

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Data compression is a technique used to reduce the amount of data needed to represent a piece of information. It is essential in many areas, such as data storage, transmission, and archiving.
In this tutorial, we’ll focus on an efficient compression algorithm for short text strings.
We’ll explore the Burrows-Wheeler Transform (BWT) algorithm and how to combine it with the Run-Length Encoding (RLE) compressing algorithm to achieve a better compression ratio.
There are two main types of compression: lossless and lossy. Lossless compression guarantees that the data can be recovered exactly as it was before compression, while lossy compression may result in some loss of information. Let’s dive deeper into the lossless compression techniques.
Run-Length Encoding (RLE) is a way to compress data without losing any information (lossless compression). It replaces consecutive repeating characters with a single character and a number representing the number of times it appears. For example, the string  can be compressed to
can be compressed to  .
.
Here’s how it works:
Let’s now look at the implementation of the RLE compression algorithm. Here’s a pseudocode for implementing the BWT algorithm:
algorithm RLE(s):
// INPUT
// s = string
// OUTPUT
// compressed_string = the string after applying RLE compression
compressed_string <- an empty string // store the compressed output
i <- 0
while i < length(s):
// count occurrences of character at index i
count <- 1
while i + 1 < length(s) and s[i] = s[i + 1]:
count <- count + 1
i <- i + 1
// append current character and its count to the result
compressed_string <- compressed_string + string(count) + s[i]
i <- i + 1
return compressed_stringThe RLE method compresses repetitive sequences of characters in the input into shorter, more concise representations. As a result, the output is a compressed string containing the number of times a character appears in a row as well as the character itself.
The time complexity of the above solution is  , where
, where  is the length of the input string and doesn’t require any extra space.
is the length of the input string and doesn’t require any extra space.
Let’s say we have the following string:  :
:
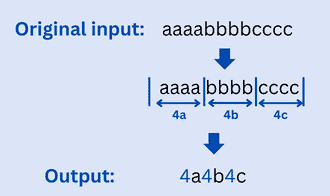
Using RLE, we would compress to  . As we can see, the compressed output is smaller in size than the original one, but when we decode it, it will give us the original string back. This is the basic concept of RLE, which help in data compression.
. As we can see, the compressed output is smaller in size than the original one, but when we decode it, it will give us the original string back. This is the basic concept of RLE, which help in data compression.
By compressing the repeating sequences in the input into shorter representations, this technique reduces the total size of the data. However, the RLE compression technique is not necessarily the most efficient form of data compression. Its performance varies depending on the data being compressed. This is when the BWT algorithm comes into play.
To improve the compression of short text strings, we’ll now explore the Burrows-Wheeler Transform (BWT) algorithm, a specific technique that is known for its efficiency in this area.
We are now ready to learn about the BWT. It’s a powerful data transformation method that is used in a lossless data compression algorithm. This makes it a great option for compressing sensitive data or important files.
One of the key features of BWT is its ability to group together similar characters in a string, which is a key factor in achieving efficient compression. Here’s how it works:
Let’s now take a look at the implementation of the BWT transformation. Here’s an algorithm for implementing the BWT transformation:
algorithm BWT(s):
// INPUT
// s = string
// OUTPUT
// bwt = the Burrows-Wheeler Transform of the input string
rotations <- create_rotations(s)
sorted_rotations <- sort(rotations)
bwt <- last_column(sorted_rotations)
return bwtThe overall algorithm for the BWT transformation is quite simple. First, the algorithm takes a string as input. Next, we create all possible rotations of the string. Then, we sort them lexicographically. Finally, we get the last column of the sorted rotations, which is the BWT of the original string.
The BWT algorithm can be broken down into just three simple steps. Let’s take a look at the three functions that are used in the BWT approach:
After the transformation of a string, we need to recover the original data. Here are the steps for implementing the inverse BWT (IBWT):
 to
to  , where is the length of BWT(S):
, where is the length of BWT(S):
 character of BWT(S) to the beginning of the row
character of BWT(S) to the beginning of the rowLet’s look at how to transform a string with the BWT transformation method and how to recover the original string after transformation.
