

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Jenkins Walkthrough and Scripting Filesystem Operations
Last updated: February 2, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
Jenkins is a widely used automation server written in Java. It can streamline job and task execution into organized batches. One common task we might want to perform via a Jenkins server is file movement and duplication. This can be helpful in many cases:
- package installation
- container deployment
- general configuration
- data backup
In this tutorial, we delve into Jenkins and explore ways to write a script for copying or moving files between paths. First, we overview the Jenkins terminology. Next, we go over a usual deployment and its main Web user interface (UI). After that, we see the steps to use an alternative, command-line interface (CLI). Then, we go through some ways to check the output of Jenkins processes. Later, we understand system configuration and security in Jenkins. Finally, we demonstrate several of these concepts in a concise example.
We tested the code in this tutorial on Debian 12 (Bookworm) with GNU Bash 5.2.15. It should work in most POSIX-compliant environments unless otherwise specified.
2. Jenkins Terminology
Before delving into practical aspects, let’s understand the basic terminology of a Jenkins installation.
2.1. Jobs (Projects)
Previously known as projects, jobs are the top-level unit of execution in Jenkins.
The term job can be a bit misleading when coming from other automation frameworks and servers since many of them use the word to designate a general unit of work instead of work organization. Thus, we may encounter this term misused within the context of Jenkins as well.
In any case, jobs can be different types, but one is usually the most common.
2.2. Pipelines
Since 2016, the Jenkins Pipeline set of plugins, based on the Apache Groovy language, became a default part of each Jenkins installation. This is the fundamental way to create pipelines in the system, mainly as Jenkinsfile Groovy scripts.
A pipeline is a job type most often used for long-running process automation. Effectively, it groups tasks that usually interact via their inputs and outputs.
For example, we can represent a basic compilation and deployment:
- compile code
- test executable
- deploy in production
Understanding how data flows and transforms through this process enables us to implement a pipeline for it.
2.3. Steps (Tasks and Stages)
Each pipeline has different steps. When it comes to Jenkins, a step is a task run at a given stage. While tasks are activities such as compiling, executing, moving, and others, stages represent the sequence and grouping of those activities.
For example, we can’t compile code before writing it, and we can’t deploy before compiling:
+---------+ +------+ +--------+
| Compile |---->| Test |---->| Deploy |
+---------+ +------+ +--------+So, task order is important. Further, folders enable better task organization similar to that of a filesystem.
2.4. Executors (Workers, Runners) and Agents (Nodes)
In Jenkins, the entities that work on steps are called executors or runners. Yet, executors only manage the task, while Jenkins ensures proper scheduling.
Importantly, the existence and availability of more than one executor for a given step means we may be able to parallelize task execution:
+---------+ +------+ +--------+
| Compile |---->| Test |---->| Deploy |
+---------+ +------+ +--------+
| |
|CRunner1 |TRunner1
|CRunner2 |TRunner2
|... |...
|CRunnerN |TRunnerNIn this case, we have several runners for compilation and testing.
Each executor can be spawned by a different node, i.e., a machine within the Jenkins deployment.
2.5. Builds
The run of any step is considered a separate build. Thus, builds represent the process and result from the execution of a given step.
For example, we might want to terminate a whole pipeline based on the failure of a single task or just inform the following step of that. There are several values for the status of a build:
- aborted: interrupted manually or due to a timeout
- failed: unrecoverable error
- stable: stable success
- successful: success
- unstable: non-fatal errors
Finally, a build can run as part of a scripted schedule in Jenkins, but it can also have triggers such as explicit build calls, external scheduling like cron, webhooks, requests, and others.
2.6. Plugins
Due to its open-source nature and licensing, Jenkins is extendable via plugins. In particular, although its initial target was Java, Jenkins evolved to support many other languages specifically for its continuous integration and deployment facilities.
Further, plugins exist to support external version control systems, security and notification mechanisms, and many others.
3. Jenkins Deployment
There are several ways to deploy Jenkins.
