

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
An enumerated type is a data type that contains only a finite set of named values, and they are supported in most modern programming languages.
The feature is usually known as enumerations or enums. And it will allow us to declare a type by listing all its possible elements.
Scala is a multiparadigm language, consequently inherited from two ways of creating enumerated types.
Enumerations are purely object-oriented, while algebraic data types are aligned towards functional programming.
Raising the question, which one should we use when and why?
Scala enumerations are simple to use:
object CurrencyEnum extends Enumeration {
type Currency = Value
val GBP = Value(1, "GBP")
val EUR = Value
}If we do not provide the ordinal and/or name, the Scala compiler will assign defaults. Scala keeps track of the numbers used and assigns the next one, and it starts with zero if we do not give any explicit input. In contrast, the string is by default the name of the variable.
Unfortunately, enumerations have two big disadvantages:
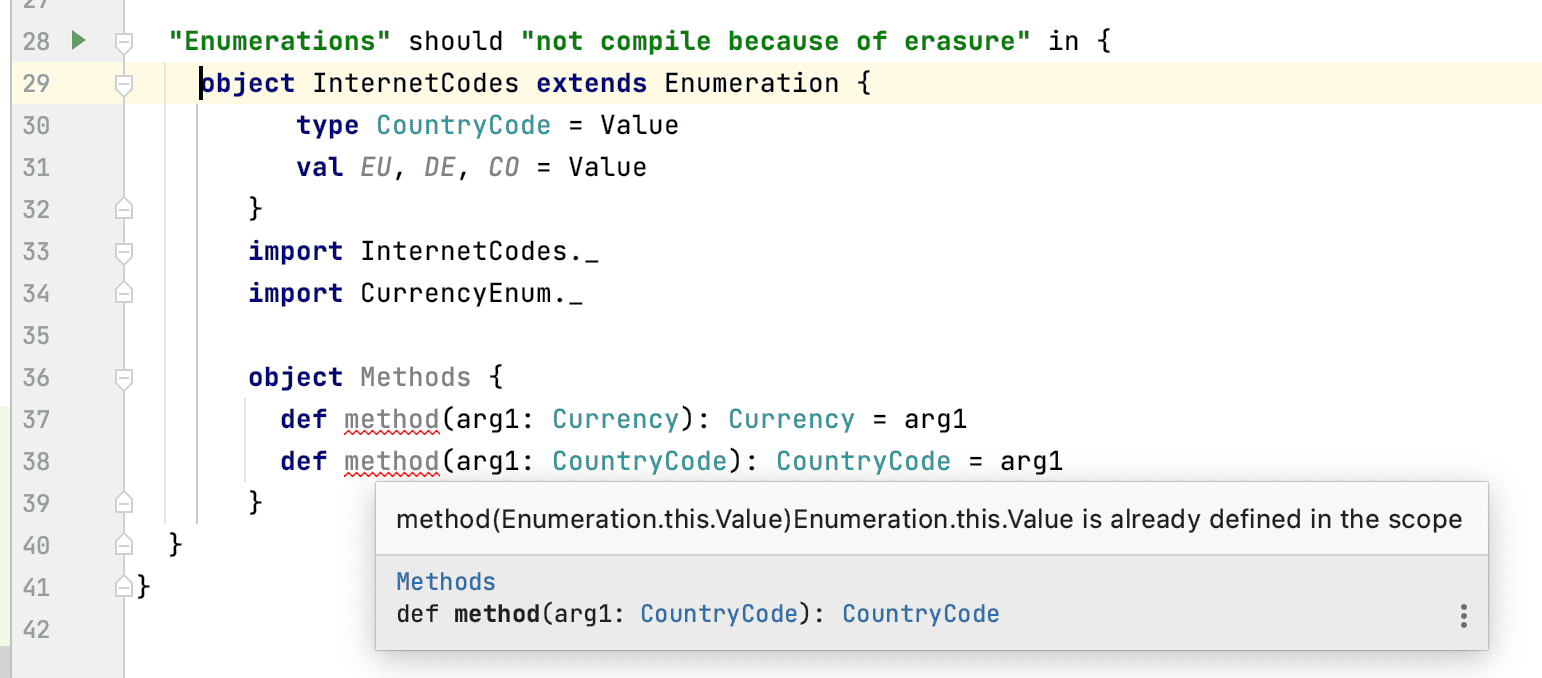
Another minor issue is that it is harder to extend the elements to hold more data.
