

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
API Authentication – Tokens vs Sessions
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
Whenever we write a new HTTP API, we have several decisions to make: URL patterns, resource structures, etc. One important decision is how clients can authenticate with us to access our API.
In this tutorial, we’re going to look at a few alternatives along with their pros and cons.
2. Traditional Authentication
The HTTP specification offers some simple means to authenticate requests. These are known as Basic and Digest authentication.
Basic authentication works by combining the username and password with a “:” separator, and then base64 encoding the resulting string. This is then provided in the Authorization header with a “Basic” scheme. For example, for the username “baeldung” and password “superSecret:”
- Combine the two into “baeldung:superSecret”
- Base64 encode this string into “YmFlbGR1bmc6c3VwZXJTZWNyZXQ=”
- Provide this in an HTTP header of “Authorization: Basic YmFlbGR1bmc6c3VwZXJTZWNyZXQ=”
The HTTP server can then easily convert this back into the original username and password to verify that they are correct. However, this has security implications. The password is provided on every request, so it can easily be intercepted.
Digest authentication improves upon this by generating a cryptographic digest of the username, password, and other details. This information is then sent to the server along with the username and other details. The server can look up the password, generate the same digest, and compare them.
This is advantageous because the password is not sent over the network in any form, and instead requires that the server generate the same digest, which means it needs access to the same details. Consequently, the password must be available in plaintext to our server.
Both of these mechanisms also require that the user is authenticated on every request. This involves looking up the user details and validating the password on every request. This can potentially be expensive, especially if it needs to refer to a remote service to get the user details:
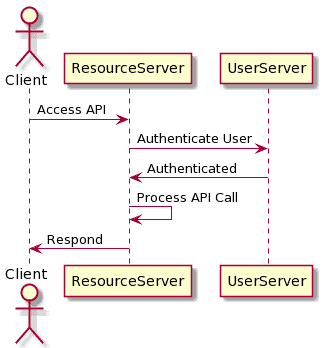
3. Token-Based Authentication
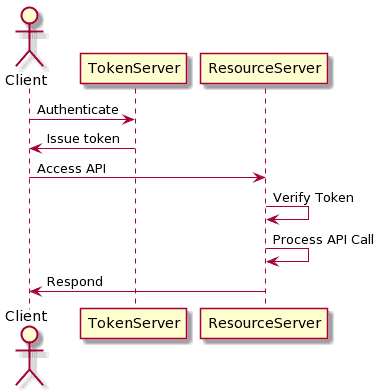
One alternative is to authenticate the client once, and in doing so provide them with a special token that proves they have authenticated. This is known as an “access token,” and it’s something that the server can use to prove who the user is without needing to go through the full process of authenticating.
Token-based authentication requires special infrastructure that can generate a token for an authenticated user, and a means to ensure that a token is valid. However, this allows the user authentication to be decoupled from the rest of the service and means that future API calls only provide this token and not the user’s actual credentials. This is what specifications like OAuth2 and OpenID Connect give us. They describe various means to obtain a token for use on future API calls.
The exact form the token takes will depend on our exact needs. We can use simple values and then look them up in a database to see what they represent. We can also use some self-contained format such as JWT, which means that we only need to verify they are valid.
For security purposes, tokens must not be leaked or shared. However, there is the ability to make them short-lived so that any breach is easily contained. Specifications such as OAuth2 have ways to request a new token periodically, allowing that the access token is routinely rotated.
It is also important that tokens can’t be guessed or generated by attackers. Using formats such as JWTs means that every generated token is guaranteed to be unique and proven to have been generated by the authentication server. Other services can verify that the token was generated correctly using asynchronous cryptographic signatures, or by using a shared signing key:
This is beneficial because we can use the same token to authenticate against multiple services. As long as each service is capable of verifying the token, then they will work correctly. This is useful for building distributed services that are not fronted by the same API gateway:
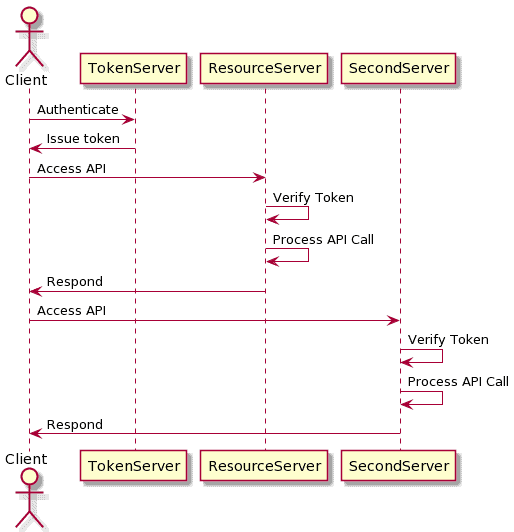
If simple IDs are used for tokens, then it’s important that they are generated in a non-deterministic way. If an incrementing number is used, then an attacker can try other numbers to see what happens. Using something such as a UUID will mean that attackers are much less likely to be able to predict valid tokens.
4. Session-Based Authentication
Another alternative is to make use of the session infrastructure available from many containers, e.g. Tomcat. Sessions act as a means to store simple pieces of data against a session ID, while the webapp container manages the storage of these and relates them to the session ID.
We can use this to implement authentication by storing the logged in user into the session. If a user is present in the session, then this is the user we are authenticated as. If there isn’t a user present, then we aren’t currently authenticated. We can store additional data into the session as needed, such as the user’s set of permissions or anything else that is potentially useful:
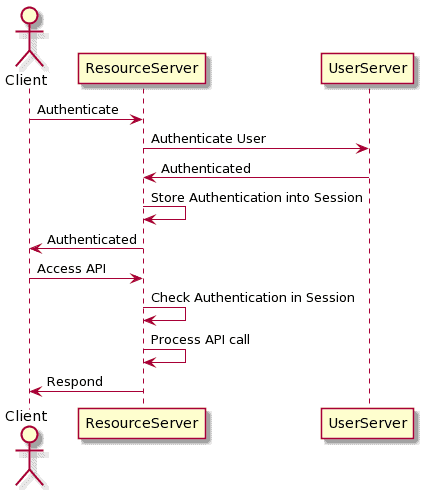
Typically these IDs are transmitted by cookies, or by injecting them into the URL. This is much more convenient since the container does a lot of the work for us. However, this is only the case when the application works within these bounds. For example, the injection of session IDs into URLs doesn’t work well in combination with API clients that are generating the URLs themselves.
The container will also handle the session’s entire lifecycle, including expiring it when it’s no longer needed. Often this is tied not to a specific point in time, but rather to a period of inactivity. This means that the user remains authenticated only for as long as they are actively using the system, and once they finish, the session will expire and they will no longer be authenticated.
There are complications though. Using sessions depends on access to the storage, requiring all calls from the same client to reach a single server or else configuring session replication between servers. Additionally, we need some way to handle logging out. Common ways to achieve this are to expire the entire session or to clear out the user details.
5. Summary
Deciding how to authenticate our APIs isn’t a trivial choice to make. There are several things to balance up: security implications, implementation cost, deployment cost, etc.
In general, token-based authentication is more typical, especially using frameworks such as OAuth2 or OpenID Connect. This means that third-party clients will find it easier to interact with us, as they can use tooling that already understands these concepts.
However, session-based authentication is likely easier for us to implement within a single service since it is usually a standard feature of application containers. This means that our API’s development cost is lower, but at a higher cost to the clients.