In our case, we use the Docker container:
$ docker run --name jenkins --publish 8080:8080 --detach jenkins/jenkinsThus, we execute docker to run a new [–detach]ed container with the –name jenkins, which also pulls the correct image. Further, we –publish port 8080, so we can access the installation from the local network.
At this point, we should be able to see the Jenkins main Web UI at https://xost:8080 after logging in, assuming our host is called xost:
Notably, the default Jenkins installation sets up several JENKINS_ [env]ironment variables for easier handling of different system aspects:
$ env | grep JENKINS
JENKINS_UC_EXPERIMENTAL=https://updates.jenkins.io/experimental
JENKINS_INCREMENTALS_REPO_MIRROR=https://repo.jenkins-ci.org/incrementals
JENKINS_SLAVE_AGENT_PORT=50000
JENKINS_VERSION=2.442
JENKINS_UC=https://updates.jenkins.io
JENKINS_HOME=/var/jenkins_homeOne of them is the $JENKINS_HOME variable, which indicates the current main Jenkins installation path:
$ echo $JENKINS_HOME
/var/jenkins_homeWithin, we can find some potentially important subdirectories:
$ ls -1d $JENKINS_HOME/*/
/var/jenkins_home/jobs/
/var/jenkins_home/logs/
/var/jenkins_home/nodes/
/var/jenkins_home/plugins/
/var/jenkins_home/secrets/
/var/jenkins_home/updates/
/var/jenkins_home/userContent/
/var/jenkins_home/users/
/var/jenkins_home/war/Specifically, jobs contains all current jobs along with their builds and build logs:
$ tree $JENKINS_HOME/jobs/
/var/jenkins_home/jobs/
└── baelpipe
├── builds
│ ├── 3
│ │ ├── build.xml
│ │ ├── log
│ │ └── log-index
│ ├── legacyIds
│ └── permalinks
├── config.xml
└── nextBuildNumberIn this case, we have one job with the name baelpipe with one build, which should be the third (3) one. The first two were manually deleted.
4. Jenkins Command Line Interface (CLI)
In addition to the Web UI, Jenkins offers a CLI client, jenkins-cli. Similar to the server part, jenkins-cli is written in Java.
However, it’s available as a single JAR file, which we can access even from the Web server:
- Go to Manage Jenkins, usually at http://<JENKINS_HOSTNAME_OR_IP>:8080/manage/
- Select Jenkins CLI, leading to http://<JENKINS_HOSTNAME_OR_IP>:8080/manage/cli/
- Click jenkins-cli.jar to get http://<JENKINS_HOSTNAME_OR_IP>:8080/jnlpJars/jenkins-cli.jar
At this point, we should have the Jenkins client file. The Jenkins CLI page usually has instructions for running it:
$ java -jar jenkins-cli.jar -s http://<JENKINS_HOSTNAME_OR_IP>:8080/ helpHere, we use java to run the client -jar file, passing it the [-s]erver URL and pulling up the help.
What it doesn’t immediately show is the -auth option that permits access to actual management subcommands:
$ java -jar jenkins-cli.jar -s http://<JENKINS_HOSTNAME_OR_IP>:8080/ -auth <JENKINS_USERNAME>:<JENKINS_PASSWORD>
add-job-to-view
Adds jobs to view.
build
Builds a job, and optionally waits until its completion.
cancel-quiet-down
Cancel the effect of the "quiet-down" command.
clear-queue
Clears the build queue.
connect-node
Reconnect to a node(s)
console
Retrieves console output of a build.
copy-job
Copies a job.
[...]Of course, we can use the CLI to perform any operation we can from the Web UI.
5. Jenkins Logs
In Jenkins, the Web UI is a helpful way to handle system activities, including job creation, build initiation, build status checks, and others. However, most of these activities produce logs, which we can check in other ways as well.
5.1. Build Results
Naturally, the Web UI is often the go-to method for looking at the overall system and job status.
