

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll learn about serverless architecture and how we can benefit from it. We will also explore some of the popular serverless platforms that we can use. In the process, we’ll also learn some of the benefits and limitations of this style of architecture.
Like many other buzzwords in the industry, it’s quite difficult to reliably track the source of origin for the word serverless. However, what is important is to appreciate the benefits it can bring to our application. Serverless architecture may sound very peculiar, to begin with, but it makes sense when we get to understand it better.
Typically when we develop an application, we require servers to host and serve them. For instance, when we develop a Java application bundled as a WAR file, we require an application container like Tomcat to run it on a host like a Linux machine possibly with virtualization. Then there are other considerations like provisioning the infrastructure with high availability and fault tolerance:
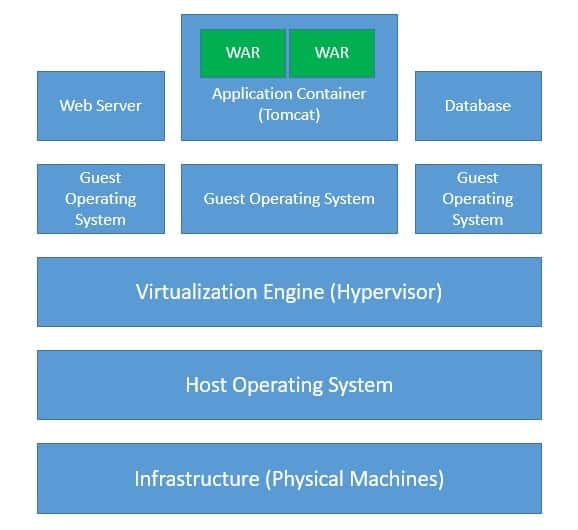
Of course, this implies that even before we are able to serve the first request, we’ve to go through a lot of preparations. And this does not stop there, as we’ve to manage this infrastructure from there on to keep it serviceable. What if we do not have to bother about all these tasks that are not strictly related to application development?
This is the fundamental premise of serverless. So basically, serverless architecture is a software design pattern where we host our applications on a third-party service. It eliminates the need for managing the hardware and software layers necessary to do so. Moreover, we do not even have to worry about scaling the infrastructure to match the load.
Within the industry, serverless is also often loosely known by the popular term function-as-a-service (FaaS). FaaS, as the name suggests is a cloud computing service that allows us to build, run and manage applications as functions without having to manage the infrastructure. But, is this not very similar to another construct called platform-as-a-service (PaaS)?