Let’s say our string is “DOGWOOD“. To make things easier, we’ll add a special character, “$”, to the end of the string. This end character doesn’t appear anywhere in the original string. Here’s an example of applying the BWT approach on the string “DOGWOOD$” to obtain “DO$OODWG” as an output:
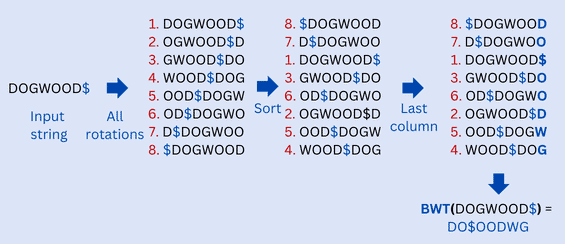
We have “DO$OODWG” as the transformed string of the BWT method. Let’s apply the IBWT approach to recover the original string “DOGWOOD“:

As we can see, we repeat the process of prepending a column of characters of the string “DO$OODWG” and sorting the rows of the obtained matrix until the number of columns of the matrix reaches the length  of the input. This means the number of columns is equal to the number of rows. Then, we search for the row that has the end-of-file ($) character. This row corresponds to the original input string “DOGWOOD$”.
of the input. This means the number of columns is equal to the number of rows. Then, we search for the row that has the end-of-file ($) character. This row corresponds to the original input string “DOGWOOD$”.
Let’s now combine the RLE with the BWT to enhance the data compression.
Here’s a pseudocode for implementing BWT followed by RLE:
algorithm BWTRLE(s):
// INPUT
// s = string
// OUTPUT
// compressed_string
bwt <- BWT(s)
compressed_string <- RLE_compress(bwt)
return compressed_stringThe RLE_compress(bwt) function used in the implementation takes the BWT-transformed string as input and applies the RLE compression algorithm to return the compressed string.
Let’s use an example to make everything clear. Let’s say our string is “ABCABCABC“. As we can see, if we compress it using the RLE method we obtain “1A1B1C1A1B1C1A1B1C” as the compression output. This output has doubled the size of the original data. This is definitely not what we want as a result of using the compression method.
Let’s now apply the BWT approach to the string before the compression. Here’s an example of applying the BWT approach on the string “ABCABCABC“:
| Transformation | ||||
|---|---|---|---|---|
| Input | All Rotations | Sort the Order | Last Column | Output |
ABCABCABC |
 ABCABCABC ABCABCABC |
3C A A |
ABC ABCABC ABCABC |
|
CABCABC ABC ABC |
ABCABC ABC ABC |
ABCABCABC |
||
BCABC ABCABCA ABCABCA |
BC ABCAB ABCAB |
BCABC ABCA ABCA |
||
ABC A A |
BCABCABC ABCABCA ABCABCA |
C ABCABCAB ABCABCAB |
||
C ABCAB ABCAB |
CABC ABCABCABC ABCABCABC |
CABCABC AB AB |
||
Our final result is “CCC$AAABBB”, which is the BWT of the original string. Let’s now take a look at the chunks of repeated characters, like the 
 ‘s. This is where compression comes in. The output “CCC$AAABBB” can be stored as “3C$3A3B” using the RLE to compress it.
‘s. This is where compression comes in. The output “CCC$AAABBB” can be stored as “3C$3A3B” using the RLE to compress it.
Same as any approach, BWT has its benefits and drawbacks. Let’s then take a look at the benefits and drawbacks of the BWT in data compressing:
| Advantages | Disadvantages |
|---|---|
| High compression ratio: The BWT algorithm can achieve a higher compression ratio than other algorithms such as LZ77 and LZ78, especially for short strings | Not suitable for long strings: The BWT algorithm is not as effective for long strings as it is for short strings. |
| Simple implementation: The BWT algorithm is relatively simple to implement and can be easily integrated into existing compression tools. | Not suitable for data with no repeating patterns: The BWT algorithm relies on finding repeating patterns in the input data, so it may not be suitable for data that does not have many repeating patterns. |
| Invertible: The BWT algorithm is invertible, meaning that the original string can be easily recovered from the transformed string. |
In this tutorial, we have discussed the RLE algorithm and how it can be used to compress short text strings efficiently.
We have also explored how combining BWT with the RLE compression technique can result in even better compression ratios. We have provided pseudocode examples to give a better understanding of the implementation of the algorithm.