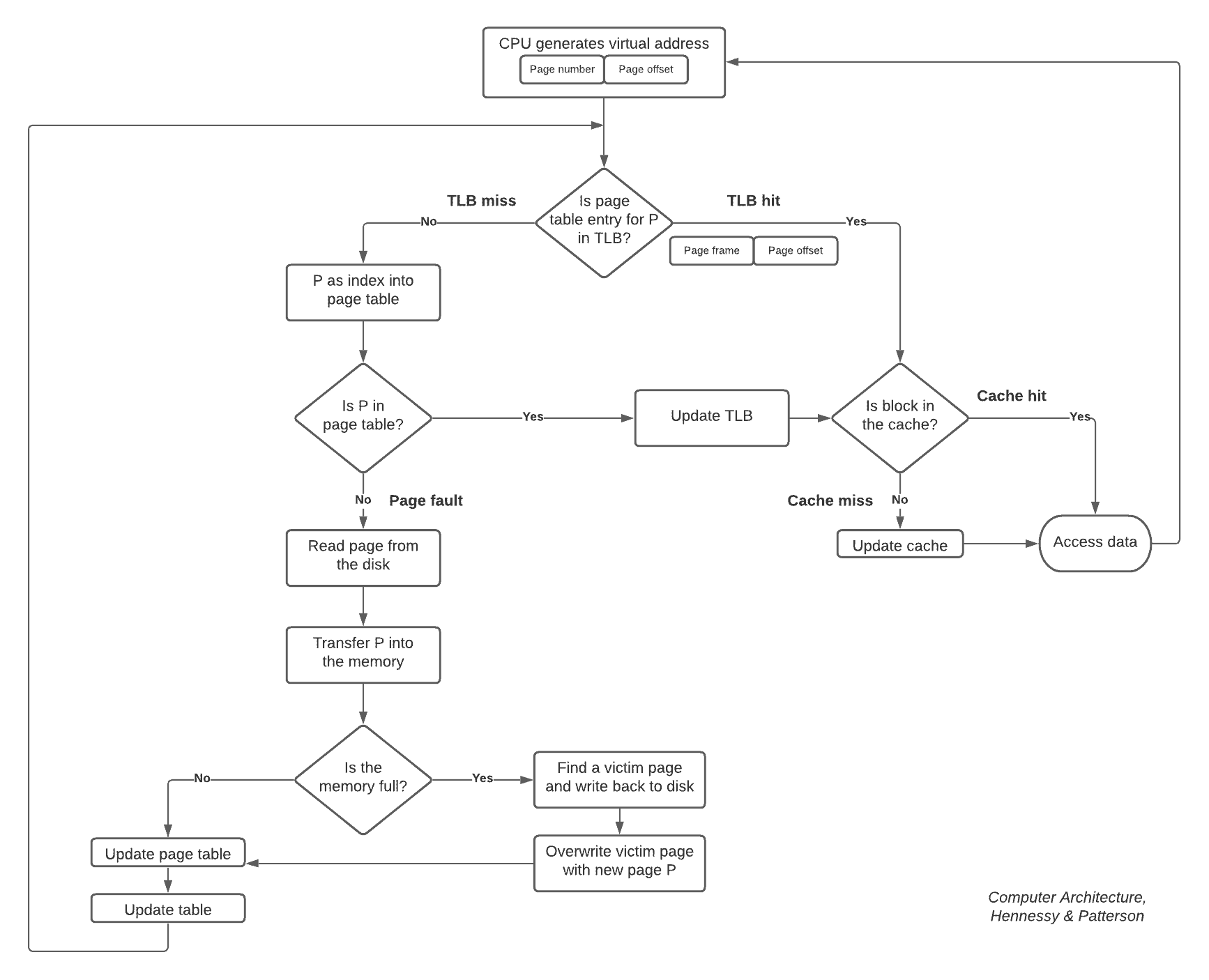
First, we can see the virtual address is logically divided into a page number and page offset. The page number is sent to the TLB; if the TLB match is a hit, then the physical page number is sent to the cache tag to control whether it’s a match. If it matches, it’s a cache hit. Otherwise, it’s a cache miss. In this case, we use the physical address to get the block from memory, and the cache will be updated.
TLB miss occurs if we don’t find the page inside the TLB. In this situation, we go to the page table to look for the corresponding page. If we can’t find the corresponding page in the page table, then page fault occurs. In this case, we read the page from the disk via the operating system.
When we transfer the page into memory, the memory can be full. In this case, we’ll find a victim page and overwrite the victim page with the new page, P. Then we’ll update the page table and TLB.
This is how the overall mechanism works under the hood. We’ve simplified some parts to share the main idea behind all these concepts. When we go into details, we’ll see there are different cache levels, as well as different types of TLBs coming into the stage to solve the issues in the memory hierarchy.
Although many terms are different, the cache is similar to virtual memory in some ways. Page or segment is like a block, and as a result, page fault or address fault corresponds for miss. As we’ve previously mentioned in this article, the CPU generates virtual addresses.
Hardware and software cope with these addresses and translate them into physical addresses which access the main (physical) memory. We call this process memory mapping or address translation.
There are also other differences between caches and virtual memory:
In this article, we shared important concepts for the memory hierarchy design in computing systems, First, we gave an overall view of a cache miss, TLB miss, and a page fault. Then we briefly introduced these concepts. Finally, we pointed out the differences between caches and virtual memory.