Well, fundamentally yes, but the difference lies in the deployment unit of the application. With PaaS, we develop the application traditionally and deploy the complete application, like a WAR file, and scale the whole application:
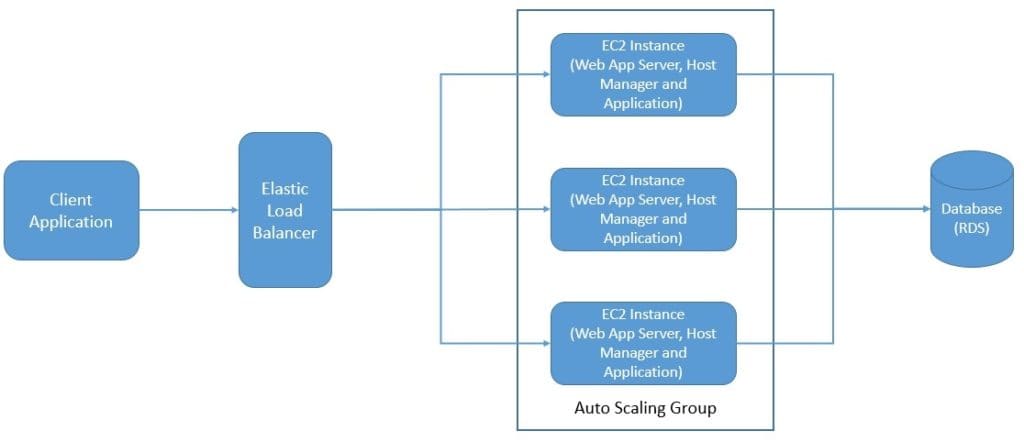
But, with FaaS, we decompose our application into individual and autonomous functions. Hence, we can deploy each function on a FaaS service independently with more precise scalability:
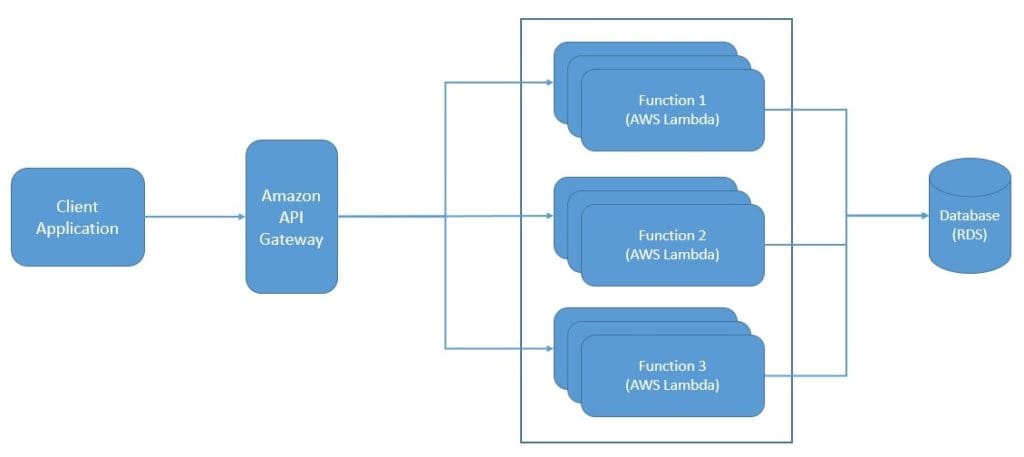
Moreover, with PaaS, we still have to manage some parts of scalability, that we can let go of with FaaS. Further, we expect FaaS to bring up an instance in the event of a new request and destroy it when no longer needed. This is not what is typically effective with bulkier units of deployment like an entire application. Hence, FaaS results in more optimal resource utilization than PaaS.
In the lack of a precise definition for serverless, we should not get hung up on this a lot. The basic idea is to benefit from the cost optimizations that cloud-based services can offer. This is possible by using the compute resources only as much as we need without having to worry about where it comes from! This requires us to redesign our applications into smaller and ephemeral units of deployment.
While the fundamental premise for a serverless architecture is very appealing, it may not be very intuitive to understand how to approach this. Creating an application as a composition of autonomous functions is easier said than done! Let’s spend some time to understand the serverless architecture better and to explore how exactly an application can benefit from it.
For the purpose of this tutorial, we’ll pick a simple application that helps us to manage our tasks. We can imagine this simple application with a three-tier architecture:
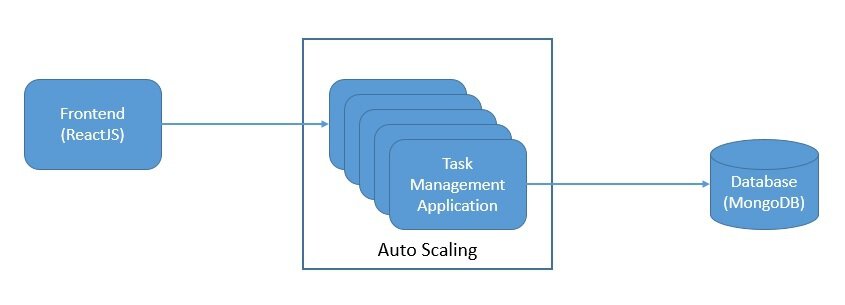
We can develop this application with popular frameworks like ReactJS for the client-side, SpringBoot for the server-side, and MongoDB as the database. Further, we can deploy this on-premise or on the cloud-managed infrastructure. But, even with several options for auto-scaling, we’ll not be able to eliminate the wastage of computing resources.