An algebraic data type is one where we specify the shape of each element. Therefore, we can apply them in the same use cases as enumerations.
Scala has support to encode algebraic data types such as product types and sum types. To encode enumerations, we only need sum types.
In Scala 2, sum types are written using sealed traits or abstract classes and case objects:
sealed abstract class CurrencyADT(name: String, iso: String)
object CurrencyADT {
case object EUR extends CurrencyADT("Euro", "EUR")
case object USD extends CurrencyADT("United States Dollar", "USD")
}The disadvantage with this approach compared to extending Enumeration is that we won’t automatically obtain the way to iterate through the elements or get an element from a string.
Therefore, we won’t be able to write code for the Currency ADT similar to the following:
import CurrencyEnum._
println(EUR)
println(CurrencyEnum.withName("GBP"))
for (cur <- CurrencyEnum.values) {
println(cur)
}ADTs solve the two major issues identified with enumerations.
Sealing the base class/trait means that only code in the same file can extend them; thus, the compiler can check pattern matches are exhaustive, eliminating one class of runtime errors.
Using case objects instructs the compiler to generate improved defaults for the equals, hashCode, and toString methods. The default toString method will return a string with the object’s name, making them a good fit to implement enumerations.
These features are orthogonal; in other words, we can use them independently, and their effects are complementary:
abstract class CurrencyADT(val name: String, val iso: String)
object CurrencyADT {
case object EUR extends CurrencyADT("Euro", "EUR")
case object USD extends CurrencyADT("United States Dollar", "USD")
}
In the example above, we used case objects with an unsealed base class to give us most of the benefits, except the exhaustiveness checks.
On the other hand, we could use a sealed base class with normal objects, getting the exhaustiveness checks and providing our own toString, hashCode, and equals implementations.
The withName function is handy, but it has a big problem. It is not safe and might throw a NoSuchElementException, which might be acceptable for some imperative code, but it makes it hard to use in a functional codebase.
We can write a pure version for our ADT:
def fromIso(iso: String): Option[CurrencyADT] = {
iso.toUpperCase match {
case "EUR" => Some(EUR)
case "USD" => Some(USD)
case _ => None
}
}Iterating over all the values of an enumeration is not a common use case, but if we really need to, it can be easily written:
object CurrencyADT {
// Previous code omitted for conciseness val values:
Seq[CurrencyADT] = Seq(EUR, USD)
}Depending on the type of enumeration, we could convert the disadvantage into an advantage by using a different collection type like a Map, and we can even use it to simplify the parsing method:
val isoToCurrency: Map[String, CurrencyADT] = values.map(c => c.iso -> c).toMap
def fromIso(iso: String): Option[CurrencyADT] = isoToCurrency.get(iso.toUpperCase)
Writing the code to overcome ADT disadvantages can be tedious, but we can still conclude that in balance, the ADT approach is the best option.
Scala enumerations are not compatible with Java; that is to say, Java code won’t be able to use an enumeration declared in Scala, regardless of which approach we chose to encode them.
Scala 3 solves these problems by unifying ADTs and enums under a new syntax, which we can optionally make compatible with Java Enums:
object CurrencyADT(name: String, iso: String) extends java.lang.Enum {
case EUR("Euro", "EUR")
case USD("United States Dollar", "USD")
}This new syntax will solve all the issues with both of the enumeration approaches in Scala 2 and grant us Java compatibility.
In this tutorial, we have reviewed our options to write enumerated types in Scala 2 and understood both approaches’ pros and cons.
We’ve also delved into the future and saw a preview of how Scala 3 unifies ADT and enums giving us a single syntax for both features.