For instance, let’s run a failing build and see the result:
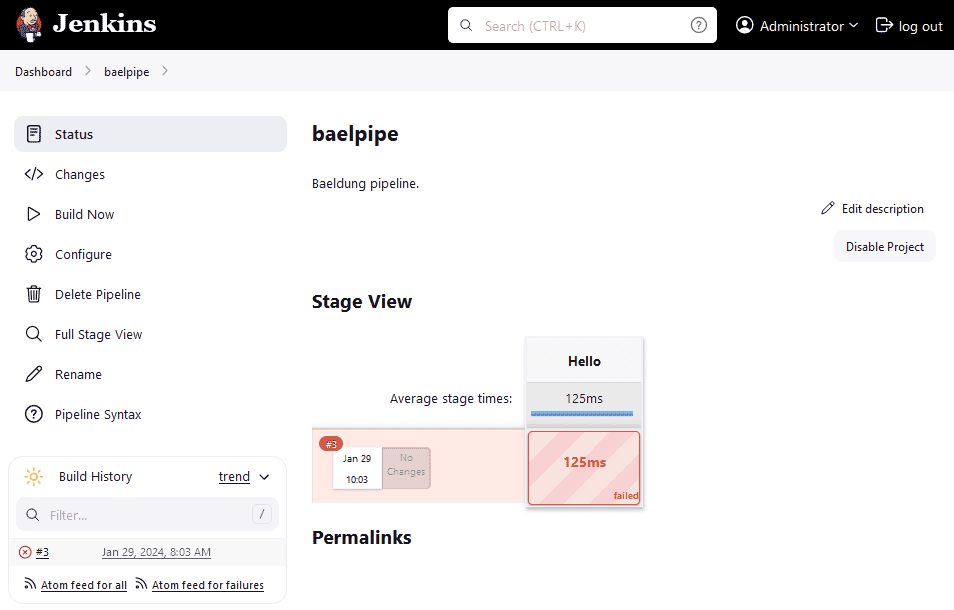
Here, we can see a basic failure screen in Stage View.
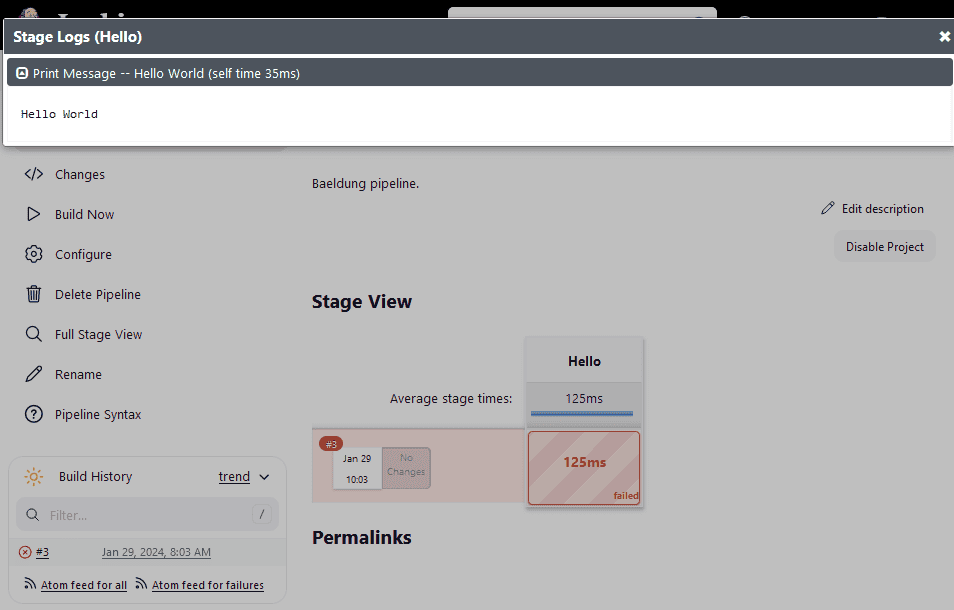
Yet, we may want to see the logs to understand where the issue lies, but there are no errors there:
To reach any lower-level errors, we might have to check the Console Output:
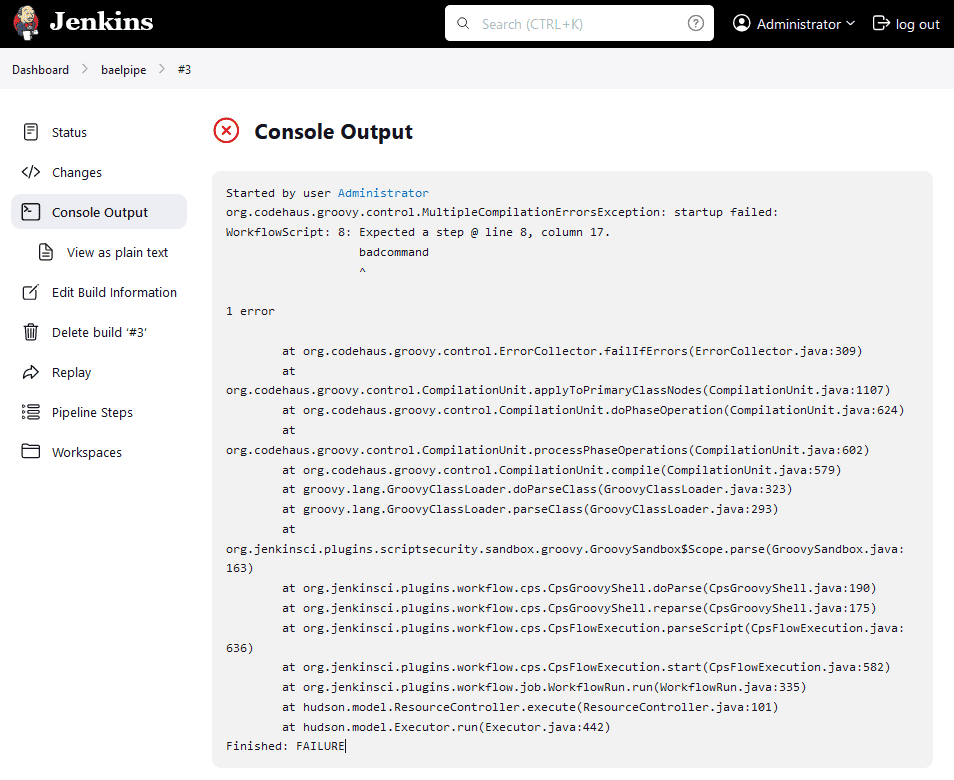
However, these are just text logs, so we have other ways to check them.
5.2. Log Location
Within each build directory under $JENKINS_HOME/jobs/ for a specific job, we can find a log file:
$ cat $JENKINS_HOME/jobs/baelpipe/builds/3/log
Started by user ha:////4DjQqKtQOr9I+VnRz88sm666VTh1ehs1zY29phH5PmXzAAAAlx+LCAAAAAAAAP9b85aBtbdexTGjNKU4P08vOT+vOD8nVc83PyU1x6OyILUoJzMv2y+/JJUBAhiZGBgqihh666SjKDWzXb3RdlLBUSYGJk8GtpzUvPSSDBmxtKinBIGIZ+sxLJE/ZzEvHT94JKizLx0a6BxUmjGOUNodHsLgAzeEgZu/c0x1CL9xJTczDwACG0V4sAAAAA=Administrator
org.codehaus.groovy.control.MultipleCompilationErrorsException: startup failed:
WorkflowScript: 8: Expected a step @ line 8, column 17.
badcommand
^
1 error
[...]
Finished: FAILUREThus, we see the same output we already got from the Web UI.
6. System and Security Context
For any operation to succeed, we need the proper context and permissions.
6.1. Jenkins Operating User
To verify parameters like the operating user, Jenkins provides the System Information page at http://<JENKINS_HOSTNAME_OR_IP>/manage/systemInfo. In particular, the page contains the user.name parameter, indicating the user under which Jenkins runs jobs.
