

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: August 30, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this article, we’ll explore the key differences between the Collection and Sequence APIs with examples of when to use one over the other.
We heavily use collection operations on a daily basis. At first glance, the APIs for Collection and Sequence look the same. The key difference between both implementations lies in when each transformation on the Collection or Sequence is performed.
Collections are eagerly evaluated — each operation is performed on every item in the collection and the result of the operation is stored in a new collection:
(1..100)
.map { it * it } // Create a new list [1,4,9,16...10000]
.filter { it % 2 == 0 } // Create a new list [4,16,...10000]
.first { it > 50 } // Break loop when 64 > 50 is found
public inline fun <T> Iterable<T>.filter(predicate: (T) -> Boolean): List<T> {
return filterTo(ArrayList<T>(), predicate)
}
This implementation applies to all the other operations like map(), filter(), flatMap(), reduce(), and fold().
Sequences are lazily evaluated — each operation is evaluated on demand. It does not create any intermediate new list on each operation. It emits one item at a time, passing it down and matching each item in the operation chain.
Let’s iterate over 100 items and find a number whose square is even number greater than 50:
(1..100).asSequence()
.map { it * it }
.filter{ it % 2 == 0 }
.first{ it > 50 }
During the iteration, the chain of operations is applied to each item in the sequence one by one.
When the iteration starts, the map() operation squares it and passes its result to filter(). If the filter() condition is true, it will pass the result to the first() operation, otherwise, it will skip the first() operation. For example, 1, 9, 25, and 49 are not passed down to first() because they fail the filter() condition.
We keep iterating until we find a number that goes down to the last chain and returns true.
When all conditions are met, we break the loop and stop evaluating further items. In the above example, we only evaluated eight items [ 1, 2, 3, 4, 5, 6, 7, 8 ] and saved ourselves from 92 x 2 additional iterations from the map() and filter().
To get a clear picture of sequence’s lazy evaluation behavior, let’s add some log output to each step in the code:
(1..100).asSequence()
.map {
print("\nTaking: $it")
(it * it).also { print(" -> Square: $it") }
}
.filter { (it.also { print(" -> Even-Filtering: $it") } % 2 == 0) }
.first { it.also { print(" -> Comparing $it to 50") } > 50 }
.also { println(" -> Found: $it") }
Now, if we rerun the code, we’ll see how sequence picked the elements and how operations are evaluated through the output:
Taking: 1 -> Square: 1 -> Even-Filtering: 1
Taking: 2 -> Square: 4 -> Even-Filtering: 4 -> Comparing 4 to 50
Taking: 3 -> Square: 9 -> Even-Filtering: 9
Taking: 4 -> Square: 16 -> Even-Filtering: 16 -> Comparing 16 to 50
Taking: 5 -> Square: 25 -> Even-Filtering: 25
Taking: 6 -> Square: 36 -> Even-Filtering: 36 -> Comparing 36 to 50
Taking: 7 -> Square: 49 -> Even-Filtering: 49
Taking: 8 -> Square: 64 -> Even-Filtering: 64 -> Comparing 64 to 50 -> Found: 64
Under the hood, Sequence<T> uses an Iterator to break the loop early:
public interface Sequence<out T> {
public operator fun iterator(): Iterator<T>
}
Each operation in the sequence has its own implementation, such as TransformingSequence or FilteringSequence. It does not create any new ArrayList<T> as we saw in the collections example:
public fun <T> Sequence<T>.filter(predicate: (T) -> Boolean): Sequence<T> {
return FilteringSequence(this, true, predicate)
}The sequence chain wraps all of these implementations on top of each other based on the operation chain we define:
(1..100).asSequence()
.map { it * it } //TransformingSequence
.filter { it % 2 == 0 } //FilteringSequence
.first { it > 50 }
If we look at how a sequence like TransformingSequence is implemented, we’ll see that when next() is called on the sequence iterator, the stored transformation is also applied. It does not create a new list:
public fun <T, R> Sequence<T>.map(transform: (T) -> R): Sequence<R> {
return TransformingSequence(this, transform)
}
override fun iterator(): Iterator<R> = object : Iterator<R> {
val iterator = sequence.iterator()
override fun next(): R {
return transformer(iterator.next())
}
override fun hasNext(): Boolean {
return iterator.hasNext()
}
}
Let’s explore the differences in functional usage between these APIs.