However, can we bring it down with serverless? Let’s see. First, we’ll have to rearchitect this simple application as a group of independent and autonomous functions:
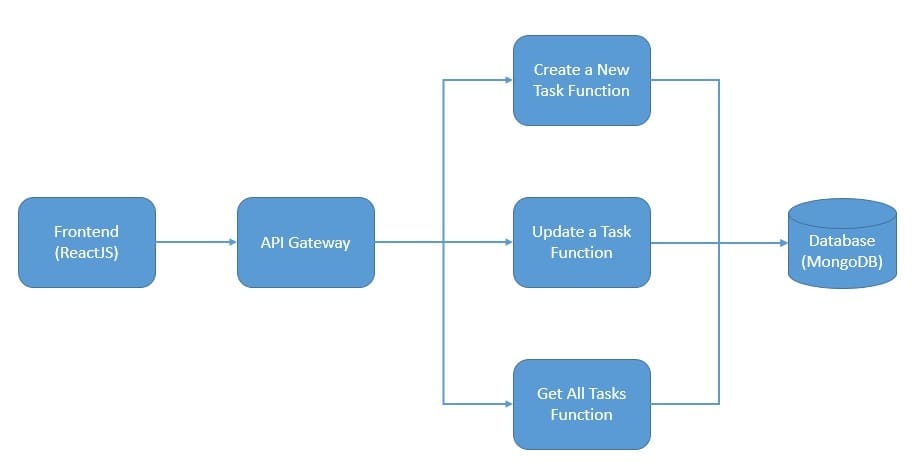
Here we’ve decomposed our simple application into individual functions to work with the tasks. While the functional decomposition is fairly intuitive, what about its technical implications? There are a few worth discussing.
To begin with, we’ve to lean back on the development SDKs and APIs provided by the FaaS service provider for development. Then, we also face challenges with the traditional tools of debugging, monitoring, and managing applications. But, on the positive side, we are able to rely on the native capabilities of the FaaS service provider to create and manage the function instances only as needed.
As we’ve discussed earlier, one of the key advantages of serverless architecture is that we get to delegate all infrastructure management to a third party. Of course, that means that our ability to create a serverless application largely depends on the services available to us. Moreover serverless is not only about a single service but a host of services that enable us to benefit from serverless architecture.
There are quite a few cloud-services vendors available today that boast of a very mature catalog of serverless services. Since we can define serverless in quite a flexible way, the services provided by these vendors are also very distinct. Although there are certain common aspects to them. We will explore some of these services from a few vendors.
The most important service in the catalog of serverless services on AWS is the FaaS service Lambda. AWS Lambda is a serverless compute service that lets us run our code without provisioning or managing servers. It allows us to write the Lambda functions in any of the popular languages like Node.js, Python, Go, and Java. We can simply upload our code as a ZIP file or container image.
Hence, we get to use precise computation power for any scale of traffic. Moreover, AWS provides a host of other services for our serverless application. For instance, Amazon EventBridge for building event-driven applications. Amazon API Gateway to create, publish, maintain, monitor, and secure our APIs. Amazon S3 to store any amount of data with scalability and availability.
Similarly, within the offerings of GCP, Cloud Functions is the key serverless product. Cloud Functions is a scalable pay-as-you-go FaaS to run our code with no server management. It automatically scales our application on the load. Further, it provides integrated monitoring, logging, and debugging. Moreover, it features built-in security at the role and per-function levels.
Another key offering from GCP is the PaaS product App Engine. Cloud Functions is more suitable for simpler, standalone, and event-driven functions. But for more complex applications where we want to combine multiple functionalities, App Engine is a more suitable serverless platform. GCP also offers Cloud Run to deploy serverless applications packaged as containers on a Kubernetes cluster like GKE.
On similar lines, Microsoft Azure offers a FaaS service Azure Functions that provides an event-driven serverless compute platform. We can also solve complex orchestration problems like stateful coordination using the Durable Functions extension. We can connect to a host of other services without any hard coding using triggers and bindings. Moreover, we can run our Functions on Kubernetes as well.
