1. Introduction
In this tutorial, we’ll explore the basic concepts of concurrency and how different programming languages address them, particularly Java and Kotlin.
We’ll focus primarily on the light-weight concurrency models and compare coroutines in Kotlin with the upcoming proposals in Java as part of Project Loom.
2. Basics of Concurrency
Concurrency is the ability to decompose a program into components that are order-independent or partially ordered. The objective here is to have multiple independent processes working together without affecting the outcome.
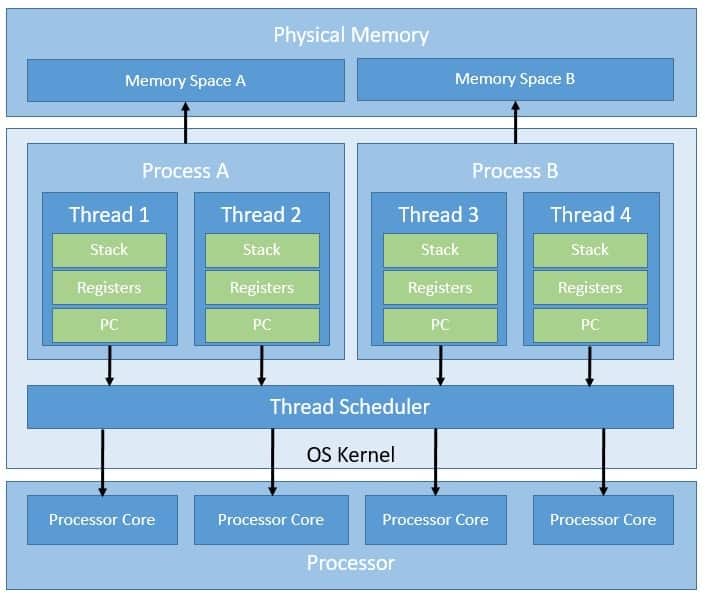
Within the operating system kernel, we refer to an instance of a program as a process. The kernel isolates processes by assigning them different address spaces for security and fault tolerance. Since each process has its own address space, open file handles, etc., they are quite expensive to create.
Moreover, since processes cannot access each other’s memory, inter-process communication becomes non-trivial.
This is where kernel-level threads bring relief for concurrent programming:
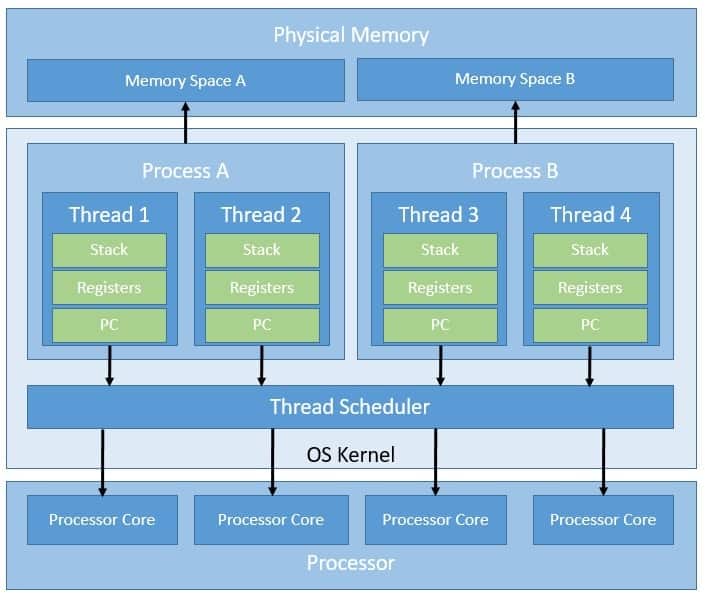
Threads are separate lines of execution within a process. A process can typically have multiple threads. While threads share the same file handles and address spaces, they maintain their own programming stacks. This makes inter-thread communication much easier.
The operating system kernel supports and manages the kernel-level threads directly. The kernel does provide system calls to create and manage these threads from outside. However, the kernel has full control of these threads, including their scheduling. This makes kernel-level threads slow and inefficient, resulting in costly thread operations.