If any operation returns a List<T>, then it is a Collection and evaluates all the operations eagerly:
public fun <T> listOf(vararg elements: T): List<T>
If any operation returns a Sequence<T>, then it is a Sequence and evaluates all the operations lazily:
public fun <T> sequenceOf(vararg elements: T): Sequence<T>
The Kotlin standard library provides numerous extension functions for the Iterable<T> class:
listOf(1, 2, 3, 4, 5, 6)
.map { it * it } // [4, 16, 36]
.filter { it % 2 == 0 } // [2, 4, 6]
These operations provide a declarative and concise way of transforming data without having to use loops or mutable states.
Some of the commonly used operations include map(), filter(), flatMap(), reduce(), and fold(). For additional operators, please refer to the standard library documentation.
Sequence<T> has two types of operations: intermediate and terminal.
Intermediate operations are not performed immediately; they are just stored. They’re only executed when a terminal operation such as toList() or toSet() is called.
The intermediate operations are applied to each element in the Sequence in turn, and finally, the terminal operation is executed:
val evens = sequenceOf(1, 2, 3, 4, 5)
.filter { it % 2 == 0 }
.map { it * it }
.toList() // [4, 16]
evens.onEach {
print(it)
}
If we remove the toList() terminal operation at the end, then onEach() won’t print anything because a Sequence needs a terminal operation in order to run the iteration.
Performance can influence our decision to prefer one over the other. Let’s go over some key differences.
In a Collection, when the chain becomes more complex, it incurs a performance penalty by creating a new list with each operation. If the functional pipeline is performed on a large dataset, it will slow down.
Kotlin lint suggests converting the existing Collection into a Sequence if chaining becomes more complex on the collection. We can demonstrate that lint by creating a large collection with several rounds of filtering:
val result = (1..100_000_000)
.map { it * it }
.filter { it % 2 == 0 }
.filter { it % 4 == 0 }
.filter { it % 6 == 0 }
.filter { it % 8 == 0 }
.filter { it % 9 == 0 }
.first { it > 50 }
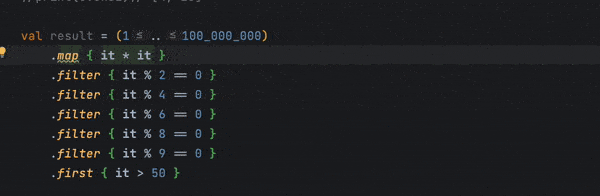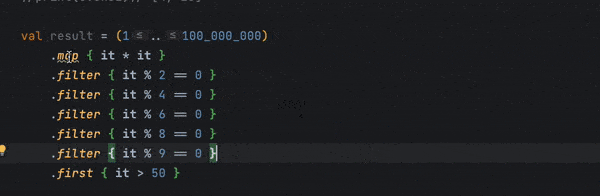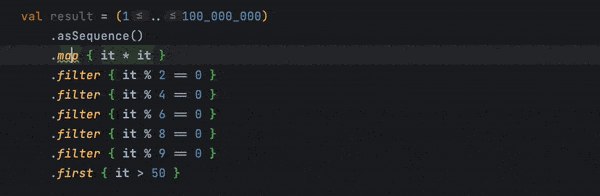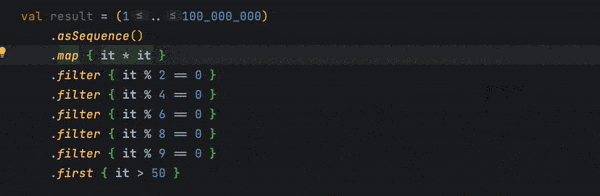
A Sequence, on the other hand, is designed to fix performance issues. Since it evaluates things based on demand, it’s more efficient when dealing with large datasets with complex chain structures.
Independent of whether we’re using collections or sequences, the order of transformations matters. Let’s say we want to square all the even items in the list:
(1..100)
.onEach { println(it) } // Print 100 items
.filter { it % 2 == 0 } // Filter 100 items
In the above order, the onEach() iterates through 100 items, and then filter() iterates through 100 items. If we reverse the order of our business logic and call filter() and then print the result in onEach(), we only print 50 items, resulting in a 50% onEach() reduction:
(1..100)
.filter { it % 2 == 0 } // Filter 100 items
.onEach { println(it) } // Print 50 items
Sequences are particularly useful on large datasets when performing complex, multi-step transformations, as they allow for the chaining of operations without the need for intermediate Collections.
However, for small datasets, Collections work well without a noticeable performance penalty. In that case, the overhead of setting up and processing sequences may not be worth it.