As before, for more complex applications Azure also offers App Service. It allows us to build, deploy, and scale web applications on a fully managed serverless platform. We can create our application using a popular language like Node.js, Java, or Python. Moreover, we can meet rigorous enterprise-grade performance, security, and compliance requirements.
Kubernetes is an open-source orchestration system for automating deployment, scaling, and management of containerized workloads. Moreover, a dedicated infrastructure layer of service mesh like Istio can sit on top of the Kubernetes cluster. This can help us in solving a lot of common problems like service-to-service communication.
It is natural to think about leveraging the combination of Istio on top of Kubernetes to host and manage a serverless environment. There can be a number of benefits of such a deployment model. For instance, it decouples us from many of the vendor-specific services. Moreover, it can provide a standard development framework for serverless applications.
Knative is a Kubernetes-based platform to deploy and manage serverless workloads. It can help us to stand up scalable, secure, and stateless services quite easily. It comes with APIs providing higher-level abstractions for common application use-cases. Moreover, it allows us to plug our own components for logging, monitoring, networking, and service mesh.
Knative is fundamentally composed of two components, Serving and Eventing. Serving allows us to run serverless containers on Kubernetes while it takes care of networking, autoscaling, and version tracking. Eventing provides us with an infrastructure for subscription, delivery, and management of events. This allows us to create serverless applications with event-driven architecture.
Kyma provides us with a platform to extend our applications with serverless functions and microservices on Kubernetes. Basically, it brings together a selection of cloud-native projects together to simplify the creation and management of extensions. The fundamental idea behind Kyma is to extend an existing application by being able to send events and receive callbacks.
Kyma comes with a properly configured, monitored, and secured Kubernetes cluster. Moreover, it provides open-source projects for authentication, logging, eventing, tracing, and other such needs. It comprises several key components that span serverless computing, eventing, observability, API exposure, application connectivity, service mesh, and user interface.
By now, it should be clear that serverless architecture leads to optimal resource consumption. This inherently results in a lower cost for computation. More importantly, since consumer of a serverless platform does not have to worry about the infrastructure, it can result into much lower cost of operations for the consumer.
Readily available and highly scalable serverless platforms further lead to faster time to market and a much better user experience. But, this style of cloud computing architecture may not be suitable for all use-cases and we must be careful in weighing the costs and the benefits. It’s not possible to value serverless completely unless we also understand its drawbacks.
One of the major concerns for serverless architecture is vendor control. When we design or re-design our application with serverless architecture, we are voluntarily losing control of many aspects of our system like which languages we can use and which versions we’ve to upgrade to. Of course, with each passing day, the spectrum of support from each vendor is widening further.
Another very important concern with the serverless architecture is vendor lock-in. As we’ve seen earlier, the serverless services of one vendor can be very different from those of others. This can make it difficult and often costly for us to switch vendors of the serverless platforms if we’ve to. This is primarily as we depend on several infrastructure services from the vendor.
Then there are several other concerns like the security that we’ve to be careful about. When developing applications in the traditional way, we’ve got a lot of control in terms of security. But, soon we start to adopt serverless services, we are exposed to several security implementations specific to the vendor. This adds to the complexity and attack vector for the application.
But, there are certain challenges that are specific to how we develop our application itself. For instance, since the serverless workload is scaled down to zero when not in use, it can suffer from startup latency. The problem is often known as the cold-start and can happen for many reasons. This is particularly true for applications that are occasionally triggered and run on the JVM.
Another very important aspect to be careful about is testing. As serverless emphasizes smaller autonomous applications, unit testing then becomes fairly easier. But what about integration testing? Since the overall application depends on a number of infrastructure services from the vendor, implementing integration tests becomes challenging.
So, where should we actually use the serverless architecture? There is no one good answer for this. However, characteristics in an application that can possibly benefit from serverless architecture are asynchronous, concurrent, infrequent, in sporadic demand, with unpredictable scaling requirements, stateless, ephemeral, and highly dynamic.
In this tutorial, we went through the basics of serverless architecture. We understood how we can take a regular application and transform this to benefit from being serverless. Further, we explored some of the popular serverless platforms available for us. Lastly, we also discussed some of the limitations of serverless architecture.