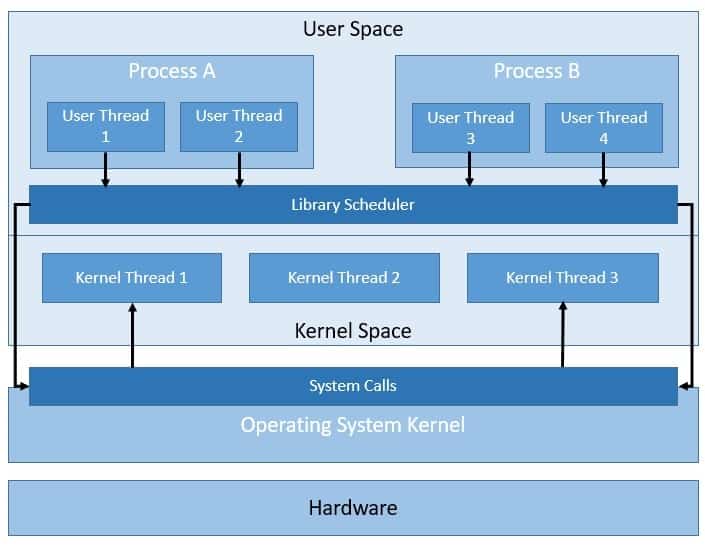
On the other hand, we also have user-level threads that are supported in the user-space, part of the system memory allocated to the running applications:
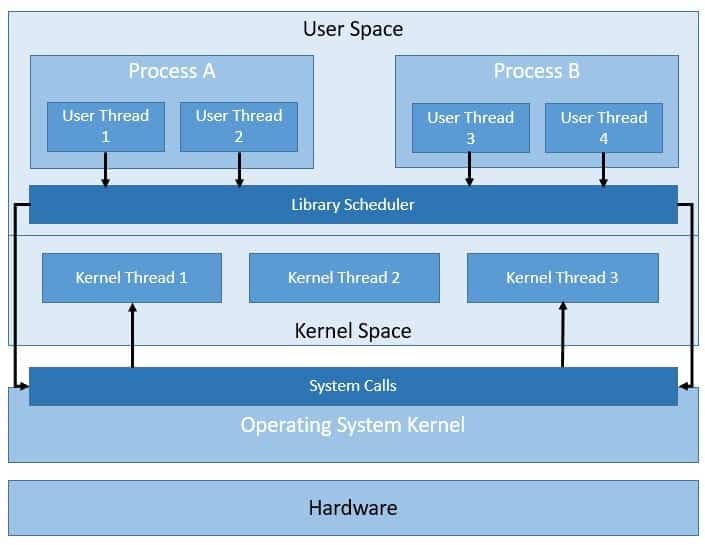
There are various models that map user-level threads to kernel-level threads like one-to-one or many-to-one. But a runtime system like a virtual machine directly manages user-level threads.
The kernel isn’t aware of user-level threads. Hence thread operations on user-level threads are much faster. Of course, this requires coordination between the user-level thread scheduler and the kernel.
3. Concurrency in Programming Languages
We discussed broadly the concurrency primitives that the operating systems provide us. But, how do concurrency abstractions available in different programming languages make use of them? While a detailed analysis is beyond this tutorial’s scope, we’ll discuss some of the popular patterns here.
Most modern programming languages support concurrent programming and provide one or more primitives to work with. For instance, Java has the first-class support for concurrency through an abstraction called the Thread class. This provides a system-independent definition for a thread in Java. However, under-the-hood, Java maps every thread to the kernel level thread through system calls.
As we’ve already seen, while kernel threads are easier to program with, they are quite bulky and inefficient. The alternative, in fact, is to use the user-level threads. Many programming languages support the concept of light-weight threads natively, while there are several external libraries to enable this as well.
The fundamental approach is to handle the scheduling of these light-weight threads within the execution environment. The scheduling here is cooperative rather than preemptive, which makes it much more efficient. Also, as we manage these threads in the user-space, we can multiplex them on just a few kernel threads, reducing the kernel threads’ overall cost.
Different programming languages have different names for them. For instance, we have coroutines in Kotlin, goroutines in Golang, processes in Erlang, and threads in Haskell, to name a few. Although there’s no native support for them in Java, this is in the active proposal under Project Loom. We’ll examine some of them later in this tutorial.
4. Additional Approaches Towards Concurrency
The concurrency models discussed so far have a commonality that we can mostly reason about the program’s flow in a synchronous manner. Even though they provide asynchronicity, fundamental primitives like threads, or coroutines, abstract it mostly.
