
1. Overview
The previous build closed on a screenshot of the agent’s context window near the ceiling, with a one-line warning: “in this lesson we nearly ran out of context within the agent. That’s why the next lesson is about managing it.” This is that lesson. Context is a finite (and expensive) resource we need to manage through multiple levers, not a single trick. Let’s now focus on that resource – context – as a budget with six distinct facets:
- (1) prompt hygiene,
- (2) sub-agent dispatch,
- (3) decomposition reasoning,
- (4) briefing,
- (5) the Opus-plans / Sonnet-executes model split, and
- (6) /compact.
Lever 1, prompt hygiene, has actually been quietly running since the Adding Tests rebuild. The prompt body has been shrinking while project complexity hasn’t, because durable content keeps migrating into CLAUDE.md. The file has grown from two sections to seven across the last three rebuilds; this rebuild’s prompt body is the previous rebuild’s modulo two added lines. For a one-shot rebuild like this one, the location doesn’t actually change anything. Whether a rule sits verbatim in the prompt or in CLAUDE.md, the same information lands in the same context window, so the token cost is identical. Where it pays off is future conversations and additional features built on the same project, where durable rules already live in the right home instead of being re-typed. We’ll explore this separately.
One framing note carries through the rest of the lesson: once sub-agents enter the picture, the window the developer manages is the main agent context (the orchestrator’s), not the sum of every window the system opens.
This lesson narrates the recorded run on the module2-lesson5 branch in private/faic.
2. Setting Up the Experiment
The setup mirrors the previous four runs. Fresh codebase on the module2-lesson5 branch; we’ll carry forward main artifacts from the previous rebuild: CLAUDE.md, checkstyle.xml, .gitignore, .claude/settings.local.json. Same model family, same tools, same Jira Lite spec.
Simply put, we’ll focus on context as a managed resource; everything else is mostly the same.
3. Telling the Orchestrator When to Dispatch and Which Model to Use
Two new sections need to land in CLAUDE.md: ## Sub-Agents first, the context-isolation lever, and ## Models second, the cost and capability lever. Here’s why each is shaped the way it is.
Sub-Agents
A sub-agent is a separate Claude Code session the orchestrator spawns to handle a bounded chunk of work. (The orchestrator, the main Claude Code session we sent the prompt to, and the main agent are the same thing.) It has its own context window, returns only the result, and the orchestrator’s window only sees the summary, not the line-by-line generation. That’s why it’s such as powerful way of keeping the orchestrator context clean: the bulky work happens elsewhere, and the main agent context, the window we’re trying to keep lean, stays light.
The why is decomposition, and it isn’t really optional. On any reasonably sized project (even this one, which is barely past just beginning), a single agent can’t fit everything inline within its context window. You run out. Dispatching sub-agents is what forces the main agent context to stay clean by moving the bulky work elsewhere, and that constraint is how the build finishes at all.
Mechanically, sections nothing else depends on (controllers, tests, DTOs, the terminal nodes in the project’s dependency graph) are the natural candidates: hand them off, integrate the result. Foundation work (entities, the core service graph, security configuration) stays with the orchestrator because everything else builds on top of it. Briefing is implicit in the section text: CLAUDE.md is auto-inherited by every sub-agent, so the durable rules travel for free.
Models
The ## Models section picks up where the model framing left off earlier in the course. Here’s the split earning its place across these rebuilds: Opus for planning, decomposition, and judgment; Sonnet for mechanical execution. Opus is better at planning and judgment; Sonnet is fast and cheap enough for execution where there aren’t hard calls to make. Window size is not the deciding lever anyway. Current Claude Code can expose 1M-context variants for both Opus and Sonnet when the account and model selection support them, but long-context degradation is a property of the transformer architecture itself, not of any one model: cross-model studies covering Claude, GPT, Gemini, Llama, Mistral, and Qwen all show output quality declining gradually as input grows, well before the nominal window fills. So the practical ceiling is set by quality decay, not by the token limit, and the levers apply universally. The model split is about planning-vs-execution capability, not about who has more room. In the recorded run, the observable boundary is delegation: the main session is an Opus session, while the policy says bounded execution work should move to Sonnet when that work is explicitly dispatched or configured for it. This is not a claim that the orchestrator silently switches models mid-conversation.
4. Augmenting CLAUDE.md: Sub-Agents and Models
With the why in place, here are the two new sections, appended after ## Workflow; everything above is unchanged from the previous rebuild’s:
## Sub-Agents
When the build has bulky, bounded sections (e.g., the full API surface), dispatch the work to a sub-agent rather than implementing inline. The orchestrator plans and integrates; the sub-agent executes.
## Models
Use Opus for planning, decomposition, and judgment calls. Use Sonnet for mechanical execution where the decisions have already been made.