For a majority of deployments, the default user is jenkins.
6.2. Data Permissions
Before attempting any operations with it, we always have to be aware of the current data permissions.
Naturally, we can check the permissions of [-d]irectory paths via ls and its [-l]ong list flag:
$ ls -ld /var/source/
drwxr--r-- 2 root root 4096 Jan 31 10:01 /var/source/
$ ls -ld /var/destination/
drwxr--r-- 2 root root 4096 Jan 31 10:02 /var/destination/Notably, both of these directories are owned, writable, and listable (executable) by their owner, root, but have only read permissions for everybody. Thus, we won’t be able to enumerate or modify the directory contents unless we can execute and write respectively. Similarly, we can’t write to the destination before we reconfigure.
In this case, we need access without obstructions, so we change the owner of both locations:
$ chown --recursive jenkins:jenkins /var/source/ /var/destination/Here, we use chown to [–recursive]ly change the owning user and group of /var/destination/ to jenkins.
6.3. Pipeline Script Access
By default, Jenkins Pipeline scripts and many plugins execute in a sandboxed environment to prevent malfunctioning or malicious code from causing damage. The Groovy Sandbox limits script access within certain boundaries both in terms of storage and features. For example, no direct raw API calls can be made to Jenkins and filesystem access is mostly prohibited apart from a small workspace directory with the project name, usually under /var/jenkins_home/workspace/.
If we want to avoid such restrictions, we can uncheck the Groovy Sandbox option below the script. However, we might have to await script approval by an administrator:
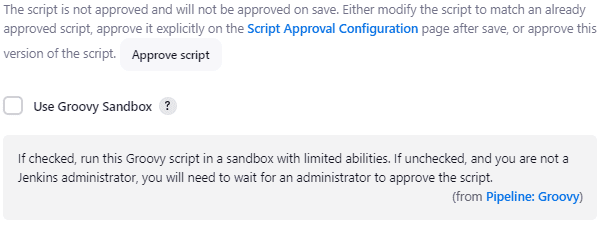
In any case, after getting permissions, we should be able to perform any operation we have privileges for.
7. File Moving and Copying
To demonstrate the Jenkins facilities, we can perform a fairly simple file copy operation in several ways. Let’s assume the source is /var/source/file and the destination is /var/destination/, with all permissions properly set up.
7.1. Using Shell Commands
One of the most fundamental interactions with an operating system (OS) is its shell. Because of this, the Jenkins Pipeline offers both bat() and sh() for running commands in the Microsoft Windows and UNIX shells respectively.
So, we can leverage sh() to write a basic job:
pipeline {
agent any
stages {
stage('shellcopy') {
steps {
script {
try {
sh(script: 'cp /var/source/file /var/destination/', returnStdout: true)
} catch (Exception ex) {
echo 'Exception: ' + ex.toString()
}
}
}
}
}
}In this pipeline, we have a single stage (shellcopy) with a single step. The latter contains a script that executes cp /var/source/file /var/destination/ in the [sh]ell of the agent it runs on. Importantly, we know this script runs on our only agent – the Jenkins server node itself.
Similarly, we can do the same with mv and others. Of course, configuring and using sudo on the node in question enables us to prepend that to the cp operation and avoid having to change permissions.
7.2. Using Native Groovy Script
The Groovy language itself is fully equipped to perform many operations natively on different systems.
For example, we can work with files and copy data:
import java.nio.file.Files;
import java.nio.file.Paths;
pipeline {
agent any
stages {
stage('groovycopy') {
steps {
script {
File source = new File('/var/source/');
File[] filesList = source.listFiles();
for (File file : filesList) {
if (file.isFile()) {
echo file.getName()
Files.copy(Paths.get(file.path), Paths.get('/var/destination/' + file.getName()));
}
}
}
}
}
}
}This time, we create a Groovy File object out of the source path and then listFiles() in it. Finally, we copy each file via Files.copy().