However, with more explicit asynchronous programming, we break this abstraction and allow parts of the program to run arbitrarily.
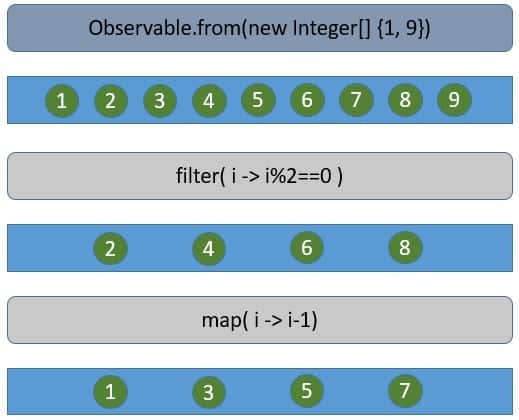
For instance, reactive programming sees concurrency with a completely different perspective. It transforms the program flow as a sequence of events that occur asynchronously. Hence, the program code becomes functions that listen to these asynchronous events, process them, and, if necessary, publish new events.
We often depict these graphically as marble diagrams:
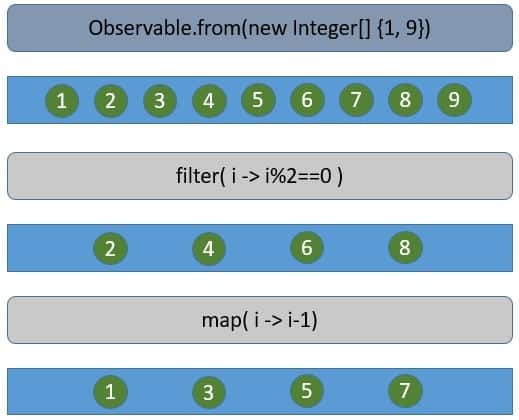
More importantly, the thread on which we publish or subscribe to these events is actually not significant in reactive programming. The reactor core process uses a limited number of threads, typically matching the available CPU cores. It executes a function on a free thread from the pool and releases it back.
So, if we can avoid using any blocking code, it can result in a program that executes much more efficiently, even on a single thread. Also, it addresses some of the pain points like call-back hell typically associated with other asynchronous programming styles.
However, it increases the level of difficulty in reading and writing the program, making it difficult to test and maintain.
5. A Case for Structured Concurrency
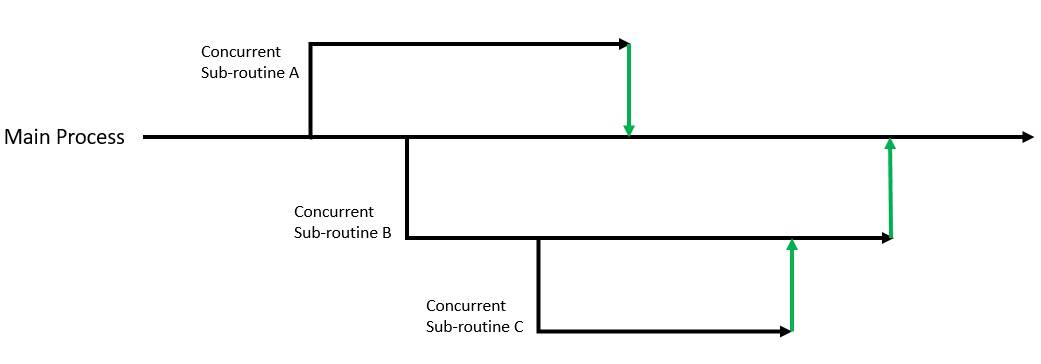
A typical concurrent application with more than one execution path is difficult to reason about. Part of the problem is that it lacks abstraction. For instance, if we call a function in such an application, we can’t guarantee that processing has terminated when the faction terminates. This is because the function may have spawned multiple concurrent execution paths, of which we’re completely unaware.