This applies at explicit routing points. Keep planning, decomposition, and judgment with Opus. For bulky execution work whose decisions have already been made, use Sonnet when dispatching or configuring a separate execution agent.
End of beat: CLAUDE.md now has seven sections (Tech Stack, Layering, Testing Approach, Code Style, Workflow, Sub-Agents, Models). The file’s job stretches once more.
5. The Prompt
The prompt body is the previous rebuild’s verbatim, with two added dispatch lines: one at the top of ### API, one at the top of ### Tests. Each one says the same thing. Domain, Build, and Notes carry over unchanged; the orchestrator consults CLAUDE.md for everything else (when to dispatch, which model to use, the testing and code-style rules).
The two changed sections look like this:
### API
Run the work for this section in a sub-agent.
Expose REST endpoints for:
- Auth: register, login (returns a JWT).
- Users: list, change a user's role (admin only).
- Projects: create, list, add/remove members.
...
### Tests
Run the work for this section in a sub-agent.
Cover the meaningful flows — auth, the task workflow (including invalid transitions),
role-restricted close/reopen, comments on tasks, and audit log readouts.
Both sections are terminal in the dependency graph, and both are bulky enough that dispatching them moves the context-usage needle. I save CLAUDE.md to disk, then send the prompt.
6. Running the Coding Session
The orchestrator (Opus) reads the prompt and CLAUDE.md, plans the build end-to-end, then handles the foundation work inline: entities, repositories, the core service graph, security configuration. Those pieces define the shape the rest of the build depends on, so they stay with the orchestrator. The plan is in place, the decisions are made, and the bulky execution work can now move out to sub-agents.
Then the orchestrator hits the ### API section and dispatches. A sub-agent picks up the section’s flow list (auth, users, projects, sprints, tasks, comments, audit) and generates the controllers and DTOs in its own context window. The orchestrator’s window sees the result, not the line-by-line generation, so the bulky API generation never enters the main agent context at all. The dispatched sub-agent inherits CLAUDE.md automatically, so it already knows the layering rules, the code style, the workflow rules, and the dispatch and model rules, with no per-section re-briefing needed in the orchestrator’s window. The explicit brief is just the API section’s content from the prompt.
The orchestrator integrates the API surface and runs the verification beats. mvn -q clean compile finishes clean. mvn spring-boot:run boots the service:
Started JiraLiteApplication in 2.177 seconds
Then the second dispatch. The ### Tests section sends a second sub-agent against the now-existing API surface; it generates four integration test classes and twenty-seven tests covering auth, the task workflow, comments and audit, and the new user-role mutation endpoint, all going through TestHelper.registerAndLogin as the unified fixture path. The orchestrator doesn’t re-pass the API surface line by line; the sub-agent reads the source files directly. Same CLAUDE.md auto-inheritance, same per-section brief from the prompt.
The verification beats land:
Tests run: 27, Failures: 0, Errors: 0, Skipped: 0
You have 0 Checkstyle violations.
No suppressions, no rule relaxation in git history.
The recorded run also shows cleaner code: zero violations without the kind of rule relaxation the previous rebuild reached for. Five new helper classes have been cleanly extracted alongside the core services (RoleChecker, TaskMapper, TaskServiceDeps, TaskTransitionValidator, CurrentUserService), bringing every class under un-relaxed caps; TaskService dropped from 173 lines in the previous rebuild to 134 lines, delegating to those bounded helpers. Constructor injection has been adopted across the board without prompt; @Autowired on a field appears nowhere in production code. The previous rebuild’s FIELD_* string-constant ceremony in TaskService is gone. The cleaner code is a side effect of the model split, but worth naming so the planning pass leaves a visible footprint on the page.
The previous rebuild was Sonnet-monolithic; this one ran the main session in Opus and dispatched the bulky execution work twice. The verification surfaces close exactly where they did before (tests green, Checkstyle clean), with the architecture sitting noticeably tighter underneath.
7. Token Usage at the End of the Session
One observation from the end of the run is the clearest evidence that the levers above did what they were supposed to.