Critically, we import two libraries from nio (New Input/Output) file to ensure the paths parsing and copy operations.
Although this operation is successful, we might encounter issues on each rerun, since Files.copy() doesn’t replace by default.
7.3. Using File Operations Plugin
Finally, we can use alternative plugins for our needs.
In particular, Jenkins offers the file-operations plugin that we can integrate into our project. Notably, to do so, we create a so-called Freestyle project:
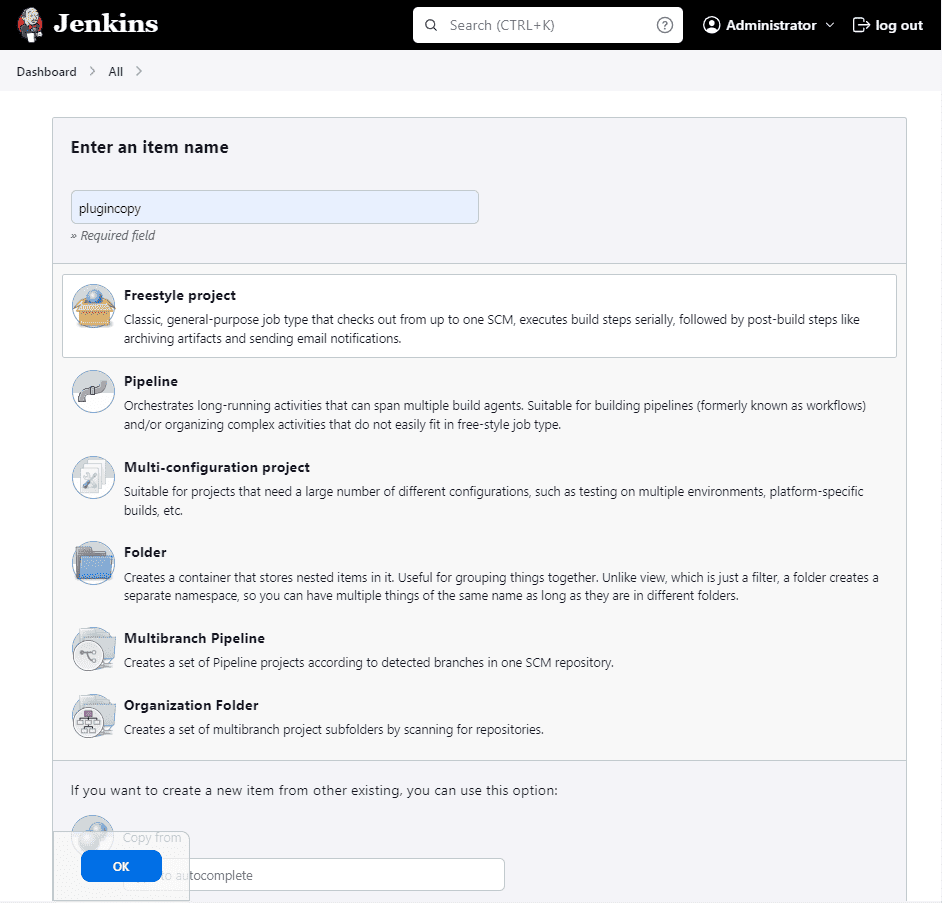
Then, we go over to the Build Steps section:
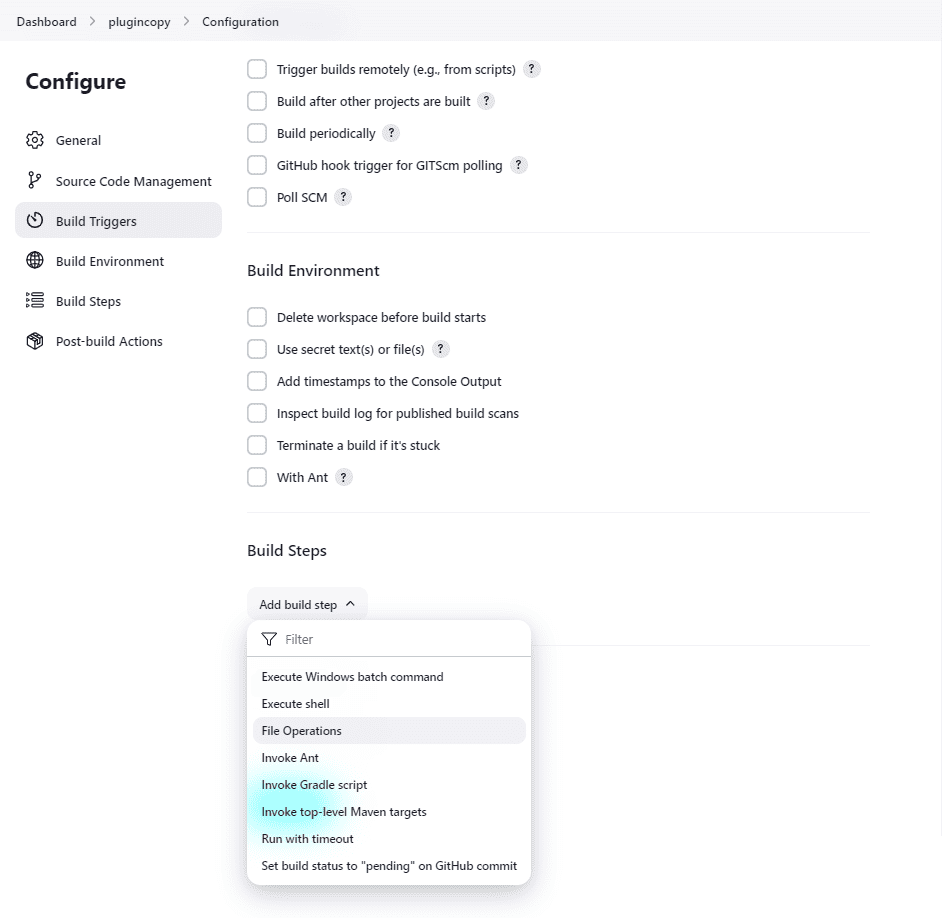
After that, we can add the operation:
- Click on Add build step
- Select File Operations
- Click on Add
- Select File Copy
- Add file as Include File Pattern
- Add /var/destination/ as Target Location
- Save
Critically, the UI doesn’t readily enable us to copy from anywhere but the current working directory, which is the project workspace path by default. We can usually check the current contents under /var/jenkins_home/workspace/, followed by the project name, or by visiting the ws or Workspace page of the project in the Web UI.