A sequential flow of the program is much easier to read and write. Of course, to support concurrency, this flow needs to branch out. But, it’s much simpler to comprehend if all the branches terminate back into the main flow:
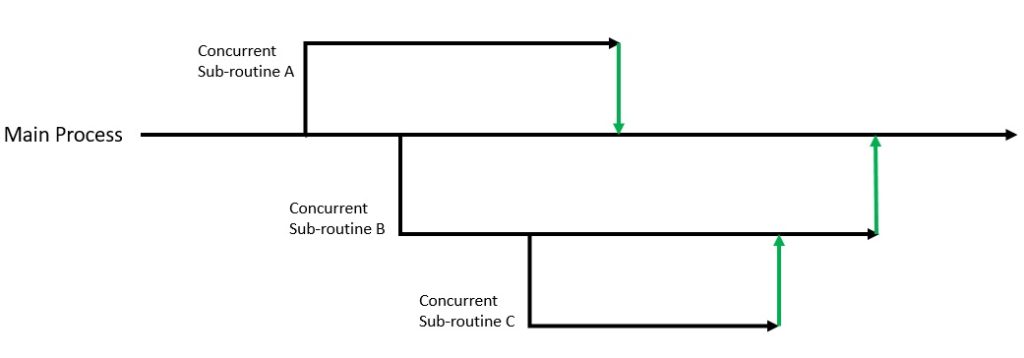
So, maintaining the abstraction, we don’t really care how the function internally decomposes the program. It’s all fine, so far, as all lines of execution terminate with the function. Alternatively, the scopes of concurrent executions are cleanly nested. This is the fundamental premise of structured concurrency. It emphasizes that if control splits into concurrent tasks, they must join up again.
If we see some of the asynchronous programming models like reactive programming, we’ll understand that it’s difficult to achieve structured concurrency. In fact, concurrent programming has mostly involved arbitrary jumps, even with simpler primitives like threads.
However, we can achieve structured concurrency in Kotlin with a solution like coroutines.
We’ll see how, later in this tutorial.
6. Kotlin: How Do They Do It?
Now we’ve gathered enough background to examine how Kotlin solves the problem of concurrency while keeping most of the issues at bay. Kotlin is an open-source programming language that was started by JetBrains back in 2010. Kotlin targets the JVM along with other platforms like JavaScript, and even Native. Hence, it can produce Java-compatible bytecode.
Kotlin provides the support for light-weight threads in the form of coroutines, which are implemented as a rich library —kotlinx.coroutines. Interestingly, the JVM does not have native support for a light-weight concurrency construct like coroutine — well, at least yet! Nonetheless, Kotlin introduced coroutines as an experimental language feature quite early, and they became official in version 1.3.
We’ll see how Kotlin implements coroutines and how we can use them to write concurrent applications with the benefits of structured concurrency.
6.1. What Exactly Is a Coroutine?
Generally speaking, coroutines are parts of a computer program or generalized subroutines that can suspend and resume their execution at any point. It first appeared as a method in assembly languages way back in the 1950s. Coroutines can have several interesting applications.
When we use them for concurrency, they appear to be similar to kernel threads. However, there are subtle differences. For instance, a scheduler manages kernel threads preemptively, while coroutines voluntarily yield control, resulting in cooperative multitasking.
Let’s see a general construction of coroutines:
coroutine
loop
while <em>some_condition</em>
<em>some_action</em>
yield
Here, as we can see, we have a coroutine that performs some action in a loop but cooperatively yields the control on every step instead of blocking. This can help to utilize underlying kernel threads much more efficiently. This is exactly what other asynchronous programming styles like reactive programming do, but without the complexities.
While a coroutine can choose to yield to a specific coroutine, there can also be a controller that schedules multiple coroutines. More interestingly, we can multiplex thousands of coroutines on just a single underlying kernel thread.
But consequently, coroutines don’t necessarily provide parallelism, even on a multi-core system.
6.2. Kotlin Coroutine in Action
Kotlin provides many coroutine builders to create a coroutine, like launch, async, and runBlocking. Further, coroutines in Kotlin are always bound to a coroutine scope. The coroutine scope contains the coroutine context and sets the new coroutine scope that is launched by a coroutine builder.
We’ll see shortly how to launch a coroutine, but let’s first understand suspending functions. Kotlin provides a special keyword called suspend to mark such functions. This allows the compiler to sprinkle some magic into these functions, which we’ll see later.
Let’s create a suspending function:
suspend fun doSomething() {
// heavy computation here
}
Barring the use of this keyword, we can see that these are just regular functions. However, there is an important limitation: Suspending functions can only be invoked from within a coroutine or from another suspending function.
So, let’s use one of the coroutine builders to launch a coroutine and call our simple but suspending function:
GlobalScope.launch {
doSomething() // does some heavy computation in the background
... do other stuff
}
Here, we’re starting a new coroutine with the launch coroutine builder.
6.3. Structured Concurrency with Coroutines
Now, we should avoid launching a coroutine bound to the GlobalScope, unless intended for the right reasons. This is because such coroutines operate on the whole application lifecycle and, more importantly, deviate from the principles of structured concurrency.
To adhere to structured concurrency, we should rather create an application-specific CoroutineScope and use coroutine builder on its instance:
var job = Job()
val coroutineScope = CoroutineScope(Dispatchers.Main + job)
coroutineScope.launch {
doSomething() // does some heavy computation in the background
... do other stuff
}
To create an instance of CoroutineScope, we have to define a Dispatcher, which controls which thread runs a coroutine. The Job here is responsible for the coroutine’s lifecycle, cancellation, and parent-child relations.
All the coroutines launched using this CoroutineScope can be simply canceled by canceling this parent Job. This prevents coroutines from leaking unintentionally. This also avoids having side-effects of launching coroutines from a suspending function. Hence, we achieve structured concurrency, which we’ve discussed before.
6.4. Looking Under the Hood
So, the question now is: How does Kotlin implement coroutines? Broadly speaking, coroutines are implemented in Kotlin as a finite state machine with suspension points and continuations. For those of us uninitiated in this area, this may not make any sense! But we’ll try to describe them briefly.
Let’s first understand some of the terms we’ve just introduced. A suspension point is a point in the suspending function at which we want to suspend our execution and resume later. At the same time, a continuation is actually the encapsulation of the state of a function at a suspension point. Basically, a continuation captures the rest of the execution after the suspension point.
Now Kotlin, upon compilation, transforms all suspending functions to add a parameter, which is the continuation object. The compiler will transform the signature of our suspending function from the previous section:
fun doSomething(continuation: Continuation): Any?
This programming style is typical of functional programming and is known as Continuation Passing Style (CPS). Here, the control is passed explicitly in the form of a continuation. This is somewhat similar to the asynchronous programming style where we pass a callback function to get notified. However, with coroutines in Kotlin, the compiler implicitly handles the continuations.
The Kotlin compiler identifies all possible suspension points in a suspending function and creates states with labels for everything delimited by the suspension points. The resulting continuation is nothing but a huge switch statement with these states as labels.
Hence, we can think of continuation as packing this as a finite state machine.
7. Java: What Is the Proposal?
Java has had first-class support for concurrency since the early days of its inception. However, Java does not have native support for what we know as light-weight threads. Although there have been several attempts to build such support outside the core Java, none of them could find enough success.
For the last couple of years, OpenJDK has been working on Project Loom to bridge this gap.
7.1. A Brief History of Concurrency in Java
Since JDK 1.0, the class Thread has provided a core abstraction for concurrency in Java. It was intended to run on all platforms alike, to match the promise “write once, run anywhere”. Unfortunately, some of the target platforms didn’t have native support for threads back then. Hence, Java had to implement something called green threads to deliver that promise.
Basically, green threads are the implementation of threads that are managed in the user-space and scheduled by the virtual machine. We’ve already seen such threads’ general definition and discussed how coroutines in Kotlin or goroutines in Golang and similar concepts. Although green threads may vary in terms of the implementation, the basic idea was actually quite similar.
In the initial days, Java struggled to refine the implementation of green threads. It was difficult to scale green threads over multiple processors and hence benefit from parallelism on multi-core systems. To get around this problem and simplify the concurrent programming model, Java decided to abandon green threads in version 1.3.
So, Java decided to map every thread to a separate native kernel thread. Essentially the JVM threads became a thin wrapper around the operating system threads. This simplified the programming model, and Java could leverage the benefits of parallelism with preemptive scheduling of threads by the kernel across multiple cores.
7.2. Problems with the Java Concurrency Model
The concurrency model in Java was actually quite easy to use and has been improved substantially with the introduction of ExecutorService and CompletableFuture. This also worked well for a large period of time. However, the problem is how concurrent applications that were written with this model have to face an unprecedented scale today.
For instance, typical servlet containers are written in the thread-per-request model. But, it’s impossible to create as many threads on a system as the number of concurrent requests we expect them to handle. This calls for alternate programming models like event-loop or reactive programming that are inherently non-blocking, but they have their own share of issues.
7.3. Proposals of Project Loom
By now, it should not be difficult for us to guess that perhaps it’s time for Java to bring back the support for light-weight threads. This is actually the motivation behind Project Loom. The purpose of this project is to explore and incubate a light-weight concurrency model on the Java platform. The idea is to build support for light-weight threads on top of the JVM threads and fundamentally decouple the JVM threads from the native kernel threads.
The current proposal is to introduce support for some core concurrency related constructs right at the level of JVM. These include virtual threads (previously called fibers), delimited continuation, and tail-call elimination. The current construct of the thread is basically a composition of continuation and scheduler. The idea is to separate these concerns and support virtual threads on top of these building blocks.
As the current JVM thread is just a wrapper over the underlying kernel thread, it relies on the kernel to provide the implementation for both continuation and scheduler. However, by exposing continuation as a construct within the Java platform, it’s possible to combine it with a global scheduler. This gives rise to virtual threads as light-weight threads managed entirely within the JVM.
Of course, the idea behind Project Loom is not just to provide a construct like the virtual thread in Java but also to address some of the other issues that arise due to them. For instance, a flexible mechanism to pass data among a large number of virtual threads. A more intuitive way to organize and supervise so many virtual threads, a concept close to structured concurrency. Or managing context-data for so many virtual threads, similar to what we have as thread-local for current threads.
7.4. Understanding Continuations
Let’s understand what we actually mean by delimited continuations in the scope of Project Loom. Actually, the basic idea behind a delimited continuation is nothing different from a coroutine that we’ve already discussed before. Hence, we can see a delimited continuation as a sequential code that can suspend its execution at any point and resume again from the same point.
In Java, however, the proposal is to expose continuations as a public API. The proposed API may look like the following:
class _Continuation {
public _Continuation(_Scope scope, Runnable target)
public boolean run()
public static _Continuation suspend(_Scope scope, Consumer<_Continuation> ccc)
public ? getStackTrace()
}
Please note that continuation is a general construct and has nothing specific to virtual threads. Although virtual threads require continuations for implementation, there are other possible uses of continuations as well. For instance, we can use it to implement a generator, which is an iterator that yields after producing a single value.
7.5. Implementation of Virtual Threads
The focus of Project Loom is to provide support for virtual threads as a basic construct. Virtual threads are the higher-level construct that is proposed to provide the capabilities of user-mode threads in Java. Basically, virtual threads should allow us to run an arbitrary code concurrently with the ability to suspend and resume execution.
As we can already guess, continuations will be used to create higher-level constructs like virtual threads. The idea is that the virtual thread will hold a private instance of the continuation class along with other necessary parts:
class _VirtualThread {
private final _Continuation continuation;
private final Executor scheduler;
private volatile State state;
private final Runnable task;
private enum State { NEW, LEASED, RUNNABLE, PAUSED, DONE; }
public _VirtualThread(Runnable target, Executor scheduler) {
.....
}
public void start() {
.....
}
public static void park() {
_Continuation.suspend(_FIBER_SCOPE, null);
}
public void unpark() {
.....
}
}
Above is a simple representation of how we can compose a virtual thread with low-level primitive, like continuations. Also, note that schedulers are an essential part of implementing the virtual thread. However, the initial default global scheduler for virtual threads will be the ForkJoinPool that already exists in Java and implements a work-stealing algorithm.
More importantly, the proposal is to keep the API of virtual threads very close to that of the current heavy-weight threads. The heavy-weight thread as it exists today will continue to exist. So the conformity of the API that heavy-weight or the new light-weight threads support will lead to a better user experience.
7.6. A Sneak Peek into the Current State
Project Loom has been in progress for a couple of years now, and some parts of the proposal may be available as part of Java 16 in 2021. However, early-access builds are available for some time to experiment with the new features and provide feedback.
So, first, let’s see how working with heavy-weight threads, or the threads as we know them currently, will change:
Runnable printThread = () -> System.out.println(Thread.currentThread());
ThreadFactory kernelThreadFactory = Thread.builder().factory();
Thread kernelThread = kernelThreadFactory.newThread(printThread);
kernelThread.start();
As we can see, we have a new interface called Thread.Builder, which is a mutable builder for Thread or ThreadFactory. This is to facilitate creating a kernel thread, as we’re doing here, or a virtual thread. Everything else is quite similar to what exists today.
So, let’s see how to create and use a virtual thread instead:
Runnable printThread = () -> System.out.println(Thread.currentThread());
ThreadFactory virtualThreadFactory = Thread.builder().virtual().factory();
Thread virtualThread = virtualThreadFactory.newThread(printThread);
virtualThread.start();
Apart from the fact that there’s a different thread factory to create virtual threads, there is actually no difference! This is because the current implementation of virtual threads does not introduce a new class but just a new implementation of the Thread class.
Apart from the fact that this new implementation of Thread differs in scheduling, there are other aspects that will not work the same for them. For instance, the behavior and implications of some of the existing constructs like ThreadGroup and ThreadLocal will be different for the virtual threads.
8. How Are Java Virtual Threads Different from Kotlin Coroutines?
We’ve discussed in detail the support for the light-weight concurrency model that Kotlin has in terms of coroutines and the model Java is proposing to bring as virtual threads.
The obvious question is, how do they compare against each other, and is it possible to benefit from both of them when they target the same JVM. In this section, we’ll explore some of the important aspects like continuations and scheduling.
8.1. Stackful vs. Stackless Continuations
Since continuations form the basis of any form of user-mode thread implementation, let’s begin by examining their implementation in Kotlin and how they are different from the proposal in Java. Broadly speaking about the design choice, Kotlin coroutines are stackless, whereas continuations in Java are proposed to be stackful.
As the name suggests, stackful continuations or coroutines maintain their own function call stack. A stack here is a contiguous block of memory that is needed to store the local variables and the function arguments. On the contrary, stackless coroutines do not maintain their stack and rely on the caller. This makes them strongly connected to the caller.
As an immediate fallout, stackless coroutines can suspend themselves only from the top-level function. So, all functions called from the coroutine must finish before suspending the coroutine. In comparison, a stackful continuation or coroutine can suspend at any nested depth of the call stack. So, stackful coroutines are more powerful and general-purpose than stackless coroutines.
However, since stackless coroutines have a lower memory footprint than stackful coroutines, they prove to be more efficient. This is because context switching between stackless coroutines comes out to be less expensive. Moreover, the compiler locally handles the code transformations for stackless coroutines with very little support from the runtime.
8.2. Preemptive vs. Cooperative Scheduling
Apart from continuations, another important part of the implementation of a light-weight thread is scheduling. We’ve seen how the operating system scheduler schedules the kernel threads preemptively. This is, in fact, one of the reasons why kernel threads prove to be inefficient. So, typically, the approach for scheduling light-weight threads is more structured than arbitrary.
As we’ve seen earlier, the scheduling in Kotlin coroutines is cooperative where coroutines voluntarily yield the control at logical points. For instance, we can decide to wrap a computationally heavy or blocking operation in a suspending function. When we call such functions from a coroutine or another suspending function, these become natural suspension points.
However, the current proposal in Java is to keep the scheduling preemptive rather than cooperative. Hence, it’s not possible to define suspension points in Java virtual threads. So, does that mean it will carry the burden of kernel scheduler? Not really. Note that the kernel threads are preempted arbitrarily, based on the notion of time-slice.
However, the proposal for virtual thread scheduler in Java is to preempt them when they block on I/O or synchronization.
Regardless of how they’re scheduled, light-weight threads are finally executed on the underlying kernel threads. In the case of Kotlin coroutines, coroutine context includes a coroutine dispatcher. The coroutine dispatcher decides which kernel thread the coroutine uses for its execution.
On the other hand, the Java virtual thread scheduler maintains a pool of kernel threads as workers and mounts a runnable virtual thread on one of the available workers.
9. Conclusion
In this tutorial, we understood the basic concepts of concurrency and how light-weight concurrency differs from heavy-weight concurrency. We also touched upon how concurrency is generally approached in programming languages and what we mean by structured concurrency.
Further, we understood how light-weight concurrency is supported in Kotlin as coroutines and how Java is proposing to introduce virtual threads in that regard. We discussed these constructs in some detail and then touched upon how their implementations differ from each other.