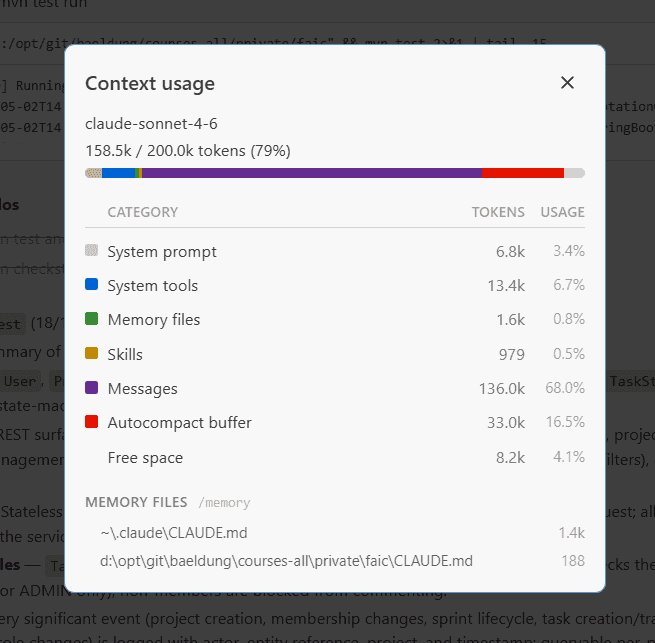
Here’s the main agent context from our previous run:
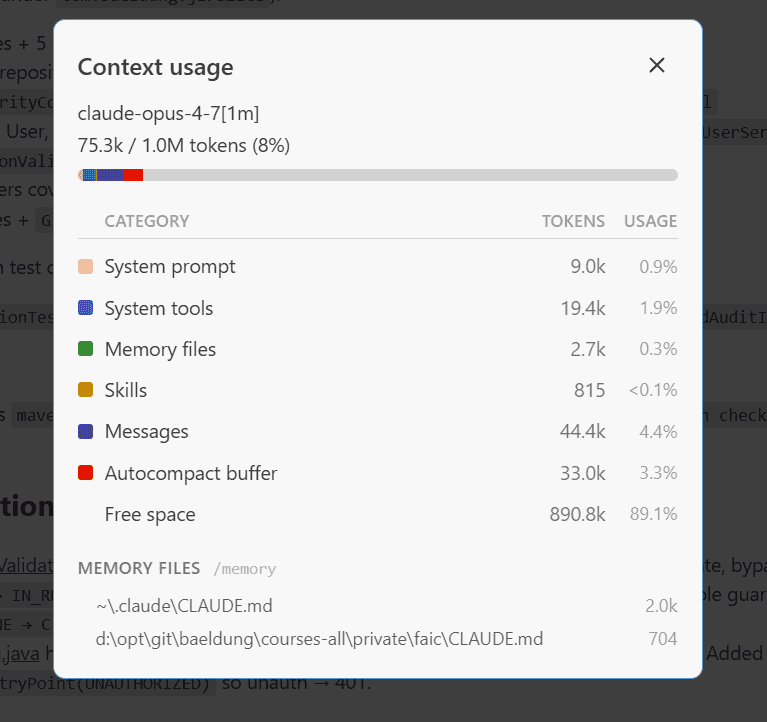
And here’s where we are now:
The previous rebuild ran without dispatch; the main agent context was the whole story, and it ended at 158.5k tokens.
This rebuild dispatched twice; the orchestrator carried only the integration spine, and the two sub-agents did the API and test generation in their own windows. Only their summaries landed back in the main context, which ended at 75.3k tokens.
A note on those numbers. The session ran on Opus’s 1M window, so 75.3k is a small fraction of the available room. But per the §3 framing, quality decays gradually as the window fills, so the right move is to keep the main agent context lean regardless of how much room the model nominally has. This rebuild’s headroom isn’t “Opus has room”; it’s “dispatch kept the bulky work out of the main agent context entirely.”
The levers above are the toolbox that produced this drop. None of them is novel on its own; the move is using them together as a deliberate budget against context decay.
8. Compaction: One More Tool in the Toolbox
The toolbox has one more tool worth naming, even though this rebuild didn’t lean on it: /compact. Run inside a Claude Code session, it summarizes the prior conversation in place, freeing window space without losing the thread of what we’ve been doing.
It earns its place in sessions that need to keep going past the natural turn-by-turn boundary: long debugging arcs, multi-pass refactors that need to keep iterating after the per-conversation window’s natural limit. This rebuild finished at 75.3k tokens with plenty of headroom, so we never reached for it; reaching for it on a session like this one would summarize working context away that we’re still using. The reader should still know it exists for the cases where it will matter.
9. Conclusion
Context is a finite resource, and these are some of the tools we have at our disposal to controll it.
The developer’s role is designing the system the agent operates inside. This rebuild applies that thesis to context: not a single trick, a small toolbox of levers used together, and a CLAUDE.md that’s grown organically but kept intentionally lean. The model split, the dispatch rule, and the workflow rules are durable across every subsequent build on this project.
The next rebuild moves the variable again. Where this one manages the agent’s working context, the next layer adds specifications the agent reads alongside the prompt: a written spec, in-repo, that the system around the agent can lean on in the same way it now leans on CLAUDE.md and the verification surfaces. Same rebuild discipline, one more layer joining.