So, we might still opt for a scripted pipeline (instead of a freestyle) project that employs fileOperations(), but switches the current working directory via dir() beforehand:
pipeline {
agent any
stages {
stage('plugincopy') {
steps {
script {
dir('/var/source/') {
fileOperations([fileCopyOperation(excludes: '', flattenFiles: true, includes: 'file', targetLocation: '/var/destination/')])
}
}
}
}
}
}Thus, we should get the results we saw earlier:
Started by user Administrator
[Pipeline] Start of Pipeline
[Pipeline] node
Running on Jenkins in /var/jenkins_home/workspace/plugincopy
[Pipeline] {
[Pipeline] stage
[Pipeline] { (plugincopy)
[Pipeline] script
[Pipeline] {
[Pipeline] dir
Running in /var/source
[Pipeline] {
[Pipeline] fileOperations
File Copy Operation:
/var/source/file
[Pipeline] }
[Pipeline] // dir
[Pipeline] }
[Pipeline] // script
[Pipeline] }
[Pipeline] // stage
[Pipeline] }
[Pipeline] // node
[Pipeline] End of Pipeline
Finished: SUCCESSNaturally, we can see the directory switch as well.
8. Summary
In this article, we explored Jenkins with a basic scenario of file moving and copying.
In conclusion, Jenkins is a multi-faceted system that can serve to automate basic tasks such as file copying, but also incorporate these into